Tahap 2 ke 3: Dari Pilot ke Scaled, Keluar dari Pilot Purgatory
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
AI pilot Anda berhasil. Para pengguna menyukainya. Angka awalnya menggembirakan. Tim sales development rep menghemat tiga jam seminggu untuk personalisasi email. Reply rate naik 12%. Pemilik pilot mempresentasikan hasilnya. Kepemimpinan mengangguk.
Kemudian seseorang bertanya: "Bagaimana kita men-scale ini?"
Dan tiba-tiba tidak ada yang tahu jawabannya.
Inilah pilot purgatory. Ini adalah ruang antara "pilot berhasil" dan "kami memiliki AI yang berjalan di produksi." Di sinilah sebagian besar organisasi Tahap 2 terjebak, terkadang selama setahun, terkadang lebih lama. Forrester mengidentifikasi use case sprawl sebagai salah satu hambatan terbesar dalam men-scale AI: enterprise sering memiliki lusinan pilot tetapi tidak memiliki kerangka untuk memprioritaskan dan mengaktifkannya. Pilot terbengkalai sementara tim berdebat tentang infrastruktur, menunggu anggaran, berargumen tentang kepemilikan, atau menjalankan pilot lagi karena itu terasa lebih aman daripada komitmen yang dibutuhkan produksi.
Memahami mengapa pilot purgatory terjadi adalah langkah pertama untuk keluar darinya. Jika Anda masih di Tahap 1, baca Tahap 1 ke 2: Dari Ad-Hoc ke Pilot terlebih dahulu.
Seperti apa pilot purgatory itu
Key Facts: Tantangan Pilot-ke-Scale
- Forrester mengidentifikasi use case sprawl sebagai salah satu hambatan terbesar dalam men-scale AI; enterprise sering memiliki lusinan pilot tetapi tidak memiliki kerangka untuk memprioritaskan dan mengaktifkannya ke produksi (Forrester, 2025)
- Organisasi yang telah men-scale AI (Tahap 3+) menghasilkan total shareholder return 3 tahun kira-kira 4x lebih tinggi daripada tertinggal AI; kesenjangan antara pemimpin dan tertinggal melebar setiap tahun keterlambatan di Tahap 2 (BCG, 2025)
- McKinsey menemukan bahwa beralih dari AI pilot yang berhasil ke deployment enterprise-wide membutuhkan adopsi scaling mindset, pendekatan modular dalam membangun aset AI, dan pemendekan siklus pengembangan analitik, persyaratan yang tidak mampu dijalankan oleh sebagian besar tim tahap pilot (McKinsey, 2025)
Pilot purgatory memiliki gejala yang konsisten.
Pilot yang tetap menjadi pilot selama 12+ bulan. Batas waktu yang ditetapkan dalam charter datang dan pergi. Tidak ada yang secara eksplisit memutuskan untuk scale. Tidak ada yang secara eksplisit menghentikan pilot. Pilot terus berjalan pada volume rendah, menghabiskan sejumlah upaya tanpa memberikan nilai skala produksi.
Beberapa alat yang bersaing sedang dievaluasi secara bersamaan. Alih-alih berkomitmen pada satu alat dan men-scale-nya, tim membuka evaluasi dua atau tiga alternatif. "Kami ingin memastikan kami memilih yang tepat." Delapan belas bulan kemudian mereka masih belum memilih satu.
Eksekutif menunggu "satu data point lagi." Pilot menghasilkan hasil yang bagus, tetapi kepemimpinan ingin ukuran sampel yang lebih besar, jangka waktu yang lebih panjang, atau use case yang lebih kompleks sebelum berkomitmen. Standarnya terus bergerak.
Tidak ada keputusan infrastruktur yang dibuat. Pilot berjalan pada pengaturan cloud yang dikelola vendor tanpa komitmen arsitektur dari perusahaan. Scale akan membutuhkan keputusan tentang penyimpanan data, hosting model, kepemilikan API, dan monitoring yang belum dibuat siapapun.
Tim pilot kelelahan. Tiga orang yang sama yang menjalankan pilot diminta untuk menjalankan dua pilot berikutnya sekaligus mencari cara untuk men-scale pilot pertama. Mereka terlalu banyak bekerja, tidak terstruktur, dan mulai tidak bersemangat. Analisis McKinsey menemukan bahwa membuat transisi dari AI pilot yang berhasil ke AI enterprise-wide yang efektif membutuhkan adopsi scaling mindset, pendekatan modular dalam membangun aset AI, dan pemendekan siklus pengembangan analitik, tidak ada yang bisa dilakukan oleh tim tiga orang yang kelelahan.
