Etapa 2 para 3: Do Piloto para o Escalado, Escapando do Purgatório de Pilotos
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Seu piloto de AI funcionou. Os usuários gostam. Os números iniciais são encorajadores. A equipe de SDRs está economizando três horas por semana em personalização de e-mail. As taxas de resposta subiram 12%. O responsável pelo piloto apresenta os resultados. A liderança concorda.
Então alguém pergunta: "Como escalamos isso?"
E de repente ninguém sabe a resposta.
Esse é o purgatório de pilotos. É o espaço entre "o piloto funcionou" e "temos AI rodando em produção". É onde a maioria das organizações na Etapa 2 fica presa, às vezes por um ano, às vezes mais. A Forrester identifica o espalhamento de casos de uso como uma das maiores barreiras para escalar AI: empresas geralmente têm dezenas de pilotos, mas carecem de um framework para priorizá-los e ativá-los. O piloto fica em limbo enquanto a equipe debate infraestrutura, aguarda budget, discute sobre propriedade ou simplesmente roda outro piloto porque isso parece mais seguro do que o compromisso que a produção exige.
Entender por que o purgatório de pilotos acontece é o primeiro passo para escapar dele. Se você ainda está na Etapa 1, leia primeiro Etapa 1 para 2: De Ad-Hoc para Piloto.
O que parece o purgatório de pilotos
Fatos Essenciais: Desafios do Piloto para a Escala
- A Forrester identifica o espalhamento de casos de uso como uma das maiores barreiras para escalar AI; empresas geralmente têm dezenas de pilotos, mas carecem de um framework para priorizá-los e ativá-los para produção (Forrester, 2025)
- Organizações que escalaram AI (Etapa 3 ou mais) geram retornos totais para acionistas em 3 anos aproximadamente 4 vezes maiores do que os retardatários em AI; a lacuna entre líderes e retardatários se amplia a cada ano de atraso na Etapa 2 (BCG, 2025)
- A McKinsey descobriu que mover de pilotos de AI bem-sucedidos para implantação em toda a empresa requer adotar uma mentalidade de escala, adotar uma abordagem modular para construir ativos de AI e encurtar o ciclo de vida de desenvolvimento de analytics, requisitos para os quais a maioria das equipes em fase de piloto não está estruturada para executar (McKinsey, 2025)
O purgatório de pilotos tem sintomas consistentes.
Pilotos que ficam em piloto por 12 ou mais meses. O limite de tempo definido no charter vai e vem. Ninguém decide explicitamente escalar. Ninguém encerra explicitamente o piloto. Ele apenas continua rodando em baixo volume, consumindo algum esforço sem entregar valor em escala de produção.
Múltiplas ferramentas concorrentes sendo avaliadas simultaneamente. Em vez de se comprometer com uma ferramenta e escalá-la, a equipe abre avaliações de duas ou três alternativas. "Queremos ter certeza de que escolhemos a certa." Dezoito meses depois, ainda não escolheram nenhuma.
Executivos esperando "mais um ponto de dados". O piloto produziu bons resultados, mas a liderança quer uma amostra maior, uma janela de tempo mais longa ou um caso de uso mais complexo antes de se comprometer. O critério continua mudando.
Nenhuma decisão de infraestrutura tomada. O piloto rodou em uma configuração de nuvem gerenciada pelo fornecedor sem compromissos arquitetônicos da empresa. Escalar exigiria decisões sobre armazenamento de dados, hospedagem de modelos, propriedade de API e monitoramento que ninguém tomou ainda.
A equipe do piloto está esgotada. As mesmas três pessoas que rodaram o piloto estão sendo solicitadas a rodar os próximos dois pilotos enquanto também descobrem como escalar o primeiro. Estão sobrecarregadas, sem estrutura e começando a se desengajar. A análise da McKinsey descobriu que fazer a transição de pilotos de AI bem-sucedidos para AI corporativa efetiva requer adotar uma mentalidade de escala, uma abordagem modular para construir ativos de AI e encurtar o ciclo de vida de desenvolvimento de analytics, algo que uma equipe exausta de três pessoas não consegue fazer.
