Stufe 2 zu 3: Vom Pilot zur Skalierung, Aus dem Pilot-Purgatorium entkommen
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ihr KI-Pilot hat funktioniert. Den Nutzern gefällt er. Die ersten Zahlen sind ermutigend. Das Sales-Development-Rep-Team spart drei Stunden pro Woche bei der E-Mail-Personalisierung. Die Antwortrate ist um 12% gestiegen. Der Pilot-Eigentümer präsentiert die Ergebnisse. Die Führungsebene nickt.
Dann stellt jemand die Frage: „Wie skalieren wir das?"
Und plötzlich weiß niemand die Antwort.
Das ist das Pilot-Purgatorium. Es ist der Raum zwischen „der Pilot hat funktioniert" und „wir haben KI im Produktionsbetrieb". Es ist der Punkt, an dem die meisten Stufe-2-Organisationen stecken bleiben, manchmal ein Jahr lang, manchmal länger. Forrester identifiziert Use-Case-Ausufern als eines der größten Hindernisse bei der KI-Skalierung: Unternehmen haben oft Dutzende von Piloten, aber kein Framework, um diese zu priorisieren und zu aktivieren. Der Pilot verharrt in der Schwebe, während das Team über Infrastruktur debattiert, auf Budget wartet, über Eigentümerschaft streitet oder einfach einen weiteren Pilot startet, weil das sicherer erscheint als die Verpflichtung, die Produktion erfordert.
Zu verstehen, warum das Pilot-Purgatorium entsteht, ist der erste Schritt, um ihm zu entkommen. Wenn Sie noch auf Stufe 1 sind, lesen Sie zuerst Stufe 1 zu 2: Von Ad-hoc zum Pilot.
Wie das Pilot-Purgatorium aussieht
Key Facts: Herausforderungen beim Übergang vom Pilot zur Skalierung
- Forrester identifiziert Use-Case-Ausufern als eines der größten KI-Skalierungshindernisse; Unternehmen haben oft Dutzende von Piloten, aber kein Framework, um diese in Produktion zu aktivieren (Forrester, 2025)
- Organisationen, die KI skaliert haben (Stufe 3+), erzielen über drei Jahre einen Gesamtaktionärsertrag, der etwa 4-mal höher ist als bei KI-Nachzüglern; der Abstand zwischen Vorreitern und Nachzüglern vergrößert sich mit jedem Jahr der Verzögerung auf Stufe 2 (BCG, 2025)
- McKinsey stellte fest, dass der Wechsel von erfolgreichen KI-Piloten zu unternehmensweitem Deployment die Übernahme einer Skalierungs-Denkweise, einen modularen Ansatz beim Aufbau von KI-Assets und die Verkürzung des Analytics-Entwicklungszyklus erfordert, Anforderungen, für die die meisten Teams auf Pilot-Ebene nicht strukturiert sind (McKinsey, 2025)
Das Pilot-Purgatorium hat konsistente Symptome.
Piloten, die 12+ Monate im Pilot-Status bleiben. Die im Charter festgelegte Zeitbegrenzung kommt und geht. Niemand entscheidet sich explizit zur Skalierung. Niemand stellt den Pilot explizit ein. Er läuft einfach weiter bei niedrigem Volumen, verbraucht etwas Aufwand, ohne Wert im Produktionsmaßstab zu liefern.
Mehrere konkurrierende Tools werden gleichzeitig evaluiert. Anstatt sich auf ein Tool zu verpflichten und es zu skalieren, öffnet das Team Evaluierungen von zwei oder drei Alternativen. „Wir wollen sicherstellen, dass wir die richtige Wahl treffen." Achtzehn Monate später haben sie sich noch immer nicht entschieden.
Führungskräfte warten auf „noch einen Datenpunkt". Der Pilot hat gute Ergebnisse produziert, aber die Führungsebene möchte eine größere Stichprobengröße, einen längeren Zeitraum oder einen komplexeren Use Case vor der Verpflichtung. Die Messlatte verschiebt sich immer weiter.
