Routing Multinivel con IA en Help Desk SaaS
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
El modelo clásico de asignación de help desk es round-robin o el primero disponible. Quien esté libre toma el siguiente ticket de la cola.
El resultado es predecible. Una disputa de facturación va a un empleado nuevo que no tiene visibilidad de la cuenta. Una pregunta compleja sobre integración de API va a un desarrollador senior que no debería estar invirtiendo tiempo en la cola general de soporte. La preocupación de renovación de un cliente empresarial llega a un agente junior que no conoce el historial de la cuenta. Y un bot de IA que podría haber manejado una simple pregunta de cómo hacerlo lo enruta a un humano porque la lógica de routing no distingue la diferencia.
El routing multinivel con IA soluciona esto. La IA clasifica cada ticket antes de que ningún humano lo vea, puntúa su complejidad, verifica el nivel de cuenta del cliente y lo asigna al manejador correcto en el nivel adecuado. La ganancia de eficiencia es real, pero solo se sostiene si el modelo operativo detrás del routing está diseñado correctamente.
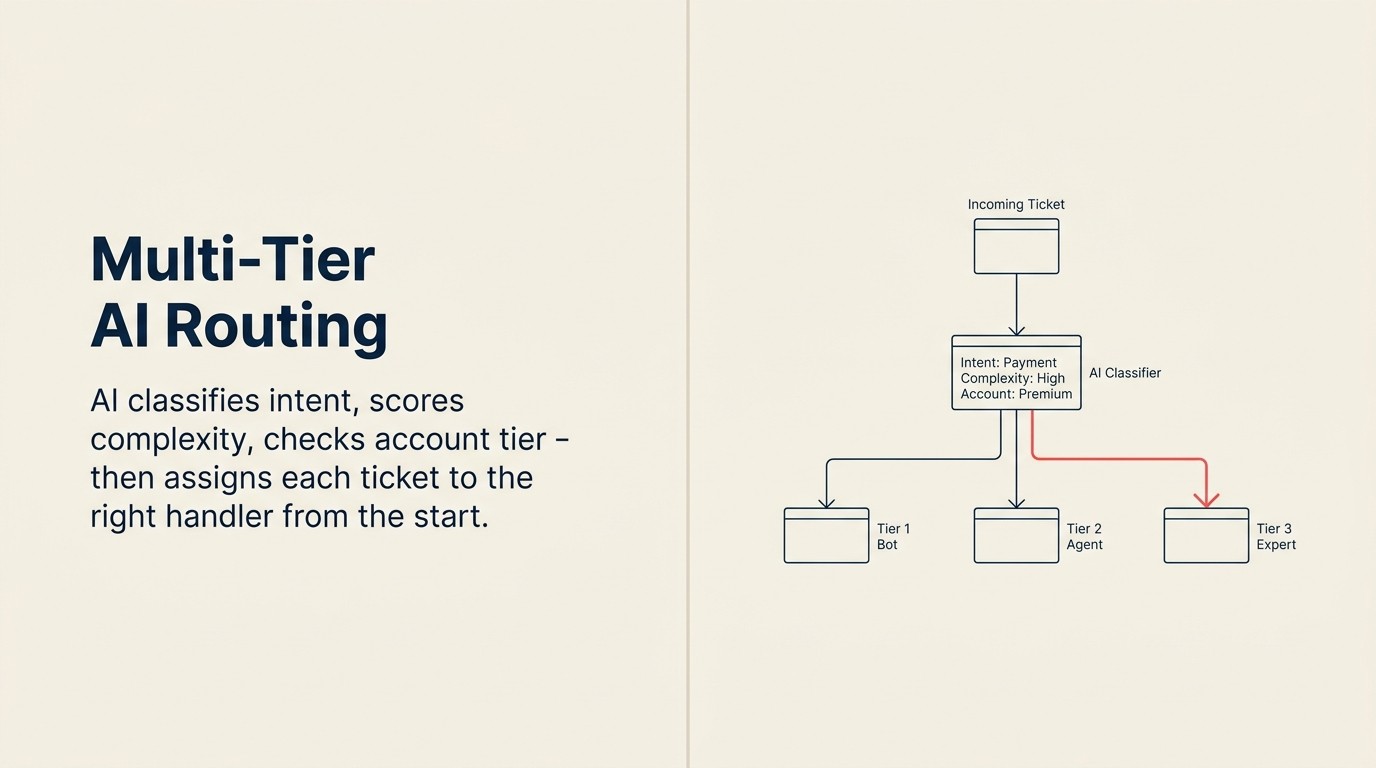
Qué Significa el Routing Multinivel
Un modelo de tres niveles es la estructura estándar para las operaciones de soporte SaaS que ejecutan routing con IA.
