ROI por Capacidad ACE: Qué Inversiones en AI Retornan Más Rápido

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La mayoría de las conversaciones sobre presupuesto de AI fracasan por la misma razón: tratan todas las inversiones en AI como intercambiables. Una presentación ante el directorio agrupa "gastos en AI" en una sola línea y pide un único número de ROI. Pero un AI que hace Ingest de documentos al inicio de su flujo de trabajo genera un retorno fundamentalmente diferente al de uno que Executes órdenes de compra al final.
Tratarlos como equivalentes es la razón por la que se aprueban los proyectos incorrectos primero, y luego hay que explicarle al directorio por qué "la AI" no entregó lo prometido.
El ACE Framework define cinco capacidades del AI empresarial: Ingest, Analyze, Predict, Generate y Execute. Cada una opera en un punto diferente de la cadena de valor. Cada una tiene un perfil de ROI distinto: qué se mide, cómo lucen los retornos típicamente y qué tan difícil es demostrar causalidad. Comprender esos perfiles es lo que permite secuenciar inversiones de forma racional y establecer expectativas honestas con los stakeholders.
Este artículo mapea cada una de las cinco capacidades a su perfil de ROI, incluida una plantilla simple de cálculo de ROI que usted puede adaptar para presentaciones internas.
Por qué el ROI varía según la capacidad ACE
Key Facts: La Realidad del ROI por Capacidad AI
- Los despliegues de AI agéntico (con alto componente Execute) retornan un ROI promedio de 171% en entornos empresariales, aproximadamente 3x los retornos de la automatización tradicional, pero solo el 15-25% de las organizaciones han escalado AI más allá de la etapa piloto. (Menlo Ventures / Bain)
- El tiempo al ROI varía entre dos semanas para automatización de servicio al cliente (Generate + Execute) y más de 12 meses para orquestación de cadena de suministro (Predict + Execute). (AI Monk)
- La organización promedio abandonó el 46% de sus pruebas de concepto de AI antes de llegar a producción en 2025, citando la dificultad de atribución y las métricas poco claras como razones principales. (Master of Code)
El ROI no es uniforme entre los tipos de AI porque la creación de valor ocurre en puntos diferentes de un proceso de negocio.
Ingest se ubica en el flujo ascendente, en el momento en que la información entra a sus sistemas. Su beneficio es invisible para las métricas de ingresos. Analyze se ubica en el medio, afectando qué tan rápido y bien toman decisiones los seres humanos. Predict se encuentra en el punto de inflexión entre "tenemos datos" y "actuamos en base a ellos", y tiene el mayor potencial teórico de atribución de ingresos. Generate produce artefactos que los humanos luego utilizan, creando una capa entre el output del AI y el resultado de negocio. Execute cambia el estado directamente y es la capacidad más cercana a eventos medibles de costo o ingresos.
Esa progresión de flujo ascendente a descendente también es una progresión de más difícil a más fácil de medir. Pero es el reverso de la jerarquía de riesgo: Execute es la más fácil de demostrar ROI y también la más costosa cuando algo sale mal.
Algunas otras variables explican la variación.
La dificultad de atribución aumenta con la complejidad de la decisión. Si un AI Generate un primer borrador que un representante edita hasta convertirlo en un email ganador, ¿cuánto de ese negocio corresponde al AI? No hay forma de saberlo con certeza. Si un AI Executes una orden de compra que previene una ruptura de stock, el costo del desabasto evitado es atribuible. Uno tiene una cadena causal clara; el otro no.
El tiempo al valor varía. Las capacidades Ingest (reconocimiento óptico de caracteres, transcripción, análisis de documentos) suelen estar entre las más rápidas de desplegar y las más baratas de medir. Las capacidades Execute toman más tiempo en desplegarse de forma segura, pero crean la reducción de costos más persistente una vez en funcionamiento.
La infraestructura de medición importa. Demostrar el ROI de Predict requiere infraestructura de pruebas A/B: un grupo de control que no usa el modelo versus un grupo de tratamiento que sí lo usa. La mayoría de las organizaciones no tienen esa infraestructura configurada cuando inician su primer proyecto de AI. Este no es un problema técnico; es un problema de proceso.
Perfil de ROI de Ingest
Qué hace Ingest: Convierte señales en bruto (imágenes, audio, PDFs escaneados, flujos de documentos) en información con la que el AI puede trabajar. El reconocimiento óptico de caracteres (OCR), la transcripción de voz a texto, el análisis de documentos y la extracción de datos estructurados son operaciones canónicas de Ingest.