Keine Infrastrukturentscheidungen getroffen. Der Pilot lief auf einem vom Anbieter verwalteten Cloud-Setup ohne architektonische Verpflichtungen des Unternehmens. Die Skalierung würde Entscheidungen über Datenspeicherung, Modell-Hosting, API-Eigentümerschaft und Monitoring erfordern, die noch niemand getroffen hat.
Das Pilot-Team ist ausgebrannt. Dieselben drei Personen, die den Pilot durchgeführt haben, werden gebeten, die nächsten zwei Piloten zu führen und gleichzeitig herauszufinden, wie der erste skaliert werden soll. Sie sind überlastet, unstrukturiert und fangen an, sich zu distanzieren.
Wenn zwei oder mehr dieser Punkte zutreffen, befinden Sie sich im Pilot-Purgatorium. Der Ausweg erfordert Ausführungsdisziplin, nicht mehr Evaluation.
„Der Übergang von Stufe 2 zu Stufe 3 scheitert am häufigsten nicht, weil der Pilot falsch war, sondern weil das Team die Produktionsbereitstellung als größere Version des Pilots behandelt. Das ist sie nicht. Produktion erfordert Infrastrukturverpflichtungen, Change Management über Freiwillige hinaus, Kosten-Governance und einen namentlich genannten AI-Operations-Eigentümer. Unternehmen, die Stufe 3 mit Stufe-2-Infrastruktur betreiben, sind mit Vorfällen, Kostensurprisen und Einführungseinbruch konfrontiert." (Rework)
Der Stage 2-to-3 Crossing Test
Eine Vier-Anforderungs-Diagnose, die bestätigt, dass eine Organisation tatsächlich von Stufe 2 zu Stufe 3 übergegangen ist, anstatt einen skalierten Pilot als Produktion zu etikettieren. Anforderung 1: Ein Use Case ist für alle vorgesehenen Nutzer bereitgestellt (kein Freiwilligen-Cohort), mit aktivem Monitoring. Anforderung 2: Gemeinsame Infrastrukturentscheidungen sind dokumentiert und verpflichtend (Model-Provider, Vektordatenbank, Observability-Stack), nicht ad-hoc pro Use Case. Anforderung 3: Ein zweiter Use Case befindet sich im aktiven Pilot und nutzt die Infrastruktur aus Anforderung 2 als Grundlage. Anforderung 4: Ein namentlich genannter AI-Operations-Eigentümer existiert mit expliziter Verantwortlichkeit für die Betriebszeit des Produktionssystems, Vorfälle und Modell-Versionierung. Organisationen, die nur Anforderung 1 erfüllen, betreiben einen skalierten Pilot, keine Stufe-3-Bereitstellung.
Stufe-3-Ausgangskriterien
Stufe 3 ist nicht nur „mehr Piloten". Es ist eine qualitativ andere Betriebsposition. Folgendes muss zutreffen, um sie zu beanspruchen.
| Anforderung | Was es bedeutet | Häufige Lücke |
|---|---|---|
| Ein Use Case im Produktionsbetrieb | Für alle vorgesehenen Nutzer bereitgestellt, kein Freiwilligen-Cohort. Vollständige Einführung mit aktivem Monitoring. | Läuft noch im Pilot-Maßstab für die „richtigen" Nutzer |
| Gemeinsame Infrastrukturentscheidungen getroffen | Vektordatenbank, Model-Provider, Guardrail-Tooling und Observability-Stack: ausgewählt und verpflichtend | Nutzt noch die ad-hoc-Infrastruktur des Pilots. Jeder Use Case läuft auf separaten Anbieter-Stacks. |
| Ein zweiter Use Case im aktiven Pilot | Beweis, dass das Lernen von Pilot 1 sich auf Pilot 2 übertragen hat. Nicht nur geplant: läuft. | Gesamte Energie floss in die Skalierung von Pilot 1. Keine Kapazität für neue Use Cases. |
| AI-Operations-Eigentümerschaft | Namentlich genannte Person oder kleines Team verantwortlich für KI-Produktionssysteme: Betriebszeit, Incident-Response, Modell-Versionierung | Pilot-Eigentümer betreibt Produktion noch neben seinem Hauptjob |
Alle vier Anforderungen müssen zutreffen, bevor die Organisation Stufe 3 beansprucht. Die am häufigsten übersprungene ist die gemeinsame Infrastruktur. Es ist auch diejenige, die die teuersten Probleme verursacht, wenn sie übersprungen wird.