Nivel 1 (L1): Autoservicio con IA. El RAG Assistant intenta resolver el ticket completamente. Si lo logra, el ticket se cierra sin intervención humana. Son preguntas de cómo hacerlo, consultas de documentación, resoluciones de códigos de error conocidos, preguntas de comparación de planes y guías de configuración de integraciones. La deflección L1 es la tasa de deflección que reporta.
Nivel 2 (L2): Agente humano aumentado por IA. Un humano toma el ticket con asistencia de IA: una respuesta sugerida de la knowledge base, un resumen del historial de cuenta del cliente y enlaces de documentación relevantes ya presentados. El agente revisa, edita si es necesario y responde. Son problemas moderadamente complejos que necesitan juicio humano pero se benefician de la preparación con IA. La mayoría de las preguntas técnicas de soporte estándar llegan aquí.
Nivel 3 (L3): Manejo humano experto. Agentes senior, desarrolladores o account managers que manejan tickets complejos, sensibles o de alto valor. Problemas de cuenta escalados, errores que requieren investigación de ingeniería, solicitudes de privacidad de datos, disputas de facturación, conversaciones de posible churn. Sin intento de autoservicio por IA; routing directo a un especialista con contexto completo.
El trabajo del sistema de routing es determinar qué nivel maneja qué ticket, y hacerlo con suficiente precisión para que el manejador correcto reciba cada ticket sin crear cuellos de botella en ningún nivel.
Key Facts: Precisión y Eficiencia del Routing con IA
- Los agentes de soporte con IA generativa alcanzan un 92% de precisión en la comprensión de la intención del cliente, frente al 65-70% de los bots más antiguos basados en palabras clave (AI Business Weekly, 2026)
- El routing con IA reduce el tiempo promedio de gestión en un 40% al garantizar que los tickets lleguen al agente o sistema correcto en el primer intento (Unthread, 2026)
- La precisión de clasificación en entornos de tickets con IA maduros reduce los errores de routing incorrecto en un 50-60% comparado con la asignación en round-robin o por disponibilidad (Fini Labs, 2026)
El Modelo de Triaje Intent-Tier-Context
El Modelo de Triaje Intent-Tier-Context es un framework de decisión de routing de tres factores para help desks SaaS. La intención determina la asignación base del nivel: una pregunta de cómo hacerlo se enruta a IA en L1, un reporte de error se enruta a L2, una preocupación de seguridad se enruta a L3 inmediatamente. El nivel aplica anulaciones a nivel de cuenta: la pregunta de cómo hacerlo de un cliente empresarial se enruta a L2 como mínimo independientemente de la clasificación de intención. El contexto aplica ajustes dinámicos: un ticket de un cliente en la ventana de renovación de 60 días con puntuaciones de salud en declive se enruta a la cola del account manager independientemente del tipo de problema declarado. Los tres factores se ejecutan en secuencia, con cada capa capaz de anular la asignación anterior.
El Patrón de Scoring y Routing Aplicado
El Patrón de Scoring y Routing del ACE Framework describe exactamente cómo funciona esto: Ingerir el ticket entrante, Analizar sus características (intención, complejidad, datos del cliente), Predecir el nivel apropiado y Ejecutar la asignación de routing.
La clasificación de intención es el input principal. La IA lee el texto del ticket y lo clasifica en una de varias categorías de intención: solicitud de cómo hacerlo, reporte de error, pregunta de facturación, solicitud de funcionalidad, escalada o queja, preocupación de seguridad, pregunta de API o de desarrollador, ayuda de onboarding. Cada categoría tiene una asignación de nivel predeterminada, que luego se ajusta según la complejidad y el nivel del cliente.