Jika dua atau lebih dari ini benar, Anda berada di pilot purgatory. Keluarnya membutuhkan disiplin eksekusi, bukan lebih banyak evaluasi.
"Transisi Tahap 2 ke Tahap 3 paling sering gagal bukan karena pilot yang salah, tetapi karena tim memperlakukan production deployment sebagai versi pilot yang lebih besar. Itu bukan begitu. Produksi membutuhkan komitmen infrastruktur, change management melampaui sukarelawan, cost governance, dan pemilik AI Operations yang ditunjuk. Perusahaan yang menjalankan Tahap 3 dengan infrastruktur Tahap 2 menghadapi insiden, kejutan biaya, dan keruntuhan adopsi." (Rework)
Stage 2-to-3 Crossing Test
Diagnostik empat persyaratan yang mengkonfirmasi bahwa sebuah organisasi telah benar-benar melintasi dari Tahap 2 ke Tahap 3, bukan sekadar memberi label ulang pada pilot yang di-scale sebagai produksi. Persyaratan 1: Satu use case di-deploy ke semua pengguna yang dituju (bukan kelompok sukarelawan), dengan monitoring aktif. Persyaratan 2: Keputusan infrastruktur bersama terdokumentasi dan berkomitmen (model provider, vector database, observability stack), bukan ad-hoc per use case. Persyaratan 3: Use case kedua dalam pilot aktif menggunakan infrastruktur Persyaratan 2 sebagai fondasinya. Persyaratan 4: Pemilik AI Operations yang ditunjuk ada dengan akuntabilitas eksplisit untuk uptime sistem produksi, insiden, dan versioning model. Organisasi yang hanya memenuhi Persyaratan 1 menjalankan pilot yang di-scale, bukan deployment Tahap 3.
Kriteria keluar Tahap 3
Tahap 3 bukan sekadar "lebih banyak pilot." Ini adalah postur operasi yang secara kualitatif berbeda. Berikut yang harus benar untuk mengklaimnya.
| Persyaratan | Artinya | Celah umum |
|---|---|---|
| Satu use case dalam produksi | Di-deploy ke semua pengguna yang dituju, bukan kelompok sukarelawan. Rollout penuh dengan monitoring di tempat. | Masih berjalan pada skala pilot hanya untuk pengguna "yang tepat" |
| Keputusan infrastruktur bersama telah dibuat | Vector database, model provider, guardrail tooling, dan observability stack: dipilih dan berkomitmen | Masih menggunakan infrastruktur ad-hoc pilot. Setiap use case berjalan pada vendor stack yang terpisah. |
| Use case kedua dalam pilot aktif | Bukti bahwa pembelajaran dari Pilot 1 berpindah ke Pilot 2. Bukan hanya direncanakan: sedang berjalan. | Semua energi untuk men-scale Pilot 1. Tidak ada kapasitas untuk use case baru. |
| Kepemilikan AI Operations | Individu atau tim kecil yang ditunjuk bertanggung jawab atas sistem AI produksi: uptime, respons insiden, versioning model | Pemilik pilot masih menjalankan produksi bersamaan dengan pekerjaan utama mereka |
Keempat persyaratan ini harus benar sebelum menyebut organisasi sebagai Tahap 3. Yang paling sering dilewatkan adalah infrastruktur bersama. Itu juga yang menyebabkan masalah paling mahal jika dilewatkan.