Métricas primarias:
- Reducción en el tiempo de ingreso manual de datos (horas por semana, por operador)
- Tasa de precisión de datos (errores por 1.000 registros, antes vs. después)
- Capacidad de procesamiento (documentos procesados por hora)
Retornos típicos: Un equipo financiero que introduce manualmente facturas en un sistema de planificación de recursos empresariales (ERP) puede tardar entre 30 segundos y 2 minutos por documento. Un AI de Ingest que procesa los mismos documentos típicamente opera en menos de 3 segundos con una precisión del 95-99%. Para un equipo que procesa 500 facturas diarias, eso son 4-8 horas de trabajo manual eliminadas por día, más una reducción medible en errores de digitación que anteriormente causaban problemas de conciliación en el flujo descendente.
El costo por extracción comparado con la línea base humana es la plantilla de ROI más limpia para Ingest. Si una hora de ingreso manual de datos cuesta $25 y usted procesa 10.000 documentos por mes a razón de 2 minutos cada uno, su costo manual es de aproximadamente $8.300/mes. Un AI de Ingest a $500/mes (común para herramientas de automatización de documentos del mercado medio) muestra un retorno claro.
Desafío de medición: Los beneficios de Ingest están en el flujo ascendente. Menos errores en los datos de origen significan menos problemas tres pasos después en cuentas por pagar, registros de clientes o CRM. Pero "los problemas de conciliación que no tuvimos" no aparecen en un dashboard. Usted necesita medir las métricas proxy correctas (tasas de error, horas de retrabajo) antes del despliegue para hacer la comparación antes-y-después. La mayoría de los equipos omiten este paso y luego no pueden demostrar lo que ahorraron. El artículo sobre el Patrón Vision Extract cubre el caso de uso de Ingest con mayor detalle, incluidos los benchmarks de precisión que deben usarse como líneas base pre-despliegue.
Plantilla de cálculo de ROI:
Ahorro mensual = (docs/mes × tiempo_manual_promedio_min / 60) × costo_hora_laboral
ROI = (ahorro_mensual - costo_herramienta) / costo_herramienta × 100%
Perfil de ROI de Analyze
Qué hace Analyze: Da sentido a lo que fue ingestado. Clasificación, extracción, resumen, detección de sentimientos y reconocimiento de entidades son todas operaciones de Analyze. Analyze es lo que convierte texto sin procesar o datos en algo accionable para un ser humano.
Métricas primarias:
- Velocidad de decisión: tiempo desde que la información está disponible hasta que se toma la decisión (horas a minutos)
- Reasignación de capacidad analítica: horas por semana liberadas para trabajo de mayor juicio
- Precisión de clasificación vs. línea base humana
Retornos típicos: Un equipo de soporte al cliente que clasifica 2.000 tickets por día dedica tiempo analítico significativo a enrutar el trabajo antes de que siquiera se toque. Un AI de Analyze que clasifica y etiqueta los tickets entrantes con una precisión superior al 90% libera completamente las decisiones de enrutamiento, reduciendo el tiempo de humano a primera respuesta de horas a segundos.
En roles intensivos en investigación (inteligencia competitiva, análisis financiero, revisión legal), las capacidades Analyze pueden comprimir horas de síntesis en minutos. La ganancia de productividad reportada típicamente para trabajadores del conocimiento que utilizan herramientas de resumen y extracción de AI oscila entre el 20 y el 40% en tiempo por tarea, dependiendo de la complejidad del material fuente.
Desafío de medición: La calidad de las decisiones es difícil de separar de la calidad del análisis del AI. Si su analista toma mejores decisiones después de leer un resumen generado por AI, ¿cuánto de ese resultado corresponde al AI versus al juicio del analista? Usted puede medir la velocidad de decisión con precisión. Puede medir la reasignación de capacidad analítica con seguimiento de tiempo. Pero la atribución de ingresos derivada de decisiones más rápidas o mejores requiere experimentos controlados que la mayoría de las organizaciones no han diseñado. El Patrón RAG Assistant cubre cómo instrumentar la capacidad Analyze para rastrear mejoras en la calidad de las decisiones a lo largo del tiempo.