El scoring de complejidad añade matiz a la clasificación de intención. Una pregunta de cómo hacerlo de un cliente empresarial que ha estado esperando una respuesta durante tres días sobre un workflow técnico de varios pasos no es el mismo ticket que una pregunta de cómo hacerlo de un usuario de prueba de pequeña empresa sobre una configuración básica. La intención dice lo mismo; el scoring de complejidad los enruta de forma diferente.
La combinación de intención más complejidad más nivel del cliente es lo que hace que el routing sea inteligente en lugar de solo categórico. Una vez que el sistema está clasificando, la precisión se convierte en el siguiente desafío.
Clasificación de Intención en la Práctica
Zendesk AI clasifica los tickets entrantes en categorías de intención usando un modelo entrenado con datos históricos de tickets. Usted proporciona las categorías, y el modelo aprende de los tickets que los agentes humanos previamente categorizaron. Los datos de entrenamiento son su propio historial de tickets, lo que hace que el modelo sea cada vez más preciso al reflejar cómo su equipo ha enrutado históricamente los tickets.
Freshdesk Freddy funciona de manera similar: clasificación de intención basada en la categorización histórica, con las propiedades del ticket (línea de asunto, texto del cuerpo, presencia de adjuntos) como características. Ambos sistemas permiten definir umbrales de confianza: si la confianza de clasificación está por debajo de un nivel establecido, el ticket se enruta a una cola de revisión humana en lugar de asignarse automáticamente.
Intercom Fin usa lógica de routing de conversaciones que se sitúa sobre la intención: intenta la resolución por IA primero para los tipos de tickets que califican, y transfiere a agentes humanos con contexto completo cuando la IA no puede resolver.
El proceso de entrenamiento inicial típicamente se ejecuta sobre 90 días de tickets históricos. La mayoría de los equipos descubren que la precisión de clasificación de intención alcanza el 80-85% en el primer despliegue con seis a doce meses de datos históricos, y mejora al 90%+ después de tres a cuatro meses de routing en producción donde las clasificaciones incorrectas se corrigen y se retroalimentan al modelo. Gartner identifica la precisión de triaje mejorada y la identificación de expertos como impulsores centrales de valor de la IA en el servicio al cliente, lo que se corresponde directamente con la calidad de clasificación de routing que está construyendo.
Reglas de Routing por Nivel de Cuenta
El nivel del cliente es la anulación más importante sobre el routing basado en intención para las empresas SaaS con niveles de cliente diferenciados.
La regla es simple y debe estar codificada, no aprendida: los clientes empresariales no pasan por el autoservicio de IA en L1 como su primer punto de contacto a menos que lo elijan proactivamente. Se enrutan a L2 como mínimo, con disponibilidad de L3 según el tipo de ticket.
La razón es comercial, no técnica. Los clientes empresariales están pagando un ARR significativo por un nivel de servicio más alto. Un cliente empresarial que envía un ticket de soporte y recibe una respuesta de chatbot de IA antes de cualquier reconocimiento humano tiene una expectativa de servicio diferente a la de un usuario de prueba de pequeña empresa. Cumplir esa expectativa es parte del producto para las cuentas de nivel alto.
Los usuarios de prueba de pequeñas empresas y los clientes mensuales de bajo ARR son los objetivos correctos para el autoservicio de IA en L1. Se benefician de respuestas de IA rápidas las 24 horas, y la economía de manejar sus tickets mediante IA en lugar de agentes humanos es favorable. Pero aplique el autoservicio de IA a su cliente empresarial de $200,000 y habrá cometido un error de posicionamiento independientemente de si la IA respondió correctamente.
Configure estas reglas explícitamente en su lógica de routing. Zendesk AI permite reglas de routing basadas en el nivel del cliente. Intercom soporta esto a través de condiciones de routing de conversación basadas en atributos del cliente. Freshdesk usa reglas de asignación basadas en segmentos. La herramienta de routing es un detalle. La regla en sí debe ser una decisión de política tomada por el liderazgo de soporte, no dejada a la inferencia de un algoritmo.