Keputusan infrastruktur yang dibutuhkan Tahap 3
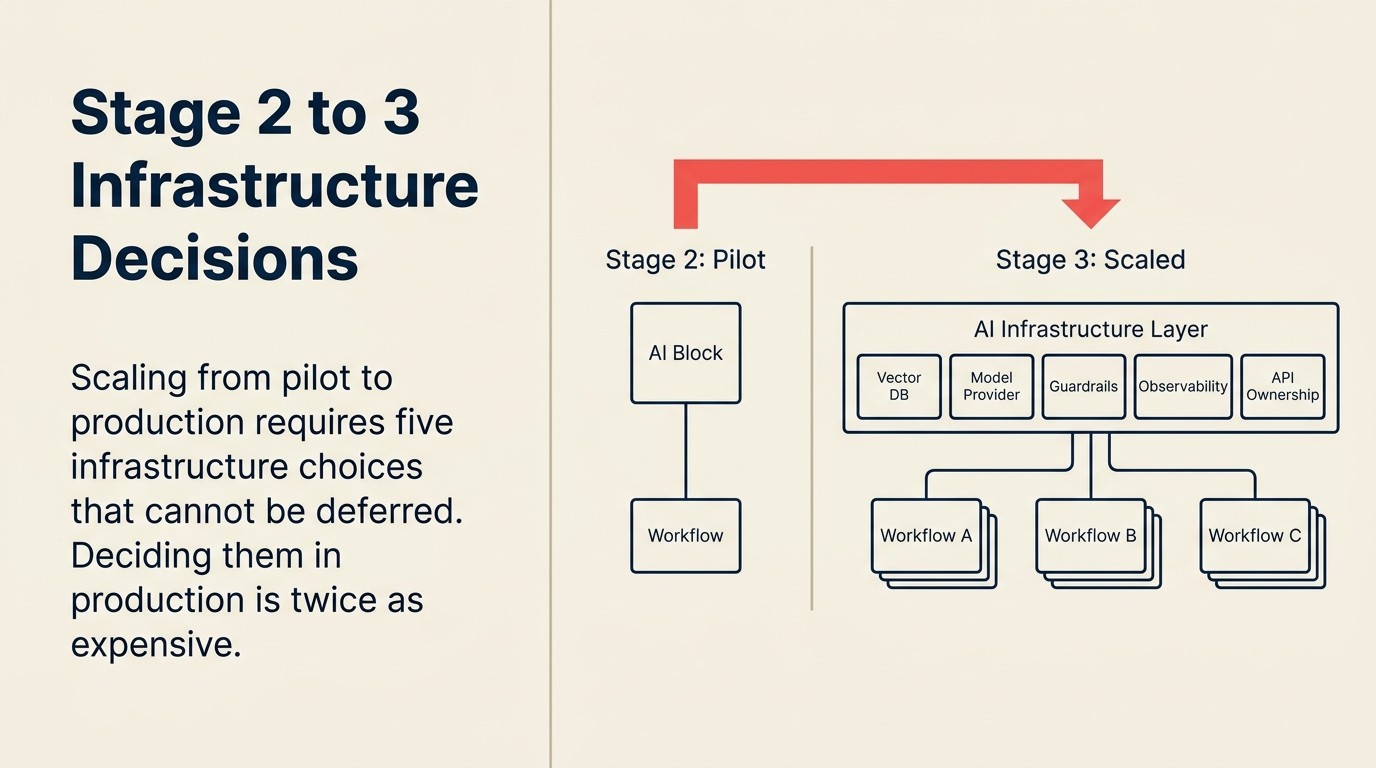
Inilah bagian yang mengejutkan sebagian besar pemimpin transformation yang berasal dari latar belakang pembelian software-as-a-service. AI pada skala produksi membutuhkan komitmen arsitektur yang tidak berlaku untuk alat SaaS biasa. Anda perlu membuat keputusan ini sebelum scale, bukan setelahnya.
Pemilihan vector database. Jika aplikasi AI Anda melibatkan retrieval-augmented generation (RAG), pencarian dokumen internal, atau memori antar interaksi, Anda memerlukan vector database. Opsi utama pada 2026 adalah Pinecone, Weaviate, Qdrant, dan pgvector (untuk tim yang sudah menggunakan PostgreSQL). Pilihan lebih tidak penting daripada membuatnya. Menjalankan use case berbeda pada vector store yang berbeda menciptakan fragmentasi yang mahal untuk diurai.
Keputusan model provider. LLM provider mana yang Anda standarisasikan? OpenAI, Anthropic, Google, atau campuran? Enterprise agreement memiliki harga, persyaratan penanganan data, dan karakteristik performa yang berbeda. Menggunakan paket gratis ChatGPT untuk pilot sudah cukup. Beban kerja produksi membutuhkan enterprise agreement yang tepat dengan data processing agreements (DPAs) dan komitmen SLA.
Guardrail tooling. Bagaimana Anda mencegah AI menghasilkan output yang berbahaya, tidak akurat, atau tidak sesuai brand dalam skala besar? Pada skala pilot, seorang manusia meninjau setiap output. Pada skala produksi, itu tidak mungkin. Guardrails berjalan sebagai layer pra-dan pasca-pemrosesan di sekitar pemanggilan model. Opsi berkisar dari rekayasa prompt khusus hingga alat yang dibuat untuk tujuan ini seperti Guardrails AI atau lapisan keamanan LlamaIndex.