Se dois ou mais desses são verdadeiros, você está no purgatório de pilotos. A saída exige disciplina de execução, não mais avaliação.
"A transição da Etapa 2 para a Etapa 3 falha com mais frequência não porque o piloto estava errado, mas porque a equipe trata a implantação em produção como uma versão maior do piloto. Não é. Produção exige compromissos de infraestrutura, gestão de mudanças além dos voluntários, governança de custos e um responsável nomeado por AI Operations. Empresas que rodam a Etapa 3 com infraestrutura da Etapa 2 enfrentam incidentes, surpresas de custo e colapso de adoção." (Rework)
O Teste de Travessia da Etapa 2 para a Etapa 3
Um diagnóstico de quatro requisitos confirmando que uma organização genuinamente cruzou da Etapa 2 para a Etapa 3, em vez de apenas renomear um piloto escalado como produção. Requisito 1: Um caso de uso está implantado para todos os usuários pretendidos (não um grupo de voluntários), com monitoramento ativo. Requisito 2: Decisões de infraestrutura compartilhada estão documentadas e comprometidas (provedor de modelo, banco de dados vetorial, stack de observabilidade), não ad-hoc por caso de uso. Requisito 3: Um segundo caso de uso está em piloto ativo usando a infraestrutura do Requisito 2 como fundação. Requisito 4: Existe um responsável por AI Operations nomeado com responsabilidade explícita por uptime do sistema de produção, incidentes e versionamento de modelos. Organizações que atendem apenas ao Requisito 1 estão rodando um piloto escalado, não uma implantação da Etapa 3.
Critérios de saída da Etapa 3
A Etapa 3 não é apenas "mais pilotos". É uma postura operacional qualitativamente diferente. Veja o que deve ser verdadeiro para reivindicá-la.
| Requisito | O que significa | Lacuna comum |
|---|---|---|
| Um caso de uso em produção | Implantado para todos os usuários pretendidos, não um grupo de voluntários. Implantação completa com monitoramento ativo. | Ainda rodando em escala de piloto apenas para os usuários "certos" |
| Decisões de infraestrutura compartilhada tomadas | Banco de dados vetorial, provedor de modelo, ferramentas de guardrail e stack de observabilidade: selecionados e comprometidos | Ainda usando infraestrutura ad-hoc do piloto. Cada caso de uso rodando em stacks de fornecedores separados. |
| Um segundo caso de uso em piloto ativo | Prova de que o aprendizado do Piloto 1 foi transferido para o Piloto 2. Não apenas planejado: em execução. | Toda energia foi para escalar o Piloto 1. Sem capacidade para novos casos de uso. |
| Propriedade de AI Operations | Indivíduo ou pequena equipe responsável pelos sistemas de AI em produção: uptime, resposta a incidentes, versionamento de modelos | O responsável pelo piloto ainda gerencia a produção junto com seu trabalho principal |
Todos os quatro requisitos devem ser verdadeiros antes de chamar a organização de Etapa 3. O mais frequentemente ignorado é a infraestrutura compartilhada. É também o que causa os problemas mais dispendiosos quando ignorado.