Señales de Routing Específicas de SaaS
Más allá de la intención y el nivel del cliente, ciertas características del ticket deben activar decisiones de routing inmediatas independientemente de otros factores.
Los errores de autenticación de API se enrutan al soporte de desarrolladores o a un agente humano calificado para el desarrollo. No son preguntas de soporte general. Requieren a alguien que pueda investigar problemas de tokens OAuth, configuración de claves de API y depuración específica de integración. Enrutar un error de autenticación de API a un agente de soporte general desperdicia el tiempo de todos y aumenta significativamente el tiempo hasta la resolución.
Preguntas de facturación durante la ventana de renovación. Cuando una cuenta está en la ventana de renovación de 60 días, las preguntas de facturación se enrutan a la gestión de cuentas, no al soporte de facturación general. El account manager necesita visibilidad, y la conversación es tanto una conversación de retención como una consulta de facturación. La predicción de churn con IA en modelos de suscripción cubre cómo los datos del health score alimentan esta lógica de routing en la ventana de renovación.
Palabras clave relacionadas con seguridad. Los tickets que contienen términos relacionados con acceso no autorizado, sospecha de brecha de datos, compromiso de cuenta o actividad de inicio de sesión inusual se enrutan directamente a L3 y generan una alerta inmediata. Sin intento de autoservicio por IA, sin espera en L2. Las preocupaciones de seguridad van a un humano senior inmediatamente.
Señales explícitas de "cancelar" o "churn". Los tickets que contienen lenguaje sobre cancelación, comparación de compras con competidores, o expresiones de insatisfacción significativa se enrutan a un humano con contexto de CS presentado, no al soporte general. La conversación ha pasado de soporte a retención.
Estas anulaciones basadas en señales se configuran como reglas de routing, no como comportamientos aprendidos. Deben ser deterministas: si un ticket contiene una palabra clave relacionada con seguridad, se enruta a L3. Siempre.
Calidad de la Escalada: Transferencia de Contexto
El routing determina a dónde va un ticket. Pero el routing sin contexto crea una peor experiencia que con él.
Cuando la IA transfiere a un agente humano, el agente debe recibir: el historial completo de conversaciones del cliente, lo que intentó la IA (si intentó una respuesta), por qué la IA no pudo resolver (baja confianza, palabra clave marcada, nivel del cliente), los datos de la cuenta del cliente (antigüedad, ARR, health score, historial reciente de soporte), y enlaces de documentación relevantes sugeridos por la recuperación RAG.
Una transferencia en frío es cuando el cliente repite toda su pregunta al agente humano porque el agente no tiene contexto de la interacción con la IA. Las transferencias en frío dañan significativamente el CSAT. La experiencia del cliente es: ya expliqué esto a un bot, ahora tengo que explicarlo de nuevo a una persona. Eso no es una experiencia fluida. Son dos conversaciones separadas y desconectadas.
Intercom Fin preserva explícitamente el contexto de la conversación a través de las transferencias. El agente humano ve el hilo completo, lo que intentó Fin y por qué la conversación llegó a ellos. Zendesk AI pasa el contexto de la conversación junto con el ticket. Este es un requisito mínimo para un sistema de routing bien implementado: las transferencias deben ser invisibles para el cliente a medida que el contexto se transfiere.
Prevención de Cuellos de Botella en Escaladas
El modo de fallo del routing mal ajustado es un cuello de botella de escalada. Si el modelo de routing es demasiado conservador, demasiados tickets se asignan a L2 o L3 que la IA o un agente junior de L2 debería haber manejado. Los ingenieros senior pasan su tiempo en tickets que no requieren su experiencia. El tiempo de resolución aumenta en general.
Por eso la optimización del routing es una tarea operativa continua, no una configuración única.
Ejecute una auditoría de routing mensual. Extraiga los tickets de L3 del mes pasado. ¿Qué porcentaje de ellos fue categorizado correctamente en L3? De los que podrían haberse manejado en L2, ¿por qué fueron escalados? ¿Fue una intención mal clasificada? ¿Un umbral de complejidad demasiado conservador? ¿Una regla de nivel de cuenta demasiado amplia?