Observability stack. Bagaimana Anda tahu kapan AI Anda rusak? Pada skala pilot, pemilik pilot memperhatikan. Pada skala produksi, Anda membutuhkan logging, alerting, dan dashboard. Metrik mana yang penting: response latency, error rate, fallback rate, pemicu tinjauan manusia. Ini adalah satu komponen infrastruktur yang paling sering ditemukan tim hanya setelah insiden produksi.
Kepemilikan API dan rate limits. Siapa yang memiliki API key untuk model provider Anda? Pada skala pilot: mungkin orang yang menyiapkan pilot. Pada skala produksi: service account yang dimiliki IT, dengan rate limits yang ditetapkan untuk mencegah lonjakan biaya dan dengan kebijakan rotasi untuk keamanan.
Ini bukan keputusan IT secara terpisah. Ini adalah komitmen arsitektur yang memengaruhi setiap use case AI yang akan Anda bangun setelahnya. Membuat keputusan ini secara bersama, sebelum scale, menghemat berbulan-bulan pekerjaan ulang.
Checklist deployment produksi

"Kami akan memasukkan ini ke produksi" berarti hal yang berbeda bagi tim yang berbeda. Untuk sistem AI, produksi memiliki arti yang spesifik. Delapan hal ini perlu benar.
1. Monitoring aktif. Bukan "kami akan memeriksanya sesekali." Monitoring aktif dengan alert untuk lonjakan error rate, degradasi latency, dan pola output yang tidak biasa.
2. Fallback logic ada. Ketika AI gagal (timeout model, pemicu guardrail, rate limit), apa yang terjadi? Pengguna tidak boleh melihat layar kosong atau pesan error mentah. Tentukan fallback: tampilkan output yang di-cache, antrikan untuk tinjauan manusia, tolak dengan baik.
3. Human-in-the-loop gates terdefinisi. Output mana yang memerlukan tinjauan manusia sebelum tindakan? Untuk komunikasi eksternal yang di-draft AI, tentukan apakah manusia meninjau sebelum mengirim (wajib) atau setelah mengirim (terlambat). Tetapkan aturan ini sebelum go-live.
4. Model versioning dilacak. Ketika model provider memperbarui model mereka, output Anda mungkin berubah. Anda membutuhkan catatan versi model mana yang berjalan kapan, sehingga Anda dapat mendiagnosis perubahan output yang tidak dapat dijelaskan.
5. Incident response ada. Jika AI mengirim informasi yang salah ke pelanggan, siapa yang Anda hubungi? Dalam urutan apa? Apa SLA untuk resolusi? Tulis runbook sebelum Anda membutuhkannya.
6. Komunikasi pengguna selesai. Semua pengguna yang dituju mengetahui AI berjalan dalam produksi, memahami apa yang dilakukannya, dan telah dilatih tentang cara meninjau, mengoreksi, dan mengeskalasinya.
7. Cost monitoring aktif. Beban kerja AI produksi dapat menghasilkan lonjakan biaya yang tidak terduga. Konsumsi token, volume pemanggilan API, dan pemilihan model semuanya memengaruhi biaya. Seseorang memiliki laporan biaya bulanan.
8. Data processing agreements telah ditandatangani. Jika AI memproses data pribadi atau data rahasia perusahaan, DPA vendor Anda harus ada sebelum produksi. "Kami akan menambahkan DPA setelah kami scale" adalah pelanggaran compliance, bukan item backlog.
Checklist ini adalah perbedaan antara "di-deploy" dan "produksi." Sebagian besar tim mencapai 5 dari 8. Tiga yang mereka lewatkan adalah yang menyebabkan insiden.
Change management scale: dari sukarelawan ke semua orang
Pilot berjalan pada sukarelawan. Orang-orang dalam kelompok pilot Anda mengangkat tangan. Mereka penasaran tentang AI, bersedia bereksperimen, dan toleran terhadap ketidaksempurnaan. Mereka bukan sampel representatif dari populasi pengguna penuh Anda.
Skala produksi melibatkan semua orang. Dan semua orang termasuk para skeptis, yang memiliki keterbatasan waktu, yang berpikir "ini terasa seperti lebih banyak pekerjaan bukan lebih sedikit," dan yang diam-diam khawatir bahwa jika AI melakukan pekerjaan mereka dengan baik, mereka tidak akan memiliki pekerjaan.