As decisões de infraestrutura que a Etapa 3 exige
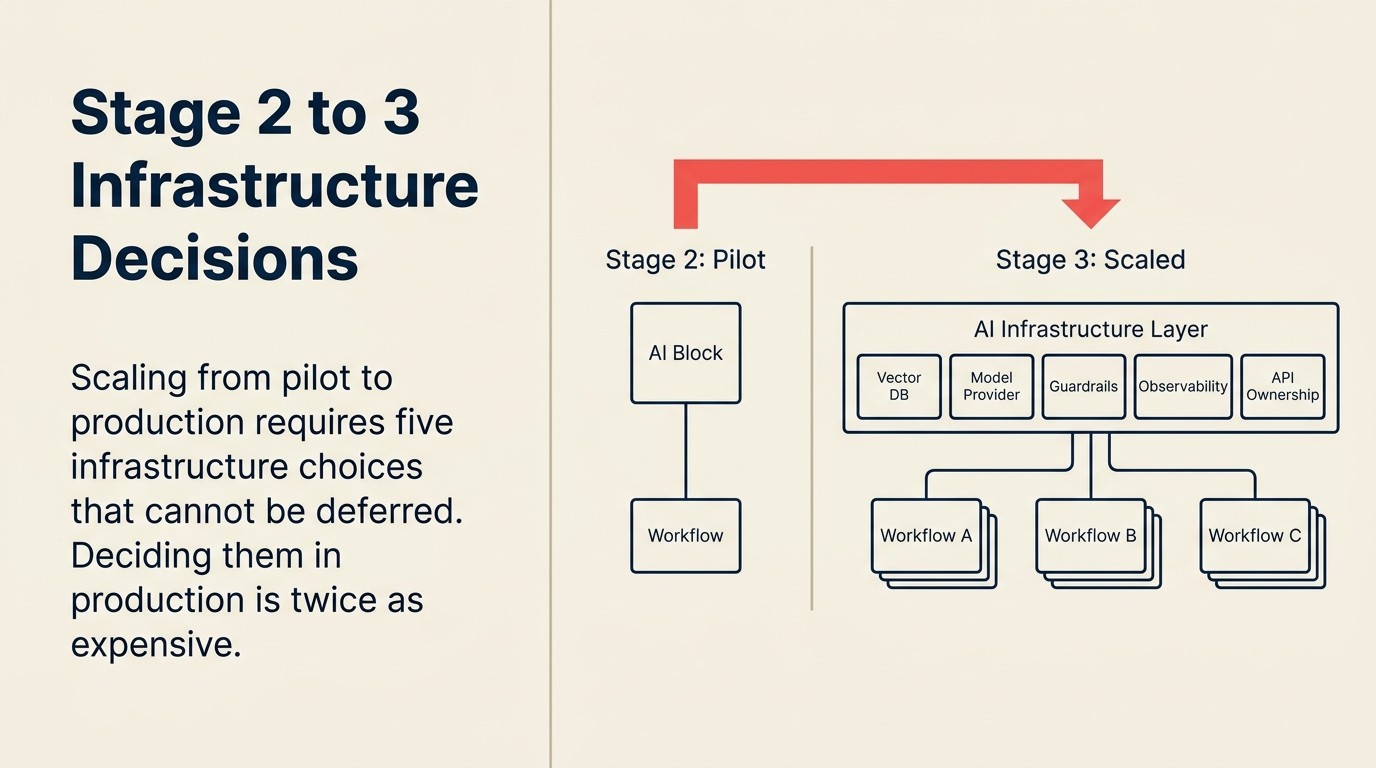
Esta é a parte que surpreende a maioria dos líderes de transformação com background em compra de SaaS. AI em escala de produção exige compromissos arquitetônicos que não se aplicam a ferramentas SaaS comuns. Você precisa tomar essas decisões antes de escalar, não depois.
Escolha do banco de dados vetorial. Se suas aplicações de AI envolvem geração aumentada por recuperação (RAG), pesquisa de documentos internos ou memória entre interações, você precisa de um banco de dados vetorial. As principais opções em 2026 são Pinecone, Weaviate, Qdrant e pgvector (para equipes já no PostgreSQL). A escolha importa menos do que tomá-la. Rodar diferentes casos de uso em diferentes armazenamentos vetoriais cria fragmentação cara de desfazer.
Decisões sobre o provedor de modelos. Em quais provedores de LLM (large language model) você está padronizando? OpenAI, Anthropic, Google ou uma combinação? Os contratos empresariais têm preços, termos de tratamento de dados e características de desempenho diferentes. Usar a versão gratuita do ChatGPT para pilotos é aceitável. Cargas de trabalho em produção precisam de contratos empresariais adequados com DPAs (data processing agreements) e compromissos de SLA.
Ferramentas de guardrail. Como você impede que a AI produza outputs prejudiciais, incorretos ou fora do padrão da marca em escala? Na fase de piloto, um humano revisa cada output. Em escala de produção, isso não é possível. Os guardrails rodam como camadas de pré e pós-processamento em torno das chamadas de modelo. As opções vão desde engenharia de prompt personalizada até ferramentas específicas como Guardrails AI ou as camadas de segurança do LlamaIndex.