De la misma manera, audite los intentos de deflección de IA en L1 que escalaron. De esos, ¿qué porcentaje escaló porque el cliente indicó que la respuesta de IA era incorrecta versus porque el cliente quería un humano independientemente de la calidad de la IA? La primera categoría es una brecha de documentación. La segunda es un comportamiento de escalada aceptable.
Construya capacidad en L2 de forma proactiva. El cuello de botella de escalada más común es la capacidad insuficiente en L2. Cuando la deflección por IA está funcionando (digamos, un 40% de tickets deflectados en L1), los tickets restantes están sesgados hacia la complejidad. El ticket promedio en L2 es más difícil que el ticket promedio antes del routing con IA, porque los fáciles ahora se están deflectando. Si contrata a L2 igual que antes del despliegue de IA, los agentes están manejando tickets más difíciles al mismo volumen y se agotarán más rápido.
Planifique para esto. El routing con IA aumenta la eficiencia en L1. Concentra la complejidad en L2 y L3. La planificación de personal y especialización necesita ajustarse en consecuencia. Gartner reporta que el 91% de los líderes de servicio al cliente están bajo presión ejecutiva para implementar IA no solo para la eficiencia sino para mejorar la satisfacción, lo que significa que las decisiones de planificación de capacidad afectan directamente si el routing con IA es visto como un éxito o una responsabilidad por el liderazgo. Cómo la IA remodela el modelo operativo SaaS cubre lo que esta concentración de roles significa para la estructura del equipo a escala.
"Los sistemas de routing con IA entrenados con 6-12 meses de datos históricos de tickets alcanzan un 80-85% de precisión en la clasificación de intención en el primer despliegue. Con 3-4 meses de correcciones de producción retroalimentadas al modelo, la precisión mejora al 90%+. La mejora no es automática. Requiere una auditoría de routing mensual donde los tickets mal clasificados se etiquetan y se reenvían al entrenamiento." (Documentación de Clasificación IA de Zendesk, 2025)
"El routing con IA concentra la complejidad en L2 y L3 después de la deflección. Si la deflección en L1 está funcionando al 40%, el ticket promedio en L2 es más difícil que el ticket promedio antes de que se desplegara el routing con IA, porque los fáciles ahora se deflectan. Contratar a L2 con niveles previos a la IA mientras se esperan tasas de deflección post-IA es la ruta más rápida al agotamiento en L2 y el colapso del CSAT." (Rework Analysis, basado en investigación de IA de servicio al cliente de Gartner, 2025)
Benchmarks de Rendimiento del Routing
| Métrica de Routing | Objetivo | Umbral de Advertencia | Acción |
|---|---|---|---|
| Precisión de clasificación de intención | 85-92% | Por debajo del 80% | Reentrenar con clasificaciones incorrectas corregidas |
| Tasa de desvío en L1 (re-escalada inmediata) | Por debajo del 12% | Por encima del 15% | Ajustar los criterios de elegibilidad de L1 |
| Tiempo de primera respuesta en L2 vs. línea base pre-IA | Más rápido | Más lento | Verificar el personal de L2 y la adopción de asistencia de IA |
| Tickets de L3 clasificados correctamente | Por encima del 90% | Por debajo del 85% | Auditar las reglas de activación de escalada L2-L3 |
Fuentes: Documentación de Clasificación de Tickets IA de Zendesk 2025, Gartner Customer Service AI Benchmark 2025, Fini Labs Routing Analysis 2026
Rework Analysis: El número de precisión del modelo de routing (85-92%) frecuentemente se trata como la métrica de resultado. No lo es. El routing es correcto cuando el especialista adecuado recibe el ticket en la primera asignación, no solo cuando el sistema lo categorizó correctamente. Una disputa de facturación correctamente clasificada como "facturación" pero enrutada a un agente junior de facturación sin contexto de la cuenta está técnicamente clasificada pero operativamente incorrecta. La medición real es la tasa de resolución en la primera asignación: qué porcentaje de tickets fueron resueltos por el primer humano que los recibió, sin re-escalada. Ese número, monitoreado por nivel y tipo de ticket, le indica si el routing está funcionando operativamente o solo categorialmente.