Di sinilah transisi Tahap 2 ke Tahap 3 paling sering terhenti. Pilot berhasil pada 20 sales development rep yang sukarela. Tim penuh memiliki 80 SDR, termasuk 30 yang telah melakukan pekerjaan ini selama lima tahun dan tidak antusias mengubah workflow mereka.
Change management playbook untuk Tahap 3 memiliki empat bagian.
Latih untuk workflow baru, bukan alat. Karyawan menolak alat. Mereka menerima peningkatan workflow. Jangan jalankan "pelatihan alat AI." Jalankan "walkthrough workflow SDR baru" yang kebetulan mencakup alat AI. Tunjukkan sebelum dan sesudah. Buat penghematan waktu terlihat.
Beri para skeptis cara yang aman untuk masuk. Jangan wajibkan AI sebagai satu-satunya jalan. Biarkan skeptis menggunakannya secara opsional pada awalnya. Bukti sosial dari kolega yang mendapatkan hasil lebih baik lebih persuasif daripada mandat eksekutif.
Tangani ketakutan secara langsung. Jika Anda tidak menyebutkan kekhawatiran "apakah ini akan menggantikan saya?" secara eksplisit, itu akan mendominasi setiap percakapan informal tentang rollout. Sebutkan dalam all-hands. Gambarkan evolusi peran: apa yang ditangani AI, apa yang dilakukan manusia yang tidak bisa dilakukan AI. Jadilah spesifik. Ketidakjelasan memperburuk ketakutan.
Ukur adopsi, bukan hanya hasil. Berapa banyak pengguna yang sebenarnya menggunakan workflow AI setiap hari? Setiap minggu? Sama sekali tidak? Lacak adopsi seserius Anda melacak hasil bisnis. Adopsi yang rendah menjelaskan hasil yang kurang baik, dan itu bisa diperbaiki jika Anda menangkapnya lebih awal.
Governance di Tahap 3: dari draft ke fungsi
Di Tahap 2, Anda memiliki kebijakan minimum viable. Di Tahap 3, Anda memiliki AI yang berjalan dalam produksi di beberapa use case. Persyaratan governance berkembang sesuai.
Fungsi persetujuan alat. Seseorang meninjau permintaan alat AI baru, menerapkan kerangka klasifikasi data, dan mengeluarkan persetujuan. Bukan komite. Seorang orang dengan proses dan turnaround time.
Kepemilikan insiden. Ketika insiden AI produksi terjadi (output yang salah, eksposur data, kegagalan model), siapa yang memiliki resolusi? Di Tahap 3, ini adalah peran yang ditunjuk: AI Operations lead atau setara. Bukan daftar email bersama.
Tinjauan kebijakan kuartalan. AI bergerak cepat. Daftar alat yang disetujui dari enam bulan lalu mungkin mencakup alat yang telah mengubah persyaratan penanganan data mereka. Buat acara kalender: tinjauan kuartalan, dua jam, daftar alat yang disetujui ditambah log insiden.
Baseline audit trail. Untuk setiap workflow AI yang memiliki kemampuan Execute (AI mengambil tindakan dalam sistem), Anda membutuhkan log tentang apa yang dilakukan AI, kapan, dan dengan hasil apa. Ini adalah persyaratan hukum dan compliance pada skala produksi di sebagian besar yurisdiksi, dan ini adalah fondasi untuk pemecahan masalah ketika sesuatu berjalan salah. Lihat Audit Trails untuk AI Execute Actions untuk apa yang dibutuhkan audit trail berkelas produksi.
Analisis Rework: Berdasarkan pola deployment AI enterprise, tiga keputusan infrastruktur yang paling sering ditunda hingga setelah insiden produksi adalah: observability stack (tim menyadari mereka membutuhkannya ketika mereka tidak dapat mendiagnosis mengapa output terdegradasi), data processing agreements dengan model provider (ditangani pasca-deployment ketika legal menandai celah compliance), dan cost monitoring (terungkap ketika invoice kejutan pertama tiba). Ketiganya tidak mahal untuk diimplementasikan sebelum produksi. Ketiganya mahal untuk dipasang kembali setelah insiden. Checklist deployment produksi dalam artikel ini secara khusus diurutkan untuk memastikan ketiganya ditangani sebelum go-live.
Perhitungan ulang ROI di Tahap 3
Pilot membuktikan kelayakan. Produksi membuktikan ekonomi. Ini adalah pertanyaan yang berbeda.