Stack de observabilidade. Como você sabe quando sua AI está com problemas? Na escala de piloto, o responsável pelo piloto percebe. Em escala de produção, você precisa de logging, alertas e dashboards. Quais métricas importam: latência de resposta, taxa de erros, taxa de fallback, gatilhos de revisão humana. Este é o componente de infraestrutura que a maioria das equipes descobre que precisa apenas após um incidente de produção.
Propriedade de API e limites de taxa. Quem é dono das chaves de API dos seus provedores de modelo? Na fase de piloto: provavelmente a pessoa que configurou o piloto. Em escala de produção: uma conta de serviço gerenciada pela TI, com limites de taxa definidos para evitar picos de custo e com políticas de rotação para segurança.
Essas não são decisões de TI de forma isolada. São compromissos arquitetônicos que afetam cada caso de uso de AI que você construirá depois. Tomá-las em conjunto, antes de escalar, economiza meses de retrabalho.
O checklist de implantação em produção

"Vamos colocar isso em produção" significa coisas diferentes para equipes diferentes. Para sistemas de AI, produção tem um significado específico. Essas oito coisas precisam ser verdadeiras.
1. O monitoramento está ativo. Não "verificaremos ocasionalmente". Monitoramento ativo com alertas para picos de taxa de erros, degradação de latência e padrões incomuns de output.
2. A lógica de fallback existe. Quando a AI falha (timeout do modelo, gatilho de guardrail, limite de taxa), o que acontece? O usuário não pode ver uma tela em branco ou uma mensagem de erro bruta. Defina o fallback: mostrar output em cache, enfileirar para revisão humana, declinar com elegância.
3. Os portões humanos no fluxo estão definidos. Quais outputs exigem revisão humana antes da ação? Para comunicações externas elaboradas por AI, defina se o humano revisa antes de enviar (obrigatório) ou depois de enviar (tarde demais). Defina essa regra antes do lançamento.
4. O versionamento de modelos é rastreado. Quando o provedor de modelos atualiza seu modelo, seus outputs podem mudar. Você precisa de um registro de qual versão do modelo estava rodando quando, para poder diagnosticar mudanças inexplicadas de output.
5. A resposta a incidentes existe. Se a AI enviar informações erradas a um cliente, quem você chama? Em que ordem? Qual é o SLA para resolução? Escreva o runbook antes de precisar dele.
6. A comunicação com usuários foi feita. Todos os usuários pretendidos sabem que a AI está rodando em produção, entendem o que ela faz e foram treinados em como revisar, corrigir e escalar os outputs.
7. O monitoramento de custos está ativo. Cargas de trabalho de AI em produção podem gerar picos de custo inesperados. Consumo de tokens, volume de chamadas de API e seleção de modelo afetam o custo. Alguém é responsável pelo relatório mensal de custos.
8. Os data processing agreements estão assinados. Se a AI processa dados pessoais ou dados confidenciais da empresa, o DPA do seu fornecedor deve estar em vigor antes da produção. "Vamos adicionar o DPA depois de escalar" é uma violação de conformidade, não um item de backlog.
Este checklist é a diferença entre "implantado" e "em produção". A maioria das equipes acerta 5 dos 8. Os três que ignoram são os que causam incidentes.
Gestão de mudanças na escala: dos voluntários para todos
Pilotos rodam com voluntários. As pessoas no seu grupo de piloto se candidataram. Estavam curiosas sobre AI, dispostas a experimentar e tolerantes com imperfeições. Não são uma amostra representativa de toda a sua população de usuários.
A escala de produção envolve todos. E todos incluem os céticos, os que têm pouco tempo, os "isso parece mais trabalho, não menos" e os que estão quietamente preocupados que se a AI fizer bem o trabalho deles, eles não terão mais trabalho.