La recomendación práctica: comience midiendo el proxy (ahorro de tiempo, capacidad de procesamiento), no el impacto en ingresos. Use los primeros seis meses para construir datos de línea base. La atribución de ingresos viene después, una vez que tenga suficientes decisiones con resultados conocidos.
Perfil de ROI de Predict
Qué hace Predict: Puntúa probabilidades, pronostica resultados, clasifica opciones y detecta anomalías. La puntuación de leads, la predicción de churn, la previsión de demanda y la detección de fraude son aplicaciones canónicas de Predict.
Métricas primarias:
- Tasa de conversión (leads puntuados como "alto" por el modelo vs. los no puntuados)
- Tasa de reducción de churn (cuentas marcadas vs. no marcadas, comparación de resultados a 90 días)
- Precisión de pronóstico (error porcentual absoluto medio, o MAPE, antes vs. después del pronóstico con AI)
- Tasas de falsos positivos/negativos para detección de anomalías
Retornos típicos: Predict tiene el mayor potencial de atribución de ingresos de cualquier capacidad ACE porque influye directamente en qué acciones toman los humanos sobre los resultados de negocio más valiosos. Un modelo de puntuación de leads bien calibrado que ayuda a los representantes a priorizar el 20% superior de leads (que típicamente representa el 60-80% de la conversión) puede mejorar materialmente el cumplimiento de cuota sin agregar headcount. Los modelos de predicción de churn que identifican cuentas en riesgo 30-60 días antes de la ventana de decisión de renovación le dan tiempo a los equipos de Customer Success para intervenir.
El rango de resultados reportados es más amplio aquí que para cualquier otra capacidad. Las implementaciones deficientes de Predict (modelos entrenados con datos insuficientes, desplegados sin procesos de adopción por parte de los representantes) muestran un lift casi nulo. Las implementaciones sólidas con infraestructura adecuada de pruebas A/B e integración al flujo de trabajo de los representantes muestran una mejora del 10-30% en la tasa de conversión en benchmarks comparables. El análisis de McKinsey sobre el potencial económico de la AI generativa señala específicamente al marketing y las ventas como el dominio donde las capacidades Predict y de puntuación concentran el valor más medible, estimando una mejora del 3-5% en la productividad de ventas frente al gasto global actual en ventas.
Desafío de medición: El ROI de Predict es el más difícil de atribuir con claridad. Requiere pruebas A/B para aislar la contribución del modelo de todo lo demás que ocurre simultáneamente (habilidad del representante, cambios en el producto, condiciones del mercado, movimientos de precios). Sin un grupo de control, no se puede saber si la mejora en la conversión provino del modelo o de los comportamientos de los representantes que casualmente correlacionaron con ella.
La mayoría de las organizaciones que afirman ROI de Predict sin pruebas A/B están reportando correlación, no causalidad. Esto no es una razón para evitar la capacidad Predict; es una razón para diseñar la infraestructura de medición antes del despliegue, no después. El Patrón Scoring and Routing cubre el diseño de pruebas A/B para despliegues de Predict, incluida la construcción de grupos de control que los equipos de ventas aceptarán.
Perfil de ROI de Generate
Qué hace Generate: Produce nuevos artefactos a partir de prompts y contexto. Borradores de emails, reportes, código, resúmenes, imágenes y planes estructurados son todos outputs de Generate. El artefacto existe en forma de borrador hasta que un humano lo revisa y lo despliega.
Métricas primarias:
- Ahorro de tiempo en el primer borrador (minutos por artefacto)
- Volumen de contenido con el mismo headcount
- Tiempo del ciclo de edición a publicación (tiempo desde el briefing hasta el borrador final)
- Puntuación de consistencia de marca (si se usa AI con aplicación de guía de estilo)
Retornos típicos: La capacidad Generate ofrece el ahorro de tiempo más claro de cualquier capacidad ACE, y ese ahorro es rápido de medir porque el tiempo del primer borrador es fácil de observar. Un equipo de marketing que tardaba 4 horas en escribir un artículo de blog desde cero típicamente reporta invertir 45-90 minutos en el mismo artículo cuando usa borradores de AI. Un representante de ventas que redactaba una propuesta personalizada pasó de 60-90 minutos a 15-20 minutos.