Die Infrastrukturentscheidungen, die Stufe 3 erfordert
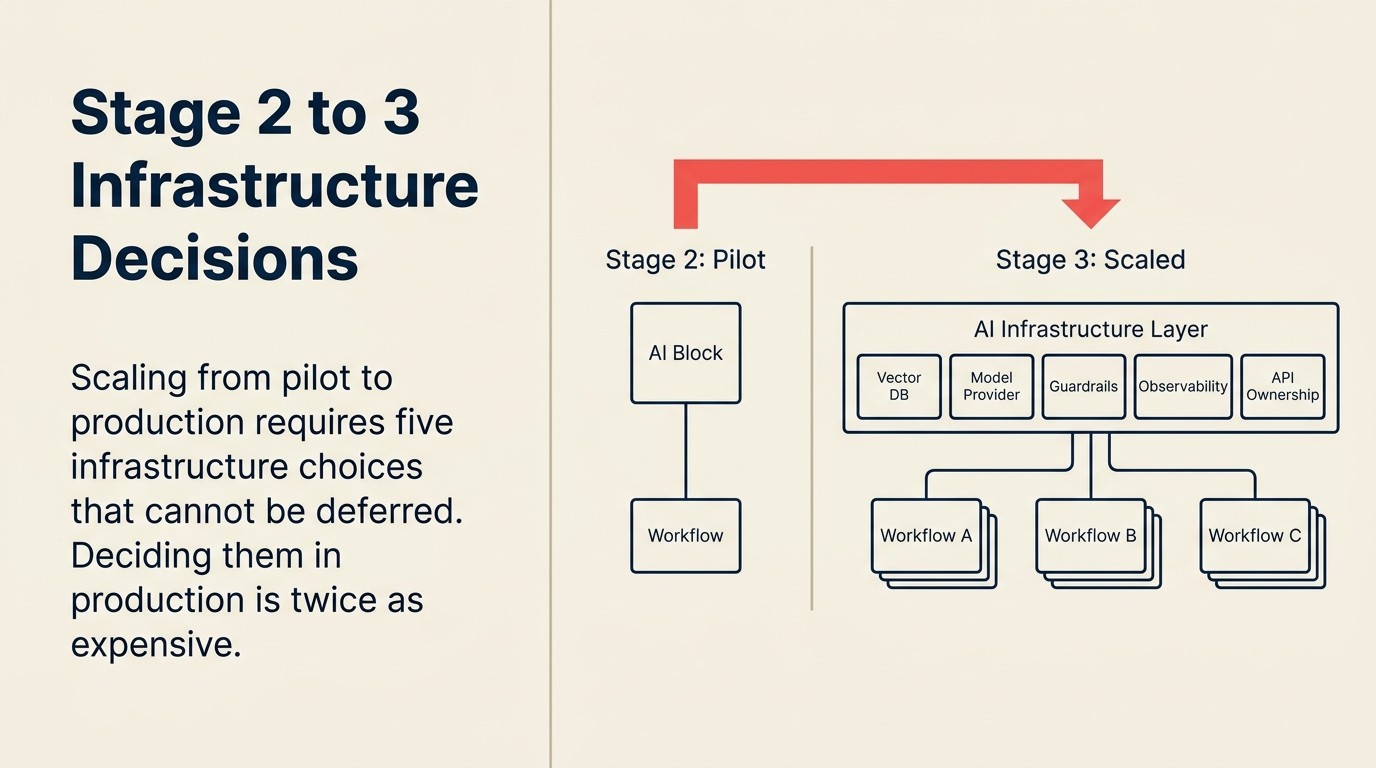
Das ist der Teil, der die meisten Transformations-Leads überrascht, die aus einem SaaS-Einkaufs-Hintergrund kommen. KI im Produktionsmaßstab erfordert architektonische Verpflichtungen, die für normale SaaS-Tools nicht gelten. Sie müssen diese Entscheidungen vor der Skalierung treffen, nicht danach.
