Health Scoring mit KI für SaaS-Kunden

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Fast jedes SaaS-Unternehmen ab Series B hat einen Customer-Health-Score. Fragen Sie die CSMs (customer success managers), ob sie ihm vertrauen, und die meisten werden Ihnen sagen, dass sie ihn prüfen, wenn sie ihrem Vorgesetzten etwas begründen müssen, und dann zu ihrem Bauchgefühl zurückkehren.
Das ist das Fehlermuster des regelbasierten Health Scorings. Es ist nicht so, dass das Konzept falsch ist. Vielmehr produzieren Regeln, die gleichmäßig auf alle Accounts angewendet werden, mit Gewichtungen, die von einem Komitee festgelegt und nicht aus tatsächlichen Churn-Ergebnissen abgeleitet wurden, Scores, die technisch befüllt und praktisch nutzlos sind.
KI-Health-Scoring ist anders. Nicht weil KI Magie ist, sondern weil das Modell darauf trainiert ist, was tatsächlich mit Accounts wie diesem passiert ist, nicht darauf, was ein Product Manager vermutet hätte, dass es wichtig ist.
Regelbasiertes vs. KI-Health-Scoring
Ein regelbasierter Health Score sieht typischerweise so aus: Wenn NPS (net promoter score) über 8 ist, die Login-Häufigkeit über viermal pro Woche liegt und der Account auf die letzten drei CSM-E-Mails geantwortet hat, Score grün. Sonst gelb. Wenn sie eine Stornierungsanfrage gestellt haben, rot.
Dieser Ansatz hat zwei Probleme.
Key Facts: KI-Health-Scoring für SaaS
- Unternehmen, die ausnahmebasierte CS-Modelle implementieren (bei denen KI gefährdete Accounts kennzeichnet und CSMs nur gekennzeichnete Accounts behandeln), berichten von 25-40 % höheren Retention-Raten und einem 3-5-fachen ROI auf Customer-Success-Headcount gegenüber manuellem Monitoring (Benchmarkit 2025 SaaS Performance Metrics)
- KI-Churn-Modelle, die auf 80+ Verhaltens-Signalen trainiert werden, erzielen 75-82 % Vorhersagegenauigkeit; die größten Genauigkeitssteigerungen 2025-2026 kamen durch das Hinzufügen von LLM-basierten Sentiment-Embeddings, die Phrasen wie "Wir evaluieren Optionen" als 4-6x wahrscheinlicher zum Churnen innerhalb von 90 Tagen erkennen (Arete SaaS Research, 2025)
- 70 % der SaaS-Unternehmen glauben, dass KI für ihre Retention-Strategie entscheidend ist, und der Markt ist über Pilotphasen hinaus in die vollständige CS-KI-Implementierung übergegangen, was KI-Health-Scoring innerhalb von 18 Monaten zu einer operativen Baseline macht (EverAfter Customer Churn Research, 2025)
Erstens sind die Gewichtungen willkürlich. Jemand hat entschieden, dass NPS 30 Punkte wert ist und Login-Häufigkeit 20 Punkte. Diese Gewichtungen wurden nicht aus einer Churn-Geschichte abgeleitet. Sie spiegeln die Überzeugungen des Teams darüber wider, was wichtig ist, was mit der Realität übereinstimmen kann oder auch nicht.
Zweitens behandeln Regeln alle Accounts gleich. Ein Enterprise-Account mit 500 Nutzern, die zweimal pro Woche einloggen, könnte tief in Ihr Produkt als tägliches Workflow-Tool eingebettet sein. Ein Startup mit 10 Nutzern, die täglich einloggen, könnte Ihr Produkt gegen einen Wettbewerber evaluieren. Das rohe Signal sieht entgegengesetzt aus zu dem, was das Risiko tatsächlich ist.
