KI-Support-Agent für SaaS-Self-Service

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
SaaS-Support hat ein spezifisches Problem, das generische KI-Chatbots nicht lösen. Ihre Kunden fragen nicht, wo das Badezimmer ist. Sie fragen, warum ihre Webhook-Integration bei hohen Payload-Volumen sporadisch fehlschlägt, was der Unterschied zwischen rollenbasierter Berechtigung und attributbasierter Zugriffskontrolle in Ihrem Enterprise-Tier ist, oder warum ihr Export nach Salesforce seit dem letzten Release Felder falsch zuordnet.
Generische Large Language Models, die auf öffentlichen Internetdaten trainiert wurden, können produktspezifische Fragen nicht genau beantworten. Sie liefern eine selbstsichere Antwort, die plausibel, aber falsch ist, was schlimmer ist als "ich weiß es nicht", weil der Kunde danach handelt.
Die KI-Support-Agenten, die in SaaS tatsächlich funktionieren, sind anders aufgebaut. Sie basieren auf einem Retrieval-Augmented Generation (RAG)-Ansatz als Kern: Die KI rät nicht aus Trainingsdaten. Sie ruft aus Ihren Dokumentationen ab.
Der KI-Support-Agent definiert
Im ACE Framework kombiniert ein KI-Support-Agent drei Muster: RAG Assistant (Produktwissensabruf), Scoring and Routing (Ticket-Triage und Tier-Zuweisung) und Workflow Copilot (Agent Assist für menschlich bearbeitete Tickets).
Der RAG Assistant steht in der ersten Reihe. Er empfängt eine eingehende Frage, ruft die relevanteste Dokumentation oder eine frühere Ticket-Lösung aus Ihrer Wissensbasis ab und generiert eine Antwort, die auf diesem abgerufenen Inhalt basiert. Der Kunde erhält eine genaue, spezifische Antwort, ohne ein Ticket zu öffnen.
Scoring and Routing übernimmt die Fälle, die der RAG Assistant nicht sicher lösen kann. Das Ticket wird nach Komplexität, Kunden-Tier und Übereinstimmungsqualität mit der Wissensbasis bewertet und dann mit angehängtem Kontext an den geeigneten menschlichen Agenten weitergeleitet.
Der Workflow Copilot arbeitet auf Tier-1-menschlicher Bearbeitungsebene: Der Agent erhält einen vorgeschlagenen Antwortentwurf aus der Wissensbasis, eine Zusammenfassung der Kontoverlaufs des Kunden und relevante Dokumentationslinks. Er überprüft, bearbeitet und sendet, anstatt von Grund auf zu starten.
Intercom Fin funktioniert so. Wenn ein Kunde eine Nachricht sendet, durchsucht Fin die verbundene Wissensbasis, generiert eine Antwort und löst das Gespräch entweder oder übergibt es mit erhaltenem Kontext an einen Menschen. Zendesk AI führt ähnliche Deflektionslogik durch seine KI-Agenten-Ebene aus. Dialpad AI konzentriert sich auf die Seite der Human-Agent-Unterstützung und zeigt relevante Informationen in Echtzeit während Live-Support-Interaktionen an.