Auswahl der Vektordatenbank. Wenn Ihre KI-Anwendungen Retrieval-Augmented Generation (RAG), die Suche in internen Dokumenten oder Gedächtnis über Interaktionen hinweg beinhalten, benötigen Sie eine Vektordatenbank. Die wichtigsten Optionen 2026 sind Pinecone, Weaviate, Qdrant und pgvector (für Teams, die bereits PostgreSQL nutzen). Die Wahl spielt weniger eine Rolle als sie zu treffen. Verschiedene Use Cases auf verschiedenen Vektor-Stores zu betreiben, erzeugt Fragmentierung, die teuer rückgängig zu machen ist.
Model-Provider-Entscheidungen. Auf welche Large-Language-Model-Anbieter standardisieren Sie? OpenAI, Anthropic, Google oder eine Mischung? Enterprise-Verträge haben unterschiedliche Preisgestaltungen, Datenverarbeitungsbedingungen und Leistungsmerkmale. Die Nutzung des kostenlosen ChatGPT-Tiers für Piloten ist in Ordnung. Produktions-Workloads benötigen ordnungsgemäße Enterprise-Verträge mit Datenverarbeitungsverträgen (DPAs) und SLA-Verpflichtungen.
Guardrail-Tooling. Wie verhindern Sie, dass KI im Maßstab schädliche, falsche oder markenschädliche Outputs produziert? Auf Pilot-Ebene prüft ein Mensch jeden Output. Auf Produktionsmaßstab ist das nicht möglich. Guardrails laufen als Vor- und Nachverarbeitungsschichten um Modellaufrufe. Optionen reichen von individuellem Prompt-Engineering bis hin zu zweckgebauten Tools.
Observability-Stack. Wie wissen Sie, wenn Ihre KI defekt ist? Auf Pilot-Ebene merkt der Pilot-Eigentümer es. Auf Produktionsmaßstab brauchen Sie Logging, Alerting und Dashboards. Welche Kennzahlen zählen: Antwortlatenz, Fehlerrate, Fallback-Rate, Auslöser für menschliche Prüfung. Das ist die einzige Infrastrukturkomponente, von der die meisten Teams entdecken, dass sie sie brauchen, erst nach einem Produktionsvorfall.
API-Eigentümerschaft und Rate Limits. Wem gehören die API-Schlüssel für Ihre Model-Provider? Auf Pilot-Ebene: wahrscheinlich der Person, die den Pilot eingerichtet hat. Auf Produktionsmaßstab: ein Service-Account, der IT gehört, mit Rate Limits, um Kosten-Spitzen zu verhindern, und mit Rotationsrichtlinien für die Sicherheit.
Das sind keine IT-Entscheidungen in Isolation. Sie sind architektonische Verpflichtungen, die jeden KI-Use-Case betreffen, den Sie danach aufbauen werden. Sie gemeinsam zu treffen, vor der Skalierung, spart Monate an Nacharbeiten.
Die Checkliste für Produktionsbereitstellung

„Wir bringen das in Produktion" bedeutet für verschiedene Teams Verschiedenes. Für KI-Systeme hat Produktion eine spezifische Bedeutung. Diese acht Dinge müssen zutreffen.
1. Monitoring ist aktiv. Nicht „wir werden es gelegentlich prüfen." Aktives Monitoring mit Warnungen bei Fehlerrate-Spitzen, Latenzdegradierung und ungewöhnlichen Output-Mustern.
2. Fallback-Logik existiert. Wenn die KI ausfällt (Modell-Timeout, Guardrail-Auslöser, Rate Limit), was passiert? Der Nutzer darf keinen leeren Bildschirm oder eine rohe Fehlermeldung sehen. Definieren Sie den Fallback: zwischengespeicherten Output anzeigen, für menschliche Prüfung in die Warteschlange stellen, höflich ablehnen.
3. Human-in-the-loop-Gates sind definiert. Welche Outputs erfordern menschliche Prüfung vor der Aktion? Für KI-verfasste externe Kommunikation: definieren Sie, ob der Mensch vor dem Versenden prüft (erforderlich) oder nach dem Versenden (zu spät). Legen Sie diese Regel vor dem Go-live fest.