KI-Health-Scoring trainiert auf Ihrer tatsächlichen Churn-Geschichte. Das Modell lernt, welche Signale, in welchen Kombinationen, bei welchen Accounts, Churn-Ergebnissen vorausgingen. Die Gewichtungen werden aus Daten abgeleitet, nicht aus internen Meinungen darüber, was wichtig sein sollte. Forschung zur Verhaltensmodellierung für Churn-Vorhersage bestätigt, dass Nutzungsmuster-Signale, die auf tatsächlichen Ergebnissen trainiert wurden, regelbasierte Schwellenwerte übertreffen, wobei die Modellgenauigkeit mit wachsendem Trainingssatz deutlich steigt.
Das Ergebnis ist ein Score, den CSMs tatsächlich hinterfragen können: nicht nur eine grüne oder rote Kennzeichnung, sondern ein Begründungscode, der sagt "Die Support-Ticket-Stimmung dieses Accounts hat sich in den letzten 45 Tagen verschlechtert, und historisch hat dieses Muster bei ähnlich großen Accounts in 68 % der Fälle zu Churn geführt."
Der Mechanismus, der das möglich macht, ist der Anomaly Agent, der kontinuierlich im Hintergrund läuft.
Das Anomaly-Agent-Pattern darunter
Die richtige Art, über KI-Health-Scoring im ACE Framework nachzudenken, ist als kontinuierlicher Anomaly Agent. Das Modell bewertet Accounts nicht einmal im Monat und aktualisiert ein Dashboard. Es ingestiert einen kontinuierlichen Signal-Stream, etabliert Baselines für normales Verhalten bei jedem Account und kennzeichnet, wenn Verhalten von dieser Baseline auf eine Weise abweicht, die historisch mit Churn-Risiko korreliert.
Das Anomaly-Agent-Pattern läuft: Ingest (kontinuierliche Signale) dann Analyze (Abweichung von accountspezifischer Baseline) dann Predict (Churn-Risikoänderung) dann Execute (Workflow oder Alert auslösen). Das unterscheidet sich von schwellenwertbasierten Alerts, weil die Baseline accountspezifisch ist. Ein 20-prozentiger Rückgang der Login-Häufigkeit bei einem Account, der typischerweise hohes tägliches Engagement hat, ist ein stärkeres Signal als derselbe Rückgang bei einem Account, der immer niedrige Häufigkeit hatte.