É aqui que as transições da Etapa 2 para a Etapa 3 mais comumente estancam. O piloto funcionou com 20 SDRs que se voluntariaram. A equipe completa tem 80 SDRs, incluindo 30 que fazem esse trabalho há cinco anos e não estão entusiasmados em mudar seu workflow.
O playbook de gestão de mudanças para a Etapa 3 tem quatro partes.
Treine para o novo workflow, não para a ferramenta. Funcionários resistem a ferramentas. Aceitam melhorias de workflow. Não faça "treinamento de ferramenta de AI". Faça "apresentação do novo workflow de SDR" que por acaso inclui a ferramenta de AI. Mostre o antes e o depois. Torne a economia de tempo visível.
Dê aos céticos uma entrada segura. Não exija a AI como único caminho. Deixe os céticos usá-la opcionalmente no início. A prova social de colegas obtendo melhores resultados é mais persuasiva do que um mandato executivo.
Aborde o medo diretamente. Se você não nomear explicitamente a preocupação "isso vai me substituir?", ela dominará cada conversa informal sobre o lançamento. Nomeie-a na reunião geral. Descreva a evolução do papel: o que a AI faz, o que os humanos fazem que a AI não consegue. Seja específico. A vagueza piora o medo.
Meça a adoção, não apenas os resultados. Quantos usuários estão realmente usando o workflow de AI diariamente? Semanalmente? De forma alguma? Rastreie a adoção tão seriamente quanto rastreia os resultados de negócio. Baixa adoção explica resultados abaixo do esperado, e é corrigível se detectada cedo.
Governança na Etapa 3: do rascunho para a função
Na Etapa 2, você tinha uma política mínima viável. Na Etapa 3, você tem AI rodando em produção em múltiplos casos de uso. Os requisitos de governança se expandem de acordo.
Função de aprovação de ferramentas. Alguém revisa solicitações de novas ferramentas de AI, aplica o framework de classificação de dados e emite aprovações. Não um comitê. Uma pessoa com um processo e um prazo de resposta.
Propriedade de incidentes. Quando ocorre um incidente de AI em produção (output incorreto, exposição de dados, falha de modelo), quem é responsável pela resolução? Na Etapa 3, este é um papel nomeado: líder de AI Operations ou equivalente. Não uma lista de e-mail compartilhada.
Revisão trimestral de política. AI avança rapidamente. Sua lista de ferramentas aprovadas de seis meses atrás pode incluir ferramentas que mudaram seus termos de tratamento de dados. Crie um evento de calendário: revisão trimestral, duas horas, lista de ferramentas aprovadas mais registro de incidentes.
Baseline de trilha de auditoria. Para cada workflow de AI com capacidade Execute (AI tomando ações em sistemas), você precisa de um log do que a AI fez, quando e com qual resultado. Este é um requisito legal e de conformidade em escala de produção na maioria das jurisdições, e é a base para solucionar problemas quando algo der errado. Veja Trilhas de Auditoria para Ações Execute de AI para o que uma trilha de auditoria de nível de produção exige.
Análise Rework: Com base em padrões de implantação de AI corporativa, as três decisões de infraestrutura que mais frequentemente são adiadas até após um incidente de produção são: stack de observabilidade (as equipes descobrem que precisam dele quando não conseguem diagnosticar por que os outputs degradaram), DPAs com provedores de modelos (abordados após implantação quando o Jurídico sinaliza a lacuna de conformidade) e monitoramento de custos (revelado quando a primeira fatura surpresa chega). Os três são baratos de implementar antes da produção. Os três são caros de retrofitar após um incidente. O checklist de implantação em produção neste artigo é especificamente sequenciado para garantir que esses três sejam abordados antes do lançamento.
O recálculo de ROI na Etapa 3
Pilotos provam viabilidade. Produção prova economia. São perguntas diferentes.
Um piloto com 20 usuários ao longo de 60 dias que economiza 3 horas por usuário por semana parece assim em termos anualizados: 20 usuários x 3 horas x 48 semanas = 2.880 horas economizadas. A um custo totalmente carregado médio de US$ 50/hora, isso é US$ 144.000 em valor de trabalho anualizado.