La matemática sobre el volumen de contenido es sencilla: si un equipo producía 8 artículos de blog por mes antes de AI y ahora produce 18 con el mismo headcount, usted puede calcular el costo efectivo por pieza y compararlo con lo que cobrarían los redactores externos. El volumen de contenido con el mismo headcount es una métrica de ROI de Generate limpia y defendible.
Desafío de medición: La medición de la calidad es la parte difícil. El volumen es fácil de medir; la calidad no lo es. Un primer borrador que requiere edición humana significativa para ser publicable captura menos ROI que uno que requiere edición ligera. Medir la "distancia de edición" (cuánto difiere el output final del borrador del AI) proporciona un proxy de calidad, pero requiere herramientas y seguimiento consistente que la mayoría de los equipos no tienen.
El ROI de Generate se sobreestima frecuentemente en los primeros pilotos porque los equipos miden el ahorro de tiempo del borrador de AI sin considerar el tiempo de revisión, la degradación de calidad (contenido que técnicamente existe pero tiene bajo rendimiento) y el costo de coordinación de gestionar el volumen generado por AI.
El encuadre honesto: Generate ahorra tiempo significativo en primeros borradores. No reemplaza el juicio requerido para hacer que esos borradores sean buenos. La investigación del MIT Sloan sobre el escalado de AI generativa en el lugar de trabajo encontró que la satisfacción de los empleados con las herramientas de borrador de AI se correlaciona más fuertemente con las mejoras percibidas en calidad que con el tiempo bruto ahorrado, razón por la cual medir ambas dimensiones importa.
Perfil de ROI de Execute
Qué hace Execute: Cambia el estado fuera del sistema de AI. Envía emails, actualiza registros, activa flujos de trabajo, emite transacciones y enruta trabajo. Execute es donde el AI deja de generar sugerencias y comienza a tomar acciones con consecuencias reales.
Métricas primarias:
- Tasa de automatización de procesos (porcentaje de un flujo de trabajo manejado sin intervención humana)
- Compresión del tiempo de ciclo (tiempo desde el disparador hasta la finalización)
- Tasa de reducción de errores (errores de proceso antes vs. después de la automatización)
- Costo por transacción vs. línea base humana
Retornos típicos: La capacidad Execute ofrece la reducción de costos más directa de cualquier capacidad ACE cuando funciona bien. Un sistema de automatización de cuentas por pagar (AP) que recibe una factura, la compara con una orden de compra, enruta excepciones a humanos y paga automáticamente las facturas aprobadas comprime un proceso de 5-7 días a mismo día o al día siguiente para los casos claros. En entornos de transacciones de alto volumen (comercio electrónico, servicios financieros, logística), la automatización Execute a escala elimina categorías de roles completas o previene un crecimiento significativo de headcount a medida que escala el volumen.
Pero los retornos solo son claros cuando el proceso en sí está bien definido. Execute aplicado a un proceso desordenado con muchas excepciones no entrega los ahorros esperados y frecuentemente crea nuevos problemas: acciones ejecutadas incorrectamente a escala, casos límite manejados de forma errónea, brechas en la pista de auditoría.
Desafío de medición: El ROI de Execute es el más claro de medir de cualquier capacidad, pero los incidentes son los más costosos de recuperar. Un flujo de trabajo Execute mal configurado que envía emails de facturación incorrectos a 10.000 clientes, o aprueba automáticamente compras más allá de los límites de autorización, crea costos que superan ampliamente los ahorros. El cálculo de ROI debe incluir la probabilidad de incidentes ajustada al riesgo, no solo los ahorros en estado estable.
El modelo de gobernanza correcto para Execute: mida los ahorros esperados, estime la probabilidad y el costo de incidentes, verifique que el ROI ajustado al riesgo aún sea sólido, luego despliegue con una etapa de aprobación con humano en el bucle que solo elimine después de establecer confianza. Consulte Governance by Pattern para el modelo de supervisión y AI Pattern Cost Overruns para las categorías de costos de incidentes que deben incluirse en cualquier modelo de ROI de Execute ajustado al riesgo.