Key Facts: KI-Support-Agenten in SaaS
- Die mediane Tier-1-Deflektionsrate über Enterprise-Kundenerfahrungsprogramme beträgt 2026 41,2 %, wobei Top-Quartil-Deployments 58,7 % erreichen (Zendesk/Salesforce-Benchmarks, 2026)
- KI-Agenten auf Basis von Generative AI erreichen 92 % Genauigkeit beim Verstehen der Kundenabsicht, gegenüber 65-70 % für ältere schlüsselwortbasierte Bots (AI Business Weekly, 2026)
- 61 % der Kunden bevorzugen Self-Service für einfache Probleme statt einen Live-Agenten zu kontaktieren, aber heute werden nur 14 % der Kundenservice-Probleme vollständig durch Self-Service gelöst, was die Dokumentationslücke aufzeigt (Salesforce 2025, Gartner)
Das L0-L1-L2-SaaS-Support-Tier
Das L0-L1-L2-SaaS-Support-Tier ist ein dreistufiges Lösungsmodell, das für SaaS-Produkte mit RAG-basierter KI entwickelt wurde. L0 ist vollständiger KI-Self-Service: Der RAG-Agent ruft ab und antwortet aus der Wissensbasis ohne menschliche Beteiligung. L1 ist KI-unterstützte menschliche Bearbeitung: Ein menschlicher Agent erhält den Antwortversuch der KI, abgerufene Dokumentation und Account-Kontext, überprüft dann, bearbeitet und sendet. L2 ist Experten-Eskalation: Komplexe, sensible oder High-Annual-Recurring-Revenue-(ARR)-Tickets leiten direkt an einen Spezialisten weiter, mit vollständig KI-zusammengefasstem Kontext. Jeder Tier hat explizite Eintrittskriterien, Austrittskriterien und Übergabebedingungen, um Eskalationsengpässe und Cold Transfers zu verhindern.
Warum RAG das Kernmuster ist
Der Grund, warum RAG für SaaS-Support funktioniert, wo generische Chatbots scheitern, liegt in der Verankerung. Ein Large Language Model, das auf dem Internet trainiert wurde, weiß ungefähr, wie SaaS-Produkte typischerweise funktionieren. Es weiß nicht, wie Ihr Produkt funktioniert, was Ihre aktuellen Fehlercodes bedeuten, wie Ihre spezifische Integration sich verhält oder was sich in Ihrem v3.2-API-Release geändert hat.
RAG Assistant Pattern: Ingest (Kundenfrage), dann Analyze (aus Wissensbasis abrufen), dann Generate (Antwort mit abgerufenem Inhalt). Der abgerufene Inhalt ist die Quelle der Wahrheit. Die Generierungsebene formatiert und erklärt ihn. AI Knowledge Base Maintenance for SaaS erklärt, wie man diesen Abruf-Corpus aktuell hält, wenn sich Ihr Produkt weiterentwickelt.
Das bedeutet, dass die Qualität Ihres KI-Support-Agenten direkt proportional zur Qualität Ihrer Wissensbasis ist. Wenn Ihre Dokumentation aktuell, spezifisch und gut strukturiert ist, gibt der Abrufschritt den richtigen Inhalt zurück und die generierte Antwort ist genau. Wenn Ihre Dokumentation veraltet, unvollständig oder schlecht organisiert ist, gibt der Abruf irrelevante Inhalte zurück und die Antwort ist falsch, auch wenn sie selbstsicher klingt.
Das ist die Investition, die vor dem KI-Tool kommt: Dokumentationsqualität. Die meisten SaaS-Unternehmen unterschätzen das und sind enttäuscht, wenn ihre Deflektionsraten bei 15-20 % statt der erwarteten 40-50 % liegen. Die Lücke wird durch Gartner-Forschung bestätigt, die zeigt, dass heute nur 14 % der Kundenservice-Probleme vollständig im Self-Service gelöst werden, vor allem weil der Wissensinhalt hinter Self-Service-Tools unvollständig ist.
Tier-Struktur für SaaS-Support

Ein gut gestaltetes KI-Support-System hat unterschiedliche Tiers mit klaren Übergabebedingungen.
Tier 0: KI-Self-Service-Lösung. Der RAG Assistant bearbeitet das Ticket vollständig, ohne menschliche Beteiligung. Der Kunde stellt eine Frage, erhält eine genaue Antwort und die Interaktion schließt als gelöst. Das ist die Deflektionsrate, die Sie anstreben. Für ein gut dokumentiertes SaaS-Produkt mit klaren Tier-0-Kandidaten sind realistische Deflektionsraten 30 bis 50 %. Ansprüche von 70 %+ spiegeln typischerweise enge Ticket-Scopes (nur bestimmte Produktbereiche für KI aktiviert) oder aggressive Lösungszählung (Gespräche als gelöst markieren, die kurz danach eskaliert wurden) wider.