Diese Account-Spezifität ist das, was KI-Health-Scoring genauer macht als Regeln. Und es ist das, was es schwieriger zu implementieren macht: Sie benötigen genug historische Daten pro Account-Typ, um bedeutungsvolle Baselines zu etablieren.
Die Signale, die Sie in dieses Modell einspeisen, bestimmen, wie genau und handlungsrelevant das Ergebnis ist.
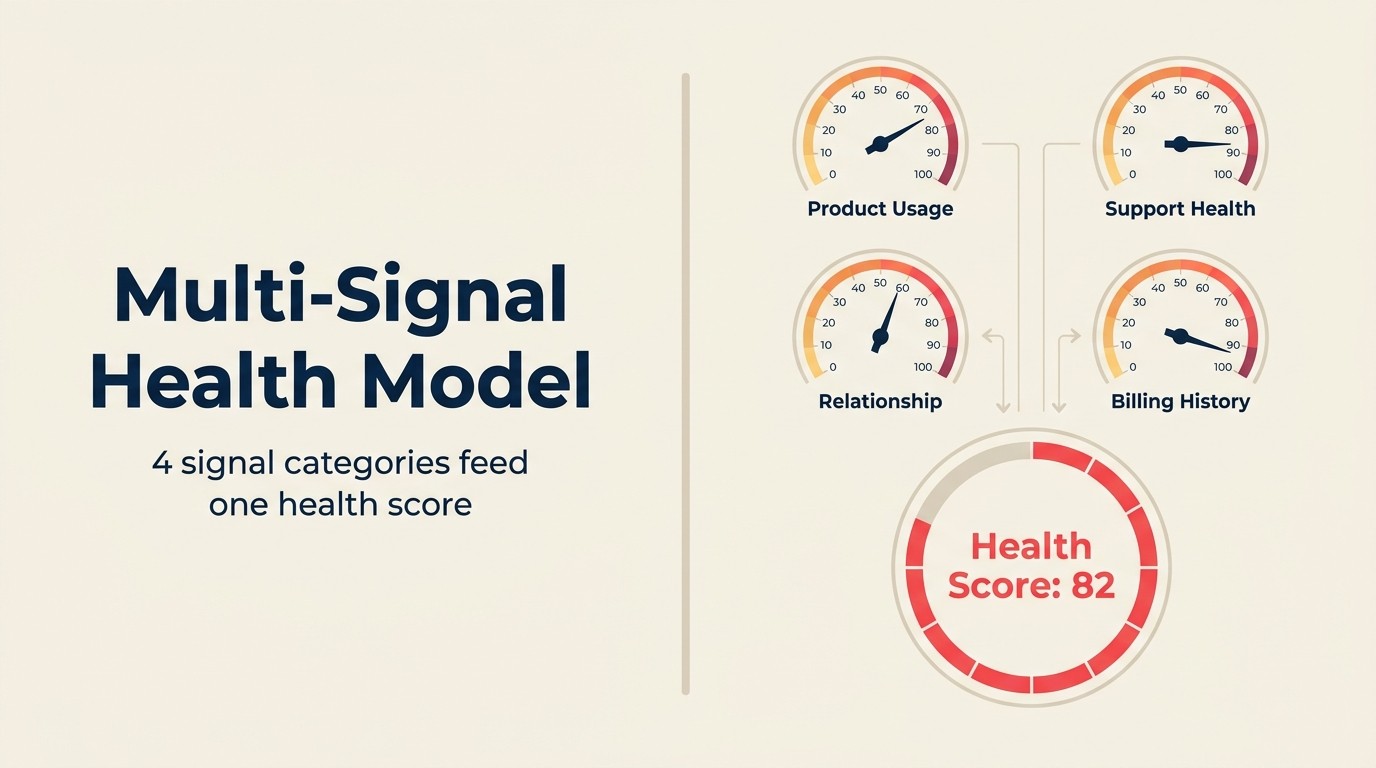
Das Multi-Signal-Health-Modell
Das Multi-Signal-Health-Modell ist das Framework für KI-Health-Scoring, das Scores produziert, denen CSMs tatsächlich vertrauen: Kombination von Nutzungssignalen (Produktverhaltens-Trends relativ zur accountspezifischen Baseline), Beziehungssignalen (Call-Sentiment, CSM-Antwortquoten, Champion-Stabilität), kommerziellen Signalen (Rechnungstiming, Vertragsauslastung, Pricing-Tier-Passung) und Support-Sentiment-Signalen (Ticket-Volumen-Trend, Eskalationsrate, Zufriedenheit) in einen zusammengesetzten Score mit sichtbaren Begründungscodes. Jede Signal-Kategorie trägt unabhängig bei, und Gewichtungen werden aus tatsächlichen Churn-Ergebnissen in Ihrer Account-Geschichte abgeleitet, nicht aus Annahmen eines Komitees. Das Modell läuft als kontinuierlicher Anomaly Agent: Erkennt Abweichungen von accountspezifischen Baselines in Echtzeit statt wöchentliche Dashboard-Scores neu zu berechnen. Der praktische Test eines guten Multi-Signal-Health-Modells: CSMs sollten in der Lage sein, die Begründungscodes zu lesen und sofort zu verstehen, warum ein Account die Farbe gewechselt hat und welche Maßnahme zu ergreifen ist.