Métricas para la Calidad del Routing
Cuatro métricas le indican si su modelo de routing está funcionando.
Tiempo de primera respuesta por nivel. La respuesta de IA en L1 debe ser casi instantánea (segundos). El L2 con asistencia humana debe ser más rápido que la línea base no asistida porque los agentes no empiezan desde cero. El L3 debe reflejar el tiempo hasta el experto, no el tiempo hasta la cola. Si el tiempo de respuesta en L2 es peor que la línea base pre-IA, el routing está creando fricción, no eficiencia.
Tasa de resolución por nivel. ¿Qué porcentaje de tickets de L1 se cierran sin escalada? ¿Qué porcentaje de tickets de L2 se cierran sin escalada a L3? Las tasas de resolución en declive en un nivel indican que el routing está enviando tickets a ese nivel que no debería estar manejando.
Tasa de desvío. Tickets asignados a L1 y luego escalados inmediatamente a L2 o L3, o tickets asignados a L2 que un agente junior escaló inmediatamente sin intentar la resolución. Son errores de routing. Una tasa de desvío superior al 15% en L1 o L2 indica que el modelo de routing necesita reentrenamiento.
Relación tasa de escalada vs. tasa de deflección. A medida que su tasa de deflección aumenta, su tasa de escalada para el grupo de tickets restante naturalmente también aumentará (porque los tickets restantes son más difíciles). Si las escaladas están creciendo más rápido que la tasa de deflección, el modelo de routing está fallando en contener la complejidad en el nivel correcto.
Conexión con el Stack de IA de Soporte
El routing multinivel es el modelo operativo que permite escalar la deflección por IA. Sin él, agregar autoservicio de IA a un help desk mal enrutado crea acumulaciones de escaladas en lugar de eficiencia. Los tickets que la IA no puede manejar se acumulan en los agentes humanos sin contexto, sin priorización y sin que el especialista correcto reciba el ticket correcto.
Agente de Soporte IA para Autoservicio en SaaS cubre la capa de IA en L1 en profundidad, incluyendo qué tipos de tickets maneja bien RAG y dónde debe ocurrir la escalada inmediatamente.
Deflección de Tickets con RAG en Soporte SaaS cubre el lado de la calidad de la deflección: cómo medir si los tickets deflectados realmente se resuelven satisfactoriamente, no solo si fueron deflectados.
Mantenimiento de Knowledge Base con IA para Docs SaaS cubre mantener la knowledge base actualizada, lo que determina si la IA en L1 puede realmente manejar los tickets que se le enrutan.
El routing multinivel con IA es la diferencia entre el autoservicio de IA que mejora su operación de soporte y el autoservicio de IA que crea nuevos problemas. La lógica de routing es sencilla. El diseño organizacional detrás de ella, la planificación de capacidad, las políticas de escalada y el ajuste continuo son donde está el trabajo real. Haga bien el modelo de routing, y la deflección por IA escala a medida que su producto crece.
Leer Más:
- Patrón de Scoring y Routing: el patrón del ACE Framework detrás de la inteligencia de routing
- Patrón RAG Assistant: la capa de autoservicio L1 a la que alimenta el routing
- Agente de Soporte IA para Autoservicio en SaaS: estructura completa de niveles para IA de soporte SaaS
- Deflección de Tickets con RAG en Soporte SaaS: métricas de calidad de deflección para tickets enrutados
- Predicción de Churn con IA en Modelos de Suscripción: cómo los datos de salud de la ventana de renovación informan las reglas de routing
- Mantenimiento de Knowledge Base con IA para Docs SaaS: mantener la knowledge base actualizada para la resolución en L1

Co-Founder, Rework.com
On this page
- Qué Significa el Routing Multinivel
- El Modelo de Triaje Intent-Tier-Context
- El Patrón de Scoring y Routing Aplicado
- Clasificación de Intención en la Práctica
- Reglas de Routing por Nivel de Cuenta
- Señales de Routing Específicas de SaaS
- Calidad de la Escalada: Transferencia de Contexto
- Prevención de Cuellos de Botella en Escaladas
- Benchmarks de Rendimiento del Routing
- Métricas para la Calidad del Routing
- Conexión con el Stack de IA de Soporte