Tier 1: KI-unterstützter menschlicher Agent. Der RAG Assistant hat eine Lösung versucht, aber der Kunde hat signalisiert, dass es nicht geholfen hat, oder der Konfidenzwert lag unter der Eskalationsschwelle. Ein menschlicher Agent übernimmt das Ticket mit dem Antwortversuch der KI, der abgerufenen Dokumentation und dem bereits aufgezeigten Account-Kontext des Kunden. Der Agent überprüft, was die KI versucht hat, korrigiert bei Bedarf und antwortet.
Tier 2: Spezialist mit KI-Zusammenfassung. Komplexe technische Probleme, Fehlerberichte, die eine Untersuchung erfordern, oder sensible Account-Situationen (Abrechnungsstreitigkeiten, potenzielle Churn-Gespräche) leiten an einen Spezialisten weiter. Die KI hat bereits die jüngste Ticket-Geschichte des Kunden, den Account-Status und den aktuellen Problemkontext zusammengefasst. Der Spezialist übernimmt ein eingebrieftes Ticket, kein leeres.
Diese Tier-Struktur ist das, was effektive KI-Support-Deployments von Chatbots trennt, die Kunden nerven. Der Eskalationspfad ist genauso wichtig wie die Deflektionsrate. Aber welche Ticket-Typen gehören tatsächlich in welchen Tier?
Was KI im SaaS-Support gut bewältigt
Bestimmte Ticket-Typen haben hohe Deflektionsraten, weil die Antwort klar dokumentiert ist und die Frage eng mit vorhandenem Inhalt übereinstimmt.
"Wie mache ich X?"-Fragen sind die stärksten Tier-0-Kandidaten. Eine Integration einrichten, eine Berechtigung konfigurieren, eine bestimmte Einstellung finden, einen Workflow verstehen. Diese Fragen haben korrekte, dokumentierbare Antworten, die keine Account-Untersuchung erfordern.
Fehlercodeerkärungen funktionieren gut, wenn die Dokumentation bestimmte Fehler mit klaren Lösungsschritten abdeckt. "Was bedeutet Fehler 403 in der API-Antwort und wie behebe ich ihn?" ist ein Tier-0-Kandidat, wenn dieser Fehlercode eine eigene Dokumentationsseite hat.
Plan-Vergleichsfragen (was ist der Unterschied zwischen Starter und Standard, was erhalte ich beim Upgrade) sind klares Tier-0-Terrain, da es sich um sachliche Produktfragen mit eindeutigen Antworten handelt.
Integrations-Setup-Leitfäden für gängige Integrationen (Salesforce, Slack, Zapier) lösen sich gut über RAG, da diese Leitfäden typischerweise der am gründlichsten dokumentierte Inhalt in einem SaaS-Help-Center sind.
Was KI im SaaS-Support schlecht bewältigt
Genauso wichtig ist zu wissen, wo sofort an Menschen weitergeleitet werden sollte, anstatt eine KI-Lösung zu versuchen.
Fehler-Untersuchungen erfordern einen Menschen. Wenn ein Kunde unerwartetes Verhalten meldet, das produktbezogen erscheint, erfordert die Diagnose Zugang zu Logs, Engineering-Review und manchmal Account-Ebene-Untersuchung, die die KI nicht durchführen kann.
Datenschutzanfragen (DSGVO-Datenexporte, Löschanfragen, Zugriffsanfragen) müssen von einem Menschen mit Account-Zugriff und rechtlichem Bewusstsein bearbeitet werden. Das sind keine Dokumentationsabruf-Aufgaben.
Abrechnungsstreitigkeiten und Vertragsfragen erfordern Account-Ebene-Kontext und beinhalten oft Ermessensentscheidungen, die nicht automatisiert werden sollten. Eine KI, die versucht, eine strittige Rechnung zu lösen, ist ein Haftungsrisiko.