Signal-Kategorien und was sie tatsächlich vorhersagen
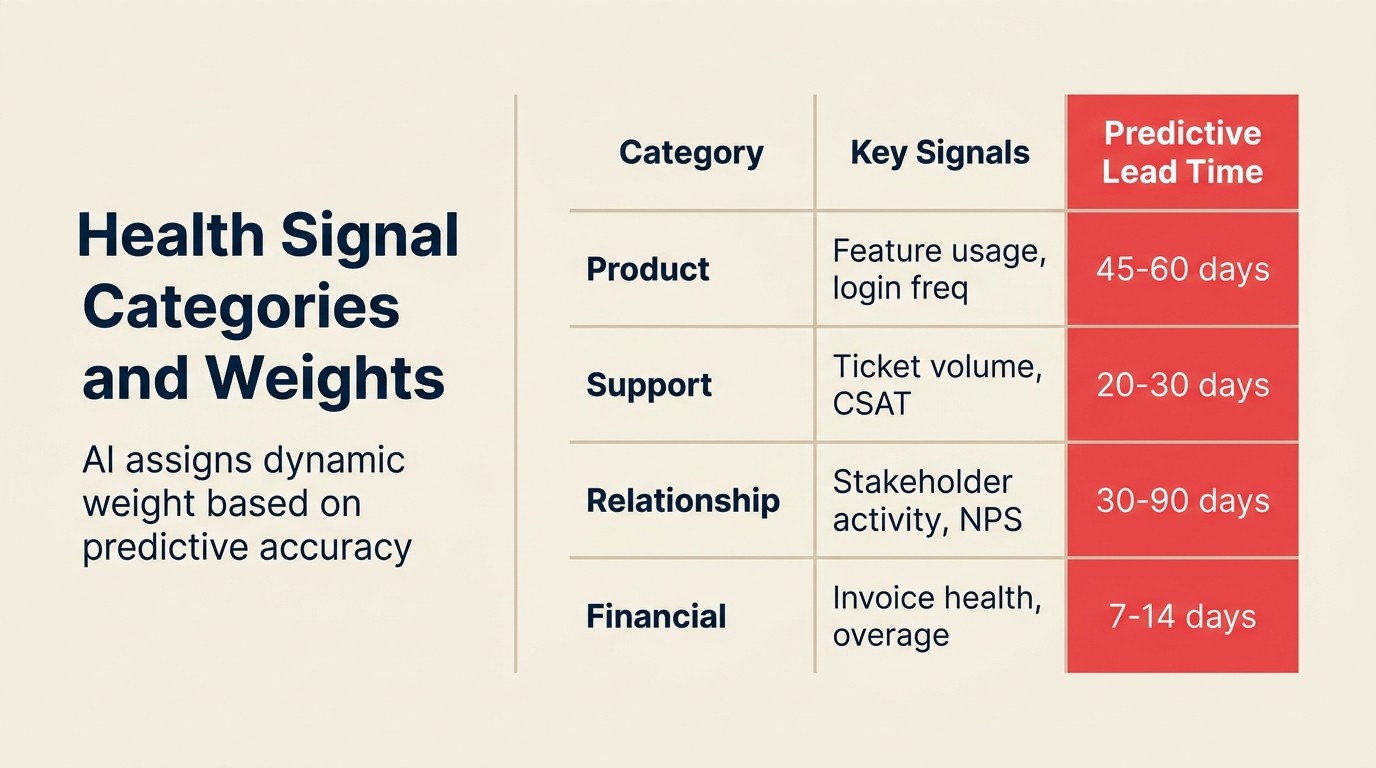
Nicht alle Signale tragen gleich viel Gewicht, und die Gewichtungen variieren je nach Produkttyp und Kundensegment. So denken Sie über die vier Hauptkategorien nach.
Produktnutzungs-Signale. Bei PLG (Product-Led Growth)-Unternehmen und Tools, bei denen tägliche aktive Nutzung erwartet wird, tragen diese Signale das höchste Gewicht. Login-Häufigkeit, Feature-Adoptionsbreite, aktive Workflows, API-Call-Volumen-Trends und Kollaborationsindikatoren (Anzahl aktiver Teammates) sind die stärksten Inputs. Der Schlüssel ist Trend, nicht absoluter Level. Ein Account, dessen Nutzung seit 60 Tagen sinkt, ist riskanter als ein Account auf demselben absoluten Nutzungsniveau, das flat ist.