Pilot dengan 20 pengguna selama 60 hari yang menghemat 3 jam per pengguna per minggu terlihat seperti ini dalam istilah tahunan: 20 pengguna x 3 jam x 48 minggu = 2.880 jam yang dihemat. Dengan biaya penuh rata-rata $50/jam, itu adalah nilai tenaga kerja tahunan sebesar $144.000.
Tapi berapa biaya sebenarnya untuk menjalankan AI itu dalam produksi? Biaya model API, waktu tim AI Operations, biaya infrastruktur, overhead monitoring. Jika total biaya kepemilikan tahunan adalah $40.000, return on investment adalah $104.000 bersih. Itu adalah business case yang jelas.
Jalankan perhitungan ini sebelum komitmen scaling Tahap 3 Anda. Dan gunakan angka nyata, bukan harga skala pilot vendor. Tanyakan kepada model provider Anda untuk harga produksi pada volume token yang Anda harapkan. Tanyakan berapa biaya rekrutan AI Operations Anda. Tambahkan 20% untuk overhead yang belum Anda antisipasi.
Contoh nyata Tahap 2 ke 3
Sebuah perusahaan SaaS dengan 200 karyawan menjalankan pilot yang berhasil dengan AI Support Agent pada Q3 2025. Pilot menunjukkan bahwa AI dapat menyelesaikan 35% tiket support masuk tanpa keterlibatan manusia, membebaskan 15 jam per minggu per support engineer.
Sebelum scaling, mereka membuat tiga keputusan infrastruktur: standarisasi pada OpenAI Enterprise untuk model provider mereka, berkomitmen pada Pinecone sebagai vector database untuk knowledge base support, dan men-deploy LangSmith untuk observabilitas.
Mereka mempekerjakan AI Operations Lead pada Q4 2025. Orang itu memiliki checklist deployment produksi, menjalankan pelatihan pengguna, menulis runbook insiden, dan menyiapkan dashboard cost monitoring.
Pada Q1 2026, AI Support Agent berjalan dalam produksi untuk seluruh tim support. Secara paralel, mereka meluncurkan Pilot 2: asisten AI Sales Operations yang men-draft ringkasan panggilan dan rekomendasi langkah berikutnya langsung di CRM. Pilot itu berjalan sekarang, dengan infrastruktur Pilot 1 sebagai fondasinya.
Mereka tidak menjalankan lima pilot secara paralel. Mereka menjalankan satu dengan baik, berkomitmen pada infrastruktur, dan menggunakan fondasi itu untuk yang berikutnya. Itulah transisi Tahap 2 ke Tahap 3 yang dilakukan dengan benar.
Apa yang akan datang
Production deployment adalah Tahap 3. Perpindahan ke Tahap 4 adalah urutan besaran yang berbeda: AI bukan sebagai lapisan di atas workflow Anda, tetapi terjalin ke dalam model operasi inti Anda. Sebagian besar perusahaan mid-market tidak akan siap untuk Tahap 4 selama dua hingga tiga tahun lagi.
Namun memahami apa yang dibutuhkan Tahap 4 membantu Anda berinvestasi dengan benar di Tahap 3. Anda tidak hanya men-scale alat. Anda membangun infrastruktur dan governance yang bergantung pada Tahap 4. Investasi itu berbunga ke depan.
Baca: Tahap 3 ke 4: Dari Scaled ke Integrated untuk persyaratan organisasi dan arsitektur.
Baca: 5 Tahap Kematangan AI untuk melihat model kematangan penuh dan di mana Tahap 3 berada.
Baca: AI Incident Response Playbook sebelum deployment produksi pertama Anda. Anda akan menginginkannya siap sebelum Anda membutuhkannya.
Lihat juga:
- Biaya Nyata AI Transformation: investasi infrastruktur yang dibutuhkan di Tahap 3 yang dimodelkan terhadap business case
- Sequencing AI Patterns dalam Multi-Year Roadmap: cara memprioritaskan use case kedua dan ketiga Anda setelah Pilot 1 berhasil

Co-Founder, Rework.com
On this page
- Seperti apa pilot purgatory itu
- Stage 2-to-3 Crossing Test
- Kriteria keluar Tahap 3
- Keputusan infrastruktur yang dibutuhkan Tahap 3
- Checklist deployment produksi
- Change management scale: dari sukarelawan ke semua orang
- Governance di Tahap 3: dari draft ke fungsi
- Perhitungan ulang ROI di Tahap 3
- Contoh nyata Tahap 2 ke 3
- Apa yang akan datang