El Perfil de ROI por Capacidad
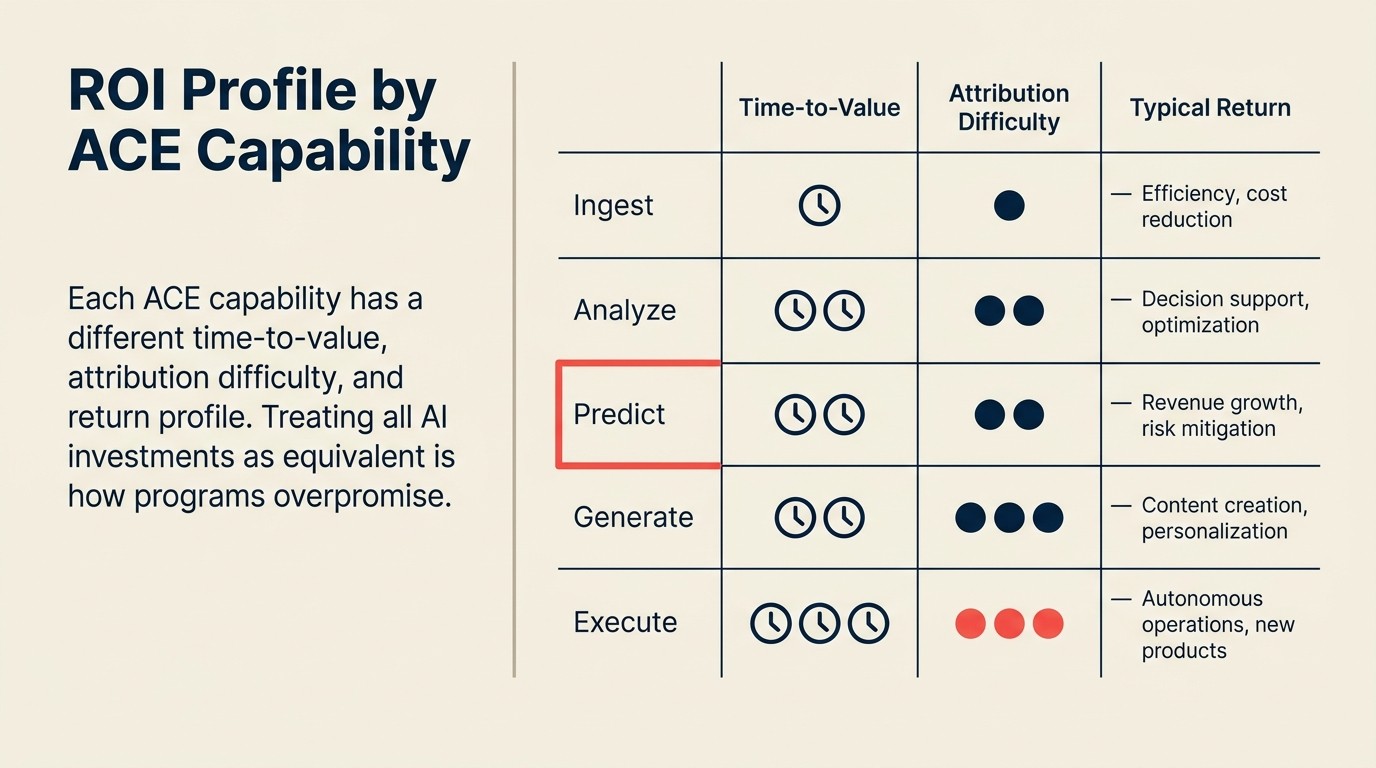
El Perfil de ROI por Capacidad mapea cada una de las cinco capacidades ACE (Ingest, Analyze, Predict, Generate, Execute) a su metodología de medición específica, ventana de retorno típica y dificultad de atribución. En lugar de tratar el "ROI en AI" como un único número, este perfil permite a los patrocinadores de programas presentar casos de inversión específicos por capacidad con la infraestructura de medición adecuada para cada uno.
Quotable: "La capacidad Predict tiene el mayor potencial de atribución de ingresos de cualquier capacidad ACE, porque determina directamente qué acciones toman los humanos sobre los resultados de negocio más valiosos. Pero también requiere infraestructura de pruebas A/B que la mayoría de las organizaciones no construyen hasta después de que su primer despliegue de Predict no logra mostrar un ROI defendible."
Quotable: "El ROI de la capacidad Execute es el más claro de medir y el más costoso cuando algo sale mal. Un flujo de trabajo Execute mal configurado que envía facturación incorrecta a 10.000 clientes crea costos que superan un año completo de ahorros de automatización."