Beziehungsqualitätssignale. Diese zählen am meisten für High-Touch-Enterprise-Accounts. Call-Häufigkeit, CSM-Antwortquoten, QBR-Abschluss, NPS-Scores und Sentiment aus Call-Transkripten. Wenn ein Champion still geworden ist, ist das ein Signal. Wenn CSM-Anrufe konsequent neu terminiert werden, ist das ein Signal. Meeting Intelligence (aus dem ACE Framework) kann Call-Aufzeichnungen analysieren, um Sentiment über Zeit zu bewerten und zu kennzeichnen, wenn der Ton von engagiert zu transaktional gewechselt hat.
Kommerzielle Health-Signale. Rechnungszahlungstiming, Nutzung relativ zu Vertragslimits, Anzahl von Support-Tickets, die Pricing oder Vertragsbedingungen in Frage stellen, und Initiierung von Erneuerungsgesprächen. Das sind nachlaufende Signale statt führende Indikatoren, aber sie sind hochpräzise: Ein Account, der beginnt, Posten in der Rechnung in Frage zu stellen, ist viel wahrscheinlicher zu churnen als ein Account, der pünktlich zahlt.
Support-Sentiment-Signale. Ticket-Volumen-Trend, Eskalationsrate, Ton des offenen Ticket-Texts, Zufriedenheitsbewertungen der Lösungszeit und ob Tickets Produktprobleme oder Erstattungsanfragen und Kündigungen betreffen. Ein rascher Anstieg der Support-Tickets in Kombination mit niedrigen Zufriedenheitsbewertungen ist einer der stärksten kurzfristigen Churn-Prädiktoren.
Aber Sie können diese Signale nur verwenden, wenn Sie die Trainingsdaten haben, um sie gegen Ihre eigene Churn-Geschichte zu kalibrieren.
Das Trainings-Set aufbauen
Hier bleiben die meisten Teams stecken: KI-Health-Scoring erfordert historische Daten zum Trainieren, und nicht irgendwelche Daten.
Um ein bedeutungsvolles Churn-Vorhersagemodell zu trainieren, benötigen Sie typischerweise 2 bis 3 Jahre Account-Geschichte und mindestens 100 gechurnte Accounts im Trainings-Set. Das Modell muss lernen, wie Churn über Account-Typen, Größen und Produktnutzungsmuster hinweg aussieht. Wenn Ihre Churn-Basis zu klein oder zu homogen ist, wird das Modell overfitting betreiben und sich nicht gut auf die Accounts in Ihrem aktuellen Portfolio verallgemeinern. ChartMoguls SaaS-Retention-Benchmarks bieten nützliche Branchenbaselines dafür, wie Churn-Raten bei verschiedenen ARR (annual recurring revenue)-Phasen aussehen, was Ihre eigenen historischen Daten ergänzen kann, wenn Ihr Trainings-Set noch aufgebaut wird.
Wenn Sie diese Daten noch nicht haben, ist der richtige Schritt nicht, KI-Health-Scoring zu überspringen. Es ist, jetzt mit gut konzipierten regelbasierten Scores zu beginnen, jedes Signal, das Sie verfolgen, zu protokollieren und das Trainings-Daten-Set systematisch aufzubauen. Dokumentieren Sie, wann Accounts churnen und wie ihre Signal-Geschichte in den 90 Tagen davor aussah. In 18 Monaten haben Sie die Daten, um den Übergang zu KI-basiertem Scoring bedeutsam zu machen.
Gainsights KI-Health-Scoring funktioniert so: Es kann mit Gainsights eigenen Benchmark-Daten (abgeleitet aus Churn-Mustern über ihre Kundenbasis) beginnen und sich dann progressiv an Ihre spezifischen historischen Muster anpassen, wenn diese Daten akkumulieren. Planhat verwendet einen Daten-Modell-Ansatz, bei dem Sie die Signal-Architektur definieren und das Modell auf Ihrer eigenen Account-Geschichte trainiert wird. ChurnZero verwendet benchmark-basiertes Scoring, das Ihre Accounts gegen Branchenbenchmarks für ähnliche Unternehmensphasen vergleicht, was nützlich ist, wenn Sie noch nicht genug eigene Churn-Geschichte haben.
Selbst ein gut trainiertes Modell schafft ein Problem, wenn die Scores selbst falsches Vertrauen erzeugen.