4. Modell-Versionierung wird verfolgt. Wenn der Model-Provider sein Modell aktualisiert, können sich Ihre Outputs ändern. Sie brauchen eine Aufzeichnung, welche Modellversion wann lief, um unerklärte Output-Änderungen zu diagnostizieren.
5. Incident-Response existiert. Wenn die KI einem Kunden falsche Informationen sendet, wen rufen Sie an? In welcher Reihenfolge? Was ist der SLA für die Lösung? Schreiben Sie das Runbook, bevor Sie es brauchen.
6. Nutzerkommunikation ist abgeschlossen. Alle vorgesehenen Nutzer wissen, dass die KI im Produktionsbetrieb läuft, verstehen, was sie tut, und wurden darauf geschult, wie Outputs zu prüfen, zu korrigieren und zu eskalieren sind.
7. Kosten-Monitoring ist aktiv. KI-Produktions-Workloads können unerwartete Kostensteigerungen erzeugen. Token-Verbrauch, API-Aufrufvolumen und Modellauswahl beeinflussen alle die Kosten. Jemand besitzt den monatlichen Kostenbericht.
8. Datenverarbeitungsverträge sind unterzeichnet. Wenn die KI personenbezogene oder unternehmensvertrauliche Daten verarbeitet, muss der DPA Ihres Anbieters vor der Produktion in Kraft sein. „Wir fügen den DPA nach der Skalierung hinzu" ist ein Compliance-Verstoß, kein Backlog-Element.
Diese Checkliste ist der Unterschied zwischen „deployed" und „Produktion". Die meisten Teams erreichen 5 von 8. Die drei, die sie überspringen, sind die, die Vorfälle verursachen.
Change Management skalieren: von Freiwilligen zu allen
Piloten laufen auf Freiwilligen. Die Personen in Ihrem Pilot-Cohort haben sich gemeldet. Sie waren neugierig auf KI, bereit zu experimentieren und tolerant gegenüber rauen Kanten. Sie sind kein repräsentativer Querschnitt Ihrer vollständigen Nutzerpopulation.
Produktionsmaßstab betrifft alle. Und alle umfasst die Skeptiker, die Zeitknappen, die „das klingt nach mehr Arbeit, nicht weniger" und diejenigen, die sich still sorgen, dass wenn die KI ihre Arbeit gut macht, sie keine Stelle mehr haben.
Hier stagnieren Übergänge von Stufe 2 zu Stufe 3 am häufigsten. Der Pilot funktionierte bei 20 freiwilligen Sales Development Reps. Das vollständige Team hat 80 SDRs, darunter 30, die diesen Job seit fünf Jahren machen und nicht begeistert davon sind, ihren Workflow zu ändern.
Das Change-Management-Playbook für Stufe 3 hat vier Teile.
Schulen Sie für den neuen Workflow, nicht das Tool. Mitarbeiter widerstehen Tools. Sie akzeptieren Workflow-Verbesserungen. Führen Sie kein „KI-Tool-Training" durch. Führen Sie eine „neue SDR-Workflow-Durchführung" durch, die zufälligerweise das KI-Tool enthält. Zeigen Sie Vorher und Nachher. Machen Sie die Zeitersparnis sichtbar.
Geben Sie den Skeptikern einen sicheren Einstieg. Machen Sie KI anfangs nicht zur einzigen Option. Lassen Sie Skeptiker es zunächst optional nutzen. Der Sozialbeweis von Kollegen, die bessere Ergebnisse erzielen, ist überzeugender als ein Führungsmandat.
Sprechen Sie die Angst direkt an. Wenn Sie die Sorge „Wird das mich ersetzen?" nicht explizit benennen, wird sie jede informelle Unterhaltung über den Rollout dominieren. Benennen Sie es in der All-Hands-Veranstaltung. Beschreiben Sie die Rollenentwicklung: Was die KI übernimmt, was Menschen tun, was KI nicht kann. Seien Sie spezifisch. Unschärfe macht Angst schlimmer.