Mas qual é o custo real de rodar essa AI em produção? Custos de API de modelos, tempo da equipe de AI Operations, custos de infraestrutura, overhead de monitoramento. Se o custo total anual de propriedade é de US$ 40.000, o ROI é de US$ 104.000 líquido. Esse é um caso de negócio claro.
Execute esse cálculo antes do seu compromisso de escala na Etapa 3. E use números reais, não preços da fase de piloto do fornecedor. Pergunte ao seu provedor de modelos sobre preços de produção no volume de tokens esperado. Pergunte ao seu contratado de AI Operations quanto custa o tempo deles. Adicione 20% para overhead não antecipado.
Por Que ROI de AI É Difícil de Provar traz o framework completo de mensuração de ROI com as dimensões que importam: tempo economizado, redução de custo, melhoria de qualidade e impacto na receita.
Um exemplo real da Etapa 2 para a Etapa 3
Uma empresa SaaS de 200 pessoas rodou um piloto bem-sucedido com um Agente de Suporte de AI no terceiro trimestre de 2025. O piloto mostrou que AI conseguia resolver 35% dos tickets de suporte entrantes sem envolvimento humano, liberando 15 horas por semana por engenheiro de suporte.
Antes de escalar, tomaram três decisões de infraestrutura: padronizaram no OpenAI Enterprise para o provedor de modelos, se comprometeram com o Pinecone como banco de dados vetorial para a base de conhecimento de suporte e implantaram o LangSmith para observabilidade.
Contrataram um Líder de AI Operations no quarto trimestre de 2025. Essa pessoa foi responsável pelo checklist de implantação em produção, conduziu o treinamento de usuários, escreveu o runbook de incidentes e configurou o dashboard de monitoramento de custos.
No primeiro trimestre de 2026, o Agente de Suporte de AI estava em produção para toda a equipe de suporte. Em paralelo, lançaram o Piloto 2: um assistente de AI Sales Operations que elabora resumos de chamadas e recomendações de próximos passos diretamente no CRM. Esse piloto está em execução agora, com a infraestrutura do Piloto 1 como fundação.
Eles não rodaram cinco pilotos em paralelo. Rodaram um bem, comprometeram a infraestrutura e usaram essa fundação para o próximo. Essa é a transição da Etapa 2 para a Etapa 3 feita corretamente.
O que vem a seguir
A implantação em produção é a Etapa 3. A transição para a Etapa 4 é de uma ordem de magnitude diferente: AI não como uma camada sobre seus workflows, mas integrada ao seu modelo operacional central. A maioria das empresas de mercado médio não estará pronta para a Etapa 4 por mais dois a três anos.
Mas entender o que a Etapa 4 exige ajuda você a investir corretamente na Etapa 3. Você não está apenas escalando ferramentas. Está construindo a infraestrutura e a governança das quais a Etapa 4 depende. Esse investimento se acumula para o futuro.
Leia: Etapa 3 para 4: Do Escalado para o Integrado para os requisitos organizacionais e arquitetônicos.
Leia: As 5 Etapas de Maturidade em AI para ver o modelo completo de maturidade e onde a Etapa 3 se encaixa.
Leia: Playbook de Resposta a Incidentes de AI antes da sua primeira implantação em produção. Você vai querer tê-lo pronto antes de precisar.
Veja também:
- O Custo Honesto da Transformação de AI: o investimento em infraestrutura exigido na Etapa 3 modelado em relação ao caso de negócio
- Sequenciando Padrões de AI em um Roadmap de Vários Anos: como priorizar seu segundo e terceiro casos de uso após o sucesso do Piloto 1

Co-Founder, Rework.com
On this page
- O que parece o purgatório de pilotos
- O Teste de Travessia da Etapa 2 para a Etapa 3
- Critérios de saída da Etapa 3
- As decisões de infraestrutura que a Etapa 3 exige
- O checklist de implantação em produção
- Gestão de mudanças na escala: dos voluntários para todos
- Governança na Etapa 3: do rascunho para a função
- O recálculo de ROI na Etapa 3
- Um exemplo real da Etapa 2 para a Etapa 3
- O que vem a seguir