Das False-Confidence-Problem
Ein Health Score, der Accounts als grün vorhersagt, die anschließend churnen, ist schlimmer als kein Score. Er gibt CSMs (und CS-Leadership) falsches Vertrauen, was zu Unterinvestition in gefährdete Accounts während des Fensters führt, in dem Intervention noch funktioniert hätte.
Die zu verfolgende Metrik ist Präzision bei roten Klassifikationen: Wenn das Modell rot sagt, wie oft stimmt das? Ein Modell, das 100 Accounts rot kennzeichnet und 80 davon tatsächlich churnen (80 % Präzision), ist weit handlungsrelevanter als ein Modell, das 100 Accounts rot kennzeichnet und 40 davon churnen.
Es gibt hier einen Kompromiss. Hohe Präzision bei roten Flags bedeutet, dass Sie nur Alarm schlagen, wenn Sie sicher sind, was bedeutet, dass einige Accounts, die tatsächlich gefährdet sind, nicht gekennzeichnet werden. Hoher Recall bedeutet, mehr gefährdete Accounts zu kennzeichnen, aber auch mehr False Alarms zu generieren, die die CSM-Arbeitsbelastung erhöhen und das Vertrauen in den Score erodieren.
Für die meisten CS-Teams mit begrenzter Kapazität ist Präzision wichtiger als Recall. Eine kleinere Anzahl von wirklich hochrisikoreichen Flags, die zuverlässig Churn vorhersagen, ist nützlicher als eine umfassende Liste, bei der CSMs die echten Signale nicht vom Rauschen unterscheiden können.
Testen Sie Ihr Modell regelmäßig gegen tatsächliche Ergebnisse. Nehmen Sie eine Kohorte von Accounts, die vor sechs Monaten als grün bewertet wurden. Wie viele churnte? Nehmen Sie eine Kohorte, die als rot bewertet wurde. Wie viele erneuerten? Diese Backtests sagen Ihnen, ob das Modell tatsächlich Ergebnisse vorhersagt oder nur nachlaufendes Verhalten misst.
Modellgenauigkeit ist eine Voraussetzung. Aber CSMs dazu zu bringen, auf den Score zu handeln, ist das schwierigere Problem.
CSM-Vertrauen und Adoption
Ein Health Score, den CSMs ignorieren, liefert null Wert. Die Adoption zu erreichen, erfordert die Lösung eines Vertrauensproblems, nicht eines Technologieproblems.
CSMs misstrauen Health Scores aus drei spezifischen Gründen. Erstens sagt der Score eine Sache, und ihr Beziehungsgefühl sagt eine andere, und der Score wird nie aktualisiert, wenn sie eine Korrektur einreichen. Zweitens ändert sich der Score ohne Erklärung: Ein Account wechselt über Nacht von gelb zu rot, und es gibt keinen Begründungscode. Drittens, wenn der Score falsch liegt, verschwendet er ihre Zeit mit der Verfolgung von Accounts, die keine Aufmerksamkeit brauchen.
Jedes dieser Probleme ist lösbar.
Machen Sie die Begründungscodes sichtbar. Nicht nur "Rot wegen gefallener Nutzung", sondern "Die Login-Häufigkeit dieses Accounts ist in den letzten 30 Tagen um 45 % gesunken, und Accounts in diesem Profil, die dieses Muster zeigen, churnen innerhalb von 90 Tagen mit einer historischen Rate von 72 %." CSMs, die die Belege hinter dem Score sehen können, werden sich damit beschäftigen statt ihn still zu überschreiben.
Bauen Sie einen Override-Mechanismus ein. CSMs sollten einen Score als ungenau kennzeichnen und einen Begründungscode hinzufügen können. Diese Overrides werden zu Trainingsdaten. Wenn ein CSM konsequent Accounts mit niedriger Nutzung als grün kennzeichnet und sie konsequent erneuern, lernt das Modell, dass niedrige Nutzung bei diesem Account-Typ kein Churn-Signal ist.