Quotable: "Comience con Generate. No requiere integración, datos históricos ni proceso de aprobación para el despliegue. El ROI es impreciso pero real, y construye familiaridad del equipo con AI antes de abordar capacidades que cuestan más cuando fallan."
| Capacidad ACE | Tiempo al Valor | Dificultad de Atribución | Métrica Primaria de ROI | Retornos Típicos |
|---|---|---|---|---|
| Ingest | 2-6 semanas | Baja (costo laboral directo) | Costo por documento extraído | $500/mes AI vs $8.300/mes manual a 10K docs |
| Analyze | 4-8 semanas | Media (calidad de decisión) | Velocidad de decisión, capacidad analítica | 20-40% ahorro de tiempo por trabajador del conocimiento |
| Predict | 3-6 meses | Alta (requiere prueba A/B) | Tasa de conversión, reducción de churn | 10-30% mejora de conversión con controles adecuados |
| Generate | 2-4 semanas | Media-Baja (volumen claro, calidad menos) | Tiempo del primer borrador, volumen de contenido | Reducción del 60-75% en tiempo del primer borrador |
| Execute | 2-4 meses | Baja (costo directo por transacción) | Tasa de automatización de procesos, tiempo de ciclo | Elimina el crecimiento proporcional de headcount a escala |
Rework Analysis: Basado en patrones de secuenciación de despliegues, las organizaciones que comienzan con capacidades Generate o Ingest construyen músculo de medición y confianza organizacional antes de abordar Predict y Execute, donde tanto las apuestas como la complejidad de medición son más altas. Comenzar con Execute porque tiene el mayor potencial de ROI es el error de secuenciación más común en los programas de AI en etapa temprana.
Secuenciación de inversiones por etapa de madurez
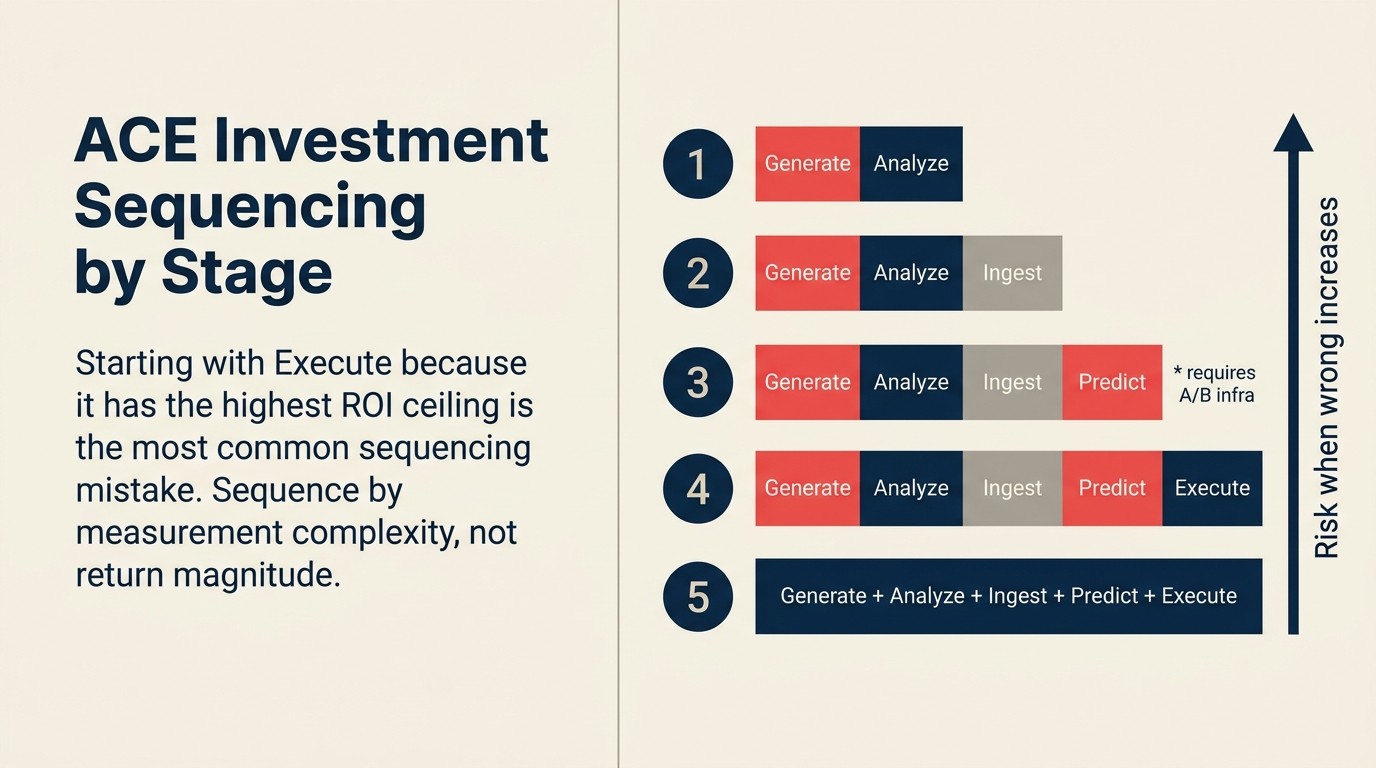
Las capacidades ACE no tienen sentido todas al mismo tiempo. Las organizaciones en diferentes etapas de madurez deben priorizar de manera diferente.