Messen Sie Akzeptanz, nicht nur Ergebnisse. Wie viele Nutzer verwenden den KI-Workflow täglich? Wöchentlich? Gar nicht? Verfolgen Sie die Akzeptanz so ernst wie Geschäftsergebnisse. Niedrige Akzeptanz erklärt schlechte Ergebnisse, und sie ist behebbar, wenn Sie sie früh erkennen.
Governance auf Stufe 3: vom Entwurf zur Funktion
Auf Stufe 2 hatten Sie eine Minimum-Viable-Policy. Auf Stufe 3 haben Sie KI im Produktionsbetrieb über mehrere Use Cases hinweg. Die Governance-Anforderungen erweitern sich entsprechend.
Tool-Genehmigungsfunktion. Jemand prüft neue KI-Tool-Anfragen, wendet das Datenklassifizierungs-Framework an und erteilt Genehmigungen. Keine Kommission. Eine Person mit einem Prozess und einer Bearbeitungszeit.
Incident-Eigentümerschaft. Wenn ein Produktions-KI-Vorfall eintritt (falscher Output, Datenexponierung, Modellausfall), wer besitzt die Lösung? Auf Stufe 3 ist das eine benannte Rolle: AI-Operations-Lead oder Äquivalent. Keine gemeinsame E-Mail-Liste.
Vierteljährliche Richtlinienprüfung. KI bewegt sich schnell. Ihre Liste genehmigter Tools von vor sechs Monaten kann Tools enthalten, die ihre Datenverarbeitungsbedingungen geändert haben. Erstellen Sie einen Kalendereintrag: vierteljährliche Prüfung, zwei Stunden, genehmigte Tool-Liste plus Vorfall-Log.
Audit-Trail-Baseline. Für jeden Execute-fähigen KI-Workflow (KI, die Aktionen in Systemen ausführt) benötigen Sie ein Log darüber, was die KI getan hat, wann und mit welchem Ergebnis. Das ist in den meisten Jurisdiktionen eine rechtliche und Compliance-Anforderung im Produktionsmaßstab und die Grundlage für die Fehlerbehebung, wenn etwas schiefläuft. Siehe Audit-Trails für KI-Execute-Aktionen für das, was ein produktionstauglicher Audit-Trail erfordert.
Rework-Analyse: Basierend auf Unternehmens-KI-Deployment-Mustern sind die drei Infrastrukturkomponenten, die am häufigsten bis nach einem Produktionsvorfall verschoben werden: Observability-Stack (Teams entdecken, dass sie ihn brauchen, wenn sie nicht diagnostizieren können, warum Outputs degradiert sind), Datenverarbeitungsverträge mit Model-Providern (nach dem Deployment angesprochen, wenn Legal die Compliance-Lücke erkennt) und Kosten-Monitoring (aufgetaucht, wenn die erste Überraschungsrechnung eintrifft). Alle drei sind vor der Produktion günstig zu implementieren. Alle drei sind nach einem Vorfall teuer nachzurüsten. Die Checkliste für Produktionsbereitstellung in diesem Artikel ist speziell sequenziert, um sicherzustellen, dass diese drei vor dem Go-live adressiert werden.
Die ROI-Neuberechnung auf Stufe 3
Piloten beweisen Machbarkeit. Produktion beweist Wirtschaftlichkeit. Das sind verschiedene Fragen.
Ein Pilot mit 20 Nutzern über 60 Tage, der 3 Stunden pro Nutzer und Woche spart, sieht auf annualisierter Basis so aus: 20 Nutzer x 3 Stunden x 48 Wochen = 2.880 gesparte Stunden. Bei durchschnittlichen vollständig beladenen Kosten von 50 Euro/Stunde sind das 144.000 Euro an annualisiertem Arbeitswert.
Aber was kostet es tatsächlich, diese KI in Produktion zu betreiben? Model-API-Kosten, AI-Operations-Team-Zeit, Infrastrukturkosten, Monitoring-Overhead. Wenn die gesamten jährlichen Betriebskosten 40.000 Euro betragen, beträgt der ROI 104.000 Euro netto. Das ist ein klarer Business Case.