Churn-Gespräche und eskalierte Beschwerden sollten sofort an einen erfahrenen Menschen weitergeleitet werden. Der Versuch von KI-Self-Service bei einem Kunden, der frustriert genug ist, die Kündigung anzudrohen, beschleunigt den Churn. Die KI kann den Account-Kontext für den CSM, der die Eskalation erhält, zusammenfassen, aber das Gespräch selbst braucht einen Menschen.
Wissensbasisqualität: Die eigentliche Investition
Wenn Sie planen, einen KI-Support-Agenten einzusetzen, und Sie zuvor nicht in Ihre Dokumentation investiert haben, wird der Agent unterdurchschnittliche Ergebnisse liefern und Sie werden der KI die Schuld geben.
Bevor Sie Intercom Fin oder Zendesk AI bewerten, prüfen Sie Ihr Help-Center. Beginnen Sie damit, die 30 häufigsten Tier-0-Ticket-Typen der letzten 90 Tage herauszuziehen. Wie viele davon haben einen entsprechenden Hilfe-Artikel? Von diesen Artikeln, wie viele sind spezifisch genug, um die Frage tatsächlich zu beantworten (nicht nur das Feature auf hohem Niveau zu beschreiben)? Wie viele sind mit Ihrem letzten wichtigen Release aktuell?
Ein praktisches Dokumentations-Bereitschaftsziel: Ihre Top-50-Ticket-Typen sollten dedizierte, spezifische Hilfe-Artikel haben, die jeweils innerhalb der letzten 90 Tage aktualisiert wurden. Wenn nicht, erstellen und aktualisieren Sie diese zuerst. Ihre KI-Deflektionsrate aus diesen 50 Ticket-Typen wird wesentlich höher sein als aus einer weitläufigen, teilweise veralteten Wissensbasis.
Der Abrufschritt profitiert auch von früher gelösten Tickets. Wenn Ihre KI ein früheres Ticket abrufen kann, bei dem ein Agent dasselbe Problem gelöst hat, hat sie einen Präzedenzfall zum Nachschlagen. Die Eingabe Ihrer gelösten Ticket-Historie in den Abruf-Corpus (nach angemessener Anonymisierung von Kundendaten) verbessert die Deflektionsqualität für Randfälle, die nicht explizit dokumentiert sind, bedeutend.
„SaaS-Unternehmen, die KI-First-Support-Plattformen nutzen, verzeichnen 60 % höhere Ticket-Deflektionsraten im Vergleich zu traditioneller Help-Desk-Software, aber diese Obergrenze erfordert eine Dokumentation, die die Top-50-Ticket-Typen mit spezifischen, aktuellen Antworten abdeckt. Ohne diese Grundlage bleibt die reale Deflektionsrate bei 15-20 %, unabhängig vom gekauften KI-Tier." (Pylon/Fini Labs Analyse, 2025)
„Deflektionsraten variieren stark nach Ticket-Typ. Hoch strukturierte Absichten mit einem klaren Back-End-System-of-Record deflektieren bei 65-80 %. Gefühlsbetonte und Streit-ähnliche Absichten bleiben im Bereich von 19-34 %. Die Optimierung der Defektion bedeutet, jede Kategorie entsprechend zu routen, nicht einen einzelnen Durchschnitt zu optimieren." (Digital Applied, 2026)
Die Kostenrechnung
Werfen wir einen Blick auf die Wirtschaftlichkeit eines Mid-Market-SaaS-Support-Teams.
Ein 10-köpfiges Support-Team, das 2.000 Tickets pro Monat mit durchschnittlichen Kosten von 12 US-Dollar pro Ticket (gemischte Vollkosten einschließlich Agentenzeit, Tools und Overhead) bearbeitet, hat monatliche Support-Kosten von 24.000 US-Dollar.