Etapa 1 (Ad-hoc): Comience con Generate. No requiere integración, datos históricos ni proceso de aprobación para el despliegue. El ROI es impreciso pero real, y construye familiaridad del equipo con AI antes de abordar capacidades más complejas. Agregue Analyze para resúmenes de documentos internos y clasificación de tickets.
Etapa 2 (Piloto): Agregue Ingest para sus flujos de trabajo de documentos o ingreso de datos de mayor volumen. El ROI es medible, la integración está acotada y el riesgo es bajo. Comience a diseñar la infraestructura de medición para Predict (tasas de conversión de línea base, auditoría de datos históricos) incluso si aún no está desplegando Predict.
Etapa 3 (Escalado): Despliegue Predict en su primer caso de uso donde tenga 12 o más meses de datos históricos limpios con resultados conocidos. Invierta en la infraestructura de pruebas A/B. No omita este paso; el ROI de Predict afirmado sin grupos de control no es defendible ante un CFO escéptico.
Etapa 4 (Integrado): Introduzca Execute para sus flujos de trabajo de mayor volumen y más predecibles primero. No para procesos con muchas excepciones. No para transacciones de cara al cliente hasta que haya establecido intervalos de confianza. Construya playbooks de respuesta a incidentes antes del despliegue.
Etapa 5 (Transformacional): Las cinco capacidades funcionando, integradas entre sí, con humanos supervisando en lugar de ejecutando el trabajo rutinario. El ROI en esta etapa se mide a nivel de resultado de negocio, no a nivel de capacidad.
El principio de secuenciación es simple: comience con capacidades que sean más baratas de medir y de menor riesgo cuando salen mal. Avance hacia capacidades de mayor retorno y mayor riesgo. No omita la infraestructura de medición en el camino.
Cómo presentarlo a su CFO
La presentación ante el directorio que obtiene aprobación no es la que promete el número de ROI más alto. Es la que es específica sobre qué se está midiendo, honesta sobre qué es difícil de demostrar y secuenciada de una manera que construye confianza organizacional.
Use los perfiles de capacidad anteriores para enmarcar cada inversión con su propio modelo de medición en lugar de una afirmación de ROI combinada única. "Nuestro proyecto Ingest orientado a la automatización de AP muestra un ROI proyectado de 3,2x frente a una línea base medible" es una declaración financiable. "AI mejorará nuestro negocio en un 30%" no lo es.
Para las capacidades donde la atribución es genuinamente difícil (Analyze, Generate, especialmente Predict), enmarque la inversión temprana como infraestructura de medición: está construyendo la línea base y el aparato de pruebas A/B para que la inversión escalada tenga ROI defendible. Eso es honesto, y así es como las organizaciones que lo hacen bien realmente operan.
Las 5 Dimensiones del ROI en AI y Por Qué el ROI en AI Es Difícil de Demostrar extienden este marco más allá. Las Etapas de Madurez de AI en SaaS mapean la lógica de secuenciación al contexto de la industria. Y la Conversación con el CFO sobre el Presupuesto de AI muestra cómo traducir perfiles de ROI específicos por capacidad al lenguaje presupuestal que obtiene aprobación.
La perspectiva específica por capacidad aquí es el punto de partida. Comprender que el ROI de Ingest y Generate es fácil de medir y de magnitud media, mientras que el ROI de Predict es difícil de medir y potencialmente de alta magnitud, le indica cómo faser su inversión y cómo hablar de ello con las personas que aprueban el presupuesto.

Co-Founder, Rework.com