Führen Sie diese Berechnung durch, bevor Sie die Stufe-3-Skalierungsverpflichtung eingehen. Und verwenden Sie echte Zahlen, keine Pilot-Stufen-Anbieterpreise. Fragen Sie Ihren Model-Provider nach Produktionspreisen bei Ihrem erwarteten Token-Volumen. Fragen Sie Ihre AI-Operations-Einstellung, was ihre Zeit kostet. Fügen Sie 20% für nicht antizipierte Overheads hinzu.
Ein echtes Stufe-2-zu-3-Beispiel
Ein 200-köpfiges SaaS-Unternehmen führte im dritten Quartal 2025 einen erfolgreichen Pilot mit einem KI-Support-Agenten durch. Der Pilot zeigte, dass KI 35% der eingehenden Support-Tickets ohne menschliches Eingreifen lösen konnte, und befreite 15 Stunden pro Woche pro Support-Engineer.
Vor der Skalierung trafen sie drei Infrastrukturentscheidungen: Standardisierung auf OpenAI Enterprise für ihren Model-Provider, Verpflichtung zu Pinecone als Vektordatenbank für die Support-Wissensdatenbank und Deployment von LangSmith für Observability.
Sie stellten im vierten Quartal 2025 einen AI-Operations-Lead ein. Diese Person besaß die Checkliste für Produktionsbereitstellungen, führte Nutzerschulungen durch, schrieb das Incident-Runbook und richtete das Kosten-Monitoring-Dashboard ein.
Im ersten Quartal 2026 war der KI-Support-Agent im Produktionsbetrieb für das gesamte Support-Team. Parallel starteten sie Pilot 2: einen KI-Sales-Operations-Assistenten, der Gesprächszusammenfassungen und Empfehlungen für nächste Schritte direkt im CRM entwirft. Dieser Pilot läuft jetzt, mit der Infrastruktur von Pilot 1 als Grundlage.
Sie betrieben nicht fünf Piloten parallel. Sie führten einen gut durch, verpflichteten sich zur Infrastruktur und nutzten diese Grundlage für den nächsten. Das ist der korrekt ausgeführte Übergang von Stufe 2 zu Stufe 3.
Was als Nächstes kommt
Die Produktionsbereitstellung ist Stufe 3. Der Wechsel zu Stufe 4 ist eine andere Größenordnung: KI nicht als Schicht über Ihren Workflows, sondern in Ihr Kernbetriebsmodell eingewoben. Die meisten Mittelstandsunternehmen werden für weitere zwei bis drei Jahre nicht bereit für Stufe 4 sein.
Aber zu verstehen, was Stufe 4 erfordert, hilft Ihnen, auf Stufe 3 korrekt zu investieren. Sie skalieren nicht nur Tools. Sie bauen die Infrastruktur und Governance auf, auf die Stufe 4 angewiesen ist. Diese Investition kumuliert sich vorwärts.
Lesen: Stufe 3 zu 4: Von Scaled zu Integrated für die organisatorischen und architektonischen Anforderungen.
Lesen: Die 5 Stufen der KI-Reife, um das vollständige Reifegradmodell zu sehen und wo Stufe 3 hineinpasst.
Lesen: KI-Incident-Response-Playbook vor Ihrer ersten Produktionsbereitstellung. Sie werden es bereit haben wollen, bevor Sie es brauchen.
Siehe auch:
- Die ehrlichen Kosten der KI-Transformation: die auf Stufe 3 erforderliche Infrastrukturinvestition, modelliert gegen den Business Case
- KI-Patterns in einer mehrjährigen Roadmap sequenzieren: wie Sie Ihren zweiten und dritten Use Case priorisieren, nachdem Pilot 1 erfolgreich war

Co-Founder, Rework.com
On this page
- Wie das Pilot-Purgatorium aussieht
- Der Stage 2-to-3 Crossing Test
- Stufe-3-Ausgangskriterien
- Die Infrastrukturentscheidungen, die Stufe 3 erfordert
- Die Checkliste für Produktionsbereitstellung
- Change Management skalieren: von Freiwilligen zu allen
- Governance auf Stufe 3: vom Entwurf zur Funktion
- Die ROI-Neuberechnung auf Stufe 3
- Ein echtes Stufe-2-zu-3-Beispiel
- Was als Nächstes kommt