Ein gut implementierter KI-Support-Agent mit 40 % Deflektionsrate bearbeitet 800 dieser Tickets autonom. Bei KI-Kosten pro Lösung von etwa 0,50 bis 1,00 US-Dollar (je nach Anbieter und Volumen) kosten diese 800 Tickets 400 bis 800 US-Dollar zur Lösung.
Die verbleibenden 1.200 Tickets gehen an Menschen, aber diese Agenten arbeiten schneller mit KI-Unterstützung. Bei einem 25-prozentigen Effizienzgewinn durch Workflow-Copilot-ähnliche Antwortentwürfe und aufgedeckten Kontext benötigen diese 1.200 Tickets nun 75 % der Zeit, die sie zuvor brauchten.
Nettoeffekt: 24.000 US-Dollar monatliche Support-Kosten werden zu ungefähr 15.000 bis 17.000 US-Dollar, bei gleichzeitig verbesserter Reaktionsgeschwindigkeit und stabilem oder steigendem CSAT. Über 12 Monate sind das 84.000 bis 108.000 US-Dollar Einsparungen für ein einzelnes Mid-Market-Support-Team.
Diese Zahlen erfordern gute Dokumentation und realistische Deflektionsraten. Übertriebene Deflektionsansprüche führen zu übertriebenen Einsparprojektionen, die mit der Realität nicht standhalten. Gartner prognostiziert, dass Agentic AI bis 2029 80 % der häufigen Kundenservice-Probleme autonom lösen wird, aber diese Obergrenze erfordert eine ausgereifte Wissensinfrastruktur, die die meisten SaaS-Unternehmen noch aufbauen.
CSAT-Auswirkung: Die zwei Ergebnisse
KI-Support verbessert entweder den CSAT oder schadet ihm, abhängig von der Implementierungsqualität. Es gibt kein neutrales Ergebnis.
Gut implementierter KI-Support verbessert den CSAT, weil Geschwindigkeit im Support enorm wichtig ist. Ein Kunde, der in 30 Sekunden eine genaue Antwort erhält, ist zufriedener als einer, der 4 Stunden auf eine menschliche Antwort wartet, selbst wenn beide Antworten gleich korrekt sind. Für Tier-0-Fragen mit klaren Antworten übertrifft KI-Lösung in der Geschwindigkeit die menschliche Lösung im normalen Ticket-Queue-Tempo.
Schlecht implementierter KI-Support schadet dem CSAT aus demselben Grund, aber in die andere Richtung. Ein Kunde, der eine selbstsichere, detaillierte, aber falsche Antwort von einer KI erhält, dann ein neues Ticket öffnen muss, um zu melden, dass die erste KI-Antwort sein Problem verschlimmert hat, ist deutlich frustrierter, als wenn er von Anfang an eine menschliche Antwort bekommen hätte. Die Zeitkosten plus der Genauigkeitsfehler plus das Gefühl, durch einen Chatbot geschleust zu werden, ist ein CSAT-Desaster.
Der Unterschied zwischen diesen Ergebnissen liegt fast vollständig in der Qualität der Wissensbasis und der Qualität der Eskalationsauslöser. Wenn die KI eskaliert, wenn sie sollte (niedriger Konfidenzwert, komplexes Problem, frustrierter Kunde), anstatt zu versuchen, alles zu lösen, bleibt die CSAT-Auswirkung positiv. Hallucination risk by pattern erklärt, warum RAG-verankerte Systeme bei Randfällen noch scheitern und welche Schwellenwerte zu setzen sind.