Führen Sie vierteljährliche Kalibrierungssitzungen durch. Bringen Sie das CS-Team zusammen, gehen Sie durch Accounts, bei denen das Modell recht und unrecht hatte, und diskutieren Sie die Muster. Das baut gemeinsames Verständnis dafür auf, was das Modell tut, und baut Vertrauen durch Transparenz auf.
Vertrauen bringt Adoption. Adoption zählt nur, wenn der Score zu Handlungen führt.
Health Score als Workflow-Trigger
Die wichtigste Denkverschiebung beim Health Scoring ist diese: Der Score ist keine Dashboard-Metrik. Er ist ein Workflow-Input.
Ein Übergang von Grün zu Gelb sollte automatisch eine CSM-Aufgabe auslösen: "Account X hat sich auf gelb verschoben. Nutzungsdaten überprüfen und Check-in innerhalb von 5 Werktagen planen." Ein Übergang von Gelb zu Rot sollte eine Eskalation auslösen: CS-Lead-Review, Executive-Sponsor-Outreach-Option, Initiierung eines Save-Plays.
Ohne diese Workflow-Integration ist der Health Score eine Zahl in einem Dashboard, die jemand vor einem Board-Meeting anschaut. Mit ihr generiert jedes Risikosignal eine Handlung.
Bauen Sie zuerst das Save-Play, dann aktivieren Sie die Health-Score-Trigger. Der häufigste Implementierungsfehler ist das Aktivieren von Health Scoring, bevor der Response-Workflow existiert, was bedeutet, dass wenn ein Account rot wird, niemand weiß, was zu tun ist. Das System hat das Risiko korrekt identifiziert und dann ist nichts passiert.
KI Churn-Vorhersage in Subscription-Modellen behandelt die prädiktive Modellierungsschicht in größerer Tiefe, einschließlich Kohorten-Level-Vorhersagen und der kommerziellen Mathematik hinter dem Interventions-Timing.
Der Produkttelemetrie-Vorteil in SaaS-KI behandelt, warum SaaS-Unternehmen einen strukturellen Datenvorteil für Health Scoring haben, den andere Branchen nicht haben: Das Produkt selbst generiert in Echtzeit die prädiktivsten Signale.
Verbindung zum breiteren CS-Stack
Health Scoring ist das Fundament. Expansions-KI (behandelt im Begleitartikel zu Upsell und Cross-Sell) baut darauf auf. Sie müssen wissen, dass ein Account gesund ist, bevor Sie ein Expansionsgespräch vorantreiben. Ein Account, der sich bei Health auf Gelb-zu-Rot befindet, sollte keinen Expansions-Outreach erhalten.
AI Customer Success Manager für B2B-SaaS behandelt, wie Health Scoring mit QBR-Vorbereitung, Expansion Plays und Renewal-Workflow-Automatisierung als vernetztes CS-Intelligence-System integriert.
Wie gut es aussieht
Eine ausgereifte KI-Health-Scoring-Implementierung bei einem SaaS-Unternehmen mit 200 Enterprise-Accounts sieht ungefähr so aus: Jeder Account hat einen täglich aktualisierten Health Score. Der Score kommt mit drei bis fünf Begründungscodes, die die primären Signale erklären, die ihn getrieben haben. CSMs haben eine Warteschlange von gekennzeichneten Übergängen, die heute, diese Woche und diesen Monat Maßnahmen erfordern. Jede Save-Play-Interaktion wird zurück in das System als Trainingsdaten protokolliert. Gartners 2025 Customer-Service-Forschung zeigt, dass 85 % der Customer-Service-Leader 2025 KI testen oder einsetzen werden, was operative Reife in KI-unterstütztem CS innerhalb von 18 Monaten zu einer wettbewerblichen Baseline, nicht zu einem Differenzierungsmerkmal macht.
Zweimal pro Jahr führt das CS-Ops-Team ein Backtest durch, das Scores von vor sechs Monaten mit tatsächlichen Churn- und Erneuerungsergebnissen vergleicht. Wenn die Präzision unter den vereinbarten Schwellenwert fällt, wird das Modell neu trainiert.
