Playbook de Resposta a Incidentes de AI: Como Responder Quando AI Falha

Um chatbot de AI diz a um cliente que ele tem direito a um reembolso que não tem. Um sumarizador de AI omite uma cláusula contratual crítica durante uma revisão de due diligence, e a omissão não é detectada até depois da assinatura. Um modelo de scoring de leads de AI começa a encaminhar seus prospects de maior valor para os representantes errados, e ninguém percebe por três semanas.
Esses são incidentes de AI. E são diferentes dos incidentes de TI que sua equipe já sabe como lidar.
Seu processo de resposta a incidentes conhece a diferença? Se não, você responderá com lentidão demais aos sinais errados, escalará as coisas erradas e perderá os problemas que estão afetando silenciosamente centenas de decisões antes que alguém perceba.
Este playbook é para CIOs, líderes de segurança e equipes de transformação que estão construindo sua primeira capacidade de resposta a incidentes específica de AI, ou auditando se seu processo existente é adequado. Ele se conecta a Criando Sua Política de Uso de AI (que define o escopo autorizado de AI) e Trilhas de Auditoria para Ações Execute de AI (que fornece a base de evidências para investigação).
Como incidentes de AI diferem de incidentes de TI

Fatos Essenciais: Risco de Incidentes de AI
- O GDPR Article 33 exige notificação à autoridade supervisora relevante em 72 horas após tomar conhecimento de uma violação de dados pessoais; o prazo de 72 horas começa quando a organização toma conhecimento, não quando a investigação é concluída (GDPR Article 33)
- As categorias de incidentes de AI incluem alucinação, erro de Execute, viés, exposição de dados e deriva de modelo; a resposta a incidentes de TI tradicional (construída em torno de falhas binárias de up/down) perde a natureza latente e probabilística das falhas de AI que podem afetar centenas de decisões antes da detecção (pesquisa do NIST Cybersecurity Framework)
- A Gartner prevê que mais de 40% dos projetos de AI agêntica serão cancelados até 2027, com frameworks de governança falhando em acompanhar o ritmo como a principal causa; a infraestrutura de resposta a incidentes é um dos três componentes de governança mais frequentemente ausentes (Gartner, 2025)
A resposta a incidentes de TI tradicional é construída em torno de um modelo simples: os sistemas estão ou em operação ou fora de operação. Um servidor fica offline, um serviço retorna um erro 500, um link de rede falha. O incidente é binário e imediato. A detecção é rápida, geralmente automatizada. A correção é técnica: restaure o serviço.
Os incidentes de AI não funcionam assim. A função Respond do NIST Cybersecurity Framework descreve a resposta a incidentes como conter e gerenciar impactos de eventos detectados, mas o CSF foi projetado em torno de falhas técnicas binárias e detectáveis. Os incidentes de AI exigem um modelo de detecção e resposta significativamente diferente.
São probabilísticos. Um sistema de AI que está funcionando "bem" na maior parte do tempo pode estar tomando decisões incorretas para uma subpopulação específica de inputs: um segmento específico de clientes, um tipo específico de documento, um idioma específico. As métricas gerais de precisão parecem aceitáveis. A cauda está falhando gravemente.
São latentes. Um modelo tendencioso de scoring, uma base de conhecimento com alucinações, uma vulnerabilidade de injeção de prompt, esses podem operar por semanas ou meses antes que alguém perceba. A analogia de incidente de TI seria um servidor que