SaaS-Support-KI-Performance-Benchmarks
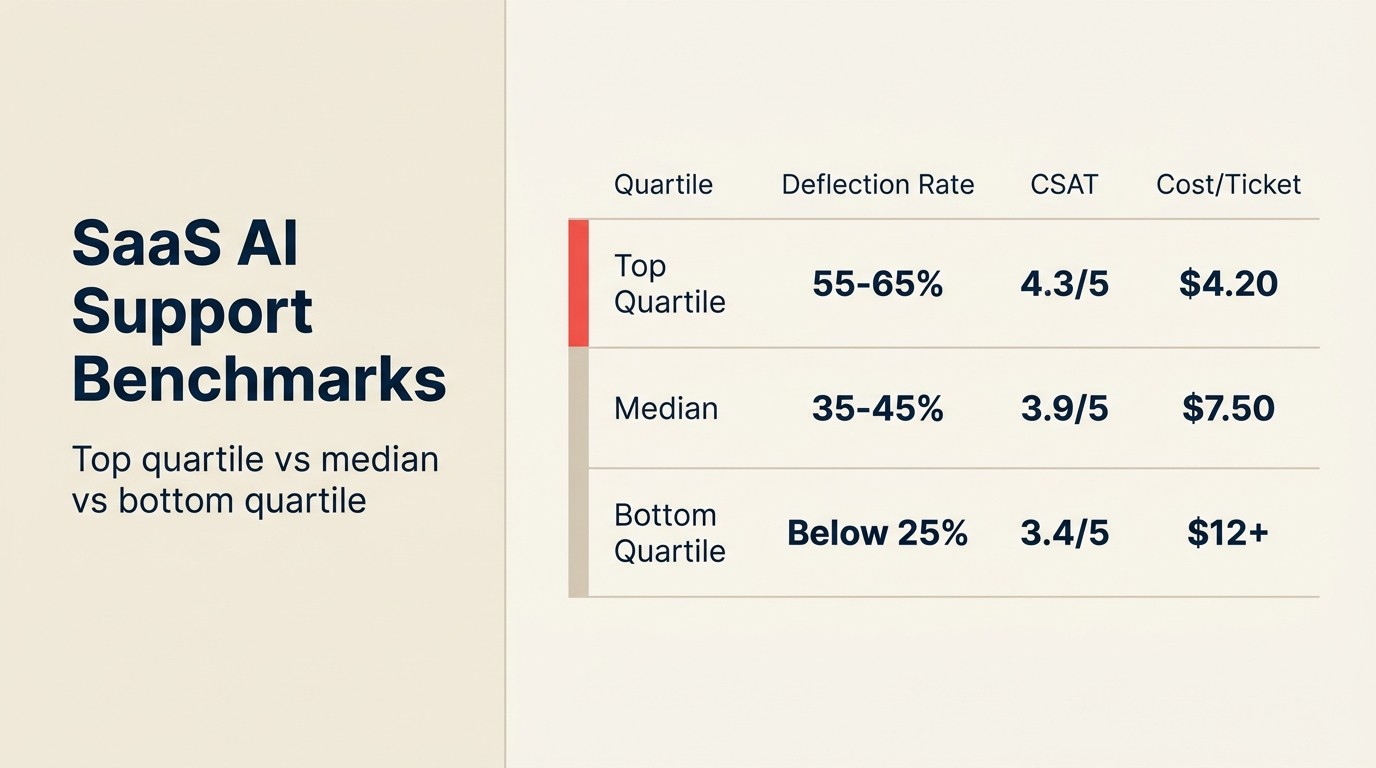
| Deployment-Qualität | Deflektionsrate | CSAT bei deflektierten Tickets | False-Deflektions-Rate |
|---|---|---|---|
| Top-Quartil (ausgereifte KB, gutes Eskalationsdesign) | 55-70 % | 4,2-4,7/5 | Unter 8 % |
| Median (angemessene KB, Standard-Eskalation) | 35-45 % | 3,8-4,2/5 | 10-18 % |
| Unteres Quartil (veraltete KB, schlechte Eskalationsschwellen) | 15-25 % | 2,8-3,4/5 | 22-30 % |
Quellen: Zendesk CX Trends Report 2026, Intercom Benchmark Data 2025, Gartner Customer Service AI Analysis 2025
Rework Analysis: Die Deflektionsraten-Lücke zwischen Top- und unterem Quartil bei SaaS-Support-Deployments ist keine Technologie-Lücke. Beide nutzen dieselben Anbieter-Tools. Die Lücke ist die Dokumentationsreife. Top-Quartil-Teams haben eine Release-to-Doc-Pipeline, die ihre Wissensbasis innerhalb von 2-3 Wochen des aktuellen Produktzustands hält. Untere Quartil-Teams haben eine Wissensbasis, die beim Launch umfassend war und seitdem abgedriftet ist. KI ist ein Dokumentationsqualitätsverstärker: Sie lässt gute Dokumente besser abschneiden und macht veraltete Dokumente schneller scheitern. Teams, die die Dokumentation vor der Anbieterbewertung prüfen, erzielen 2-3-mal mehr Support-KI-ROI als Teams, die zuerst Anbieter bewerten.
Verbindung zum breiteren Support-Stack
Der KI-Support-Agent ist die erste Linie einer umfassenderen Support-Intelligence-Architektur. Ticket Deflection with RAG in SaaS Support geht tiefer auf die RAG-Implementierung ein: Corpus-Design, Abrufqualitätsoptimierung und wie man veraltete Dokumentation ohne Halluzinationsrisiko handhabt.
Multi-Tier AI Routing in SaaS Help Desk behandelt die Routing-Ebene im Detail: wie KI Tickets nach Komplexität, Kunden-Tier, Produktbereich und Agentenspezialisierung statt nach einfachem Keyword-Matching zuweist.
The 4 AI Agents Every B2B SaaS Company Needs ordnet den KI-Support-Agenten in den Kontext des breiteren SaaS-KI-Stacks ein, zusammen mit dem Sales Operator, Customer Success Manager und Content Operator.
Wo anfangen
Wenn Sie ein VP of Support sind, der KI-Defektion bewertet, ist der ehrliche Ausgangspunkt eine Dokumentationsprüfung, keine Anbieterbewertung. Finden Sie Ihre Top-50-Ticket-Typen. Prüfen Sie, ob Ihr Help-Center sie tatsächlich genau und spezifisch beantworten kann. Schließen Sie die Lücken.
Dann starten Sie ein Pilot mit engem Scope: ein Produktbereich, eine Ticket-Typ-Kategorie, ein Kundensegment. Führen Sie es 60 Tage lang durch, messen Sie Deflektionsrate und CSAT und expandieren Sie auf Basis des Gelernten.
Das KI-Tool ist nicht die Einschränkung. Dokumentationsqualität und Eskalationsdesign sind es. Wenn Sie das richtig machen, ergibt sich die Deflektionsrate von selbst.
Häufig gestellte Fragen
Welche Deflektionsrate sollte ein SaaS-Unternehmen von einem KI-Support-Agenten erwarten?
Realistische Deflektionsraten für gut dokumentierte SaaS-Produkte sind 30-50 %. Top-Quartil-Deployments erreichen 55-70 %, aber diese spiegeln ausgereifte Wissensbasen wider, die die Top-50-100-Ticket-Typen mit spezifischer, aktueller Dokumentation abdecken. Ansprüche von 70 %+ spiegeln typischerweise enge Ticket-Scopes oder aufgeblähte Lösungszählung wider. Der Median über Enterprise-CX-Programme 2026 ist 41,2 % (Zendesk/Salesforce, 2026).
Warum übertrifft ein RAG-basierter KI-Agent generische Chatbots im SaaS-Support?
Generische Chatbots generieren Antworten aus Trainingsdaten, die annähern, wie SaaS-Produkte funktionieren. RAG ruft aus Ihrer tatsächlichen Wissensbasis ab, sodass die Antwort in Ihren spezifischen API-Fehlercodes, Ihrem Berechtigungsmodell und Ihrem aktuellen Produktverhalten verankert ist. Die Qualität des abgerufenen Inhalts bestimmt die Qualität der Antwort. Eine leicht unbeholfene Antwort aus genauen abgerufenen Dokumenten übertrifft eine polierte Antwort aus dem besten Versuch des Modells.
Welche Dokumentation braucht ein SaaS-KI-Support-Agent, um gut zu funktionieren?
Fünf Inhaltstypen bilden den Abruf-Corpus: Hilfedokumentation, API- und Entwicklerdokumente, Produkt-Release-Notes, anonymisierte gelöste Tickets sowie FAQ oder In-Produkt-Anleitungen. Release-Notes werden am häufigsten vernachlässigt. Jedes neue Feature oder jede API-Änderung erzeugt neue Support-Fragen, und wenn Release-Notes nicht im Corpus sind, beantwortet die KI mit veralteten Informationen.
Wie verhindert man, dass KI-Support den CSAT schadet?
Zwei Designentscheidungen bestimmen, ob KI-Support den CSAT verbessert oder schadet. Erstens: Qualität der Eskalationsauslöser: Die KI muss eskalieren, wenn sie sollte (niedriger Konfidenzwert, komplexes Problem, frustrierter Kunde), anstatt zu versuchen, alles zu lösen. Zweitens: Qualität der Wissensbasis: Selbstsichere, aber falsche Antworten aus veralteter Dokumentation schaden dem CSAT mehr als langsame menschliche Antworten.
Welche Ticket-Typen sollten niemals an KI-Self-Service gehen?
Fehler-Untersuchungen, Datenschutzanfragen (DSGVO-Exporte, Löschung), Abrechnungsstreitigkeiten, Vertragsfragen sowie Churn- oder Eskalationsgespräche sollten direkt an Menschen weitergeleitet werden. Diese erfordern Account-Ebene-Kontext, rechtliches Bewusstsein oder Beziehungsurteilsvermögen, das KI nicht bieten kann. Der Versuch von KI-Self-Service bei einem Kunden, der eine Kündigung androht, beschleunigt den Churn.
Wie berechnet man den ROI eines KI-Support-Agenten?
Monatliche Support-Basiskosten (Agentenzeit plus Tools). Deflektionsrate auf das Ticket-Volumen anwenden. KI-Kosten pro Lösung betragen etwa 0,50-1,00 US-Dollar pro Ticket. Für die verbleibenden menschlich bearbeiteten Tickets einen 20-25-prozentigen Effizienzgewinn durch KI-gestützte Entwürfe ansetzen. Die Nettokostenreduzierung plus die Zeitersparnis kann jährlich projiziert werden. Ein 10-köpfiges Team, das 2.000 Tickets pro Monat bearbeitet, erzielt bei 40 % Deflektionsrate typischerweise 84.000-108.000 US-Dollar jährliche Einsparungen bei realistischen Kostenannahmen.
Weiterführende Links:
- RAG Assistant Pattern: das Kern-Abrufmuster, das genauen KI-Support ermöglicht
- Hallucination Risk by Pattern: wo RAG-verankerte KI noch scheitert und wie Eskalationsschwellen gesetzt werden
- Ticket Deflection with RAG in SaaS Support: tiefer gehende RAG-Implementierung und Corpus-Design
- Multi-Tier AI Routing in SaaS Help Desk: wie intelligentes Routing über Keyword-Matching hinausgeht
- AI Knowledge Base Maintenance for SaaS: Abruf-Corpus aktuell halten, wenn sich das Produkt weiterentwickelt
- The 4 AI Agents Every B2B SaaS Company Needs: der vollständige KI-Agenten-Stack für SaaS

Co-Founder, Rework.com
On this page
- Der KI-Support-Agent definiert
- Das L0-L1-L2-SaaS-Support-Tier
- Warum RAG das Kernmuster ist
- Tier-Struktur für SaaS-Support
- Was KI im SaaS-Support gut bewältigt
- Was KI im SaaS-Support schlecht bewältigt
- Wissensbasisqualität: Die eigentliche Investition
- Die Kostenrechnung
- CSAT-Auswirkung: Die zwei Ergebnisse
- SaaS-Support-KI-Performance-Benchmarks
- Verbindung zum breiteren Support-Stack
- Wo anfangen