NRR (net revenue retention)-Verbesserung aus diesem System ist messbar: nicht weil der Score Magie ist, sondern weil er sicherstellt, dass kein hochrisikoreicher Account unbemerkt im 90-Tage-Fenster bleibt, wenn proaktiver Outreach noch funktioniert.
Bauen Sie den Score, dem CSMs vertrauen. Verbinden Sie ihn mit Workflows, die sie tatsächlich nutzen. Dann messen Sie, ob er die richtigen Accounts vorhersagt. Alles andere sind Implementierungsdetails. Für den breiteren Kontext zu wie KI das SaaS-Betriebsmodell neu gestaltet, sehen Sie die Diskussion zum CSM-zu-ARR-Verhältnis.
Das Hinzufügen von Support-Sentiment-Signalen zu einem Health-Modell -- speziell LLM-basierte Analyse von Support-Ticket- und Call-Transkript-Sprache -- produziert konsequent die größten Genauigkeitsverbesserungen in 2025-2026-Deployments. Accounts, bei denen Kunden Phrasen wie "Wir evaluieren Optionen" oder "Wir sehen den von uns erwarteten ROI nicht" verwenden, churnen mit 4-6-facher Wahrscheinlichkeit innerhalb von 90 Tagen. Reine Nutzungsmodelle können dieses Signal nicht erkennen. Nur Modelle mit Zugang zu Gesprächsdaten können das. (Arete SaaS Research, 2025)
Rework-Analyse: Der konsistenteste Implementierungsfehler, den wir beobachten, ist das Aufbauen des Health-Scoring-Dashboards vor dem Aufbauen des Save-Play-Workflows. Teams begeistern sich für die Health-Visualisierung, aktivieren die Alerts und haben dann keine definierte Reaktion, wenn ein Account rot wird. CSMs sehen den Alert, sind unsicher, was zu tun ist, tun nichts, und der Account churnt. Das System hat das Risiko korrekt identifiziert. Die Menschen waren nicht bereit zu handeln. Die Sequenz, die funktioniert: Zuerst den Save-Play-Workflow entwerfen (was tun wir, wenn Health rot wird?), ihn manuell mit fünf gefährdeten Accounts testen, dann die KI-Health-Alerts aktivieren, um diesen Workflow automatisch auszulösen. Das System nach Save-Play-Ausführungsrate bewerten, nicht nach Alert-Volumen.
| Signal-Kategorie | Gewicht | Beispiele | Vorhersage-Vorlaufzeit |
|---|---|---|---|
| Produktnutzungs-Signale | Höchstes (für PLG und täglich genutzte Tools) | Login-Häufigkeitstrend, Feature-Adoptionstiefe, API-Call-Volumen, Kollaborationsbreite | 3-8 Wochen |
| Beziehungs-Signale | Höchstes für Enterprise-Accounts | Call-Sentiment-Trend, CSM-Antwortquoten, QBR-Abschluss, Champion-Stabilität | 4-8 Wochen |
| Kommerzielle Signale | Hochpräzise aber nachlaufend | Rechnungszahlungstiming, Nutzung vs. Vertragslimits, Initiierung von Pricing-Tier-Gesprächen | 1-3 Wochen |
| Support-Sentiment | Gemischt (führend für Frustration, nachlaufend für Kündigung) | Ticket-Volumen-Trend, CSAT-Rückgang, Eskalationsrate, Ticket-Sprachanalyse | 2-6 Wochen |
Quelle: Gainsight, ChurnZero, Planhat, Arete SaaS Research (2024-2025)
Verwandte Artikel:

Co-Founder, Rework.com
On this page
- Regelbasiertes vs. KI-Health-Scoring
- Das Anomaly-Agent-Pattern darunter
- Das Multi-Signal-Health-Modell
- Signal-Kategorien und was sie tatsächlich vorhersagen
- Das Trainings-Set aufbauen
- Das False-Confidence-Problem
- CSM-Vertrauen und Adoption
- Health Score als Workflow-Trigger
- Verbindung zum breiteren CS-Stack
- Wie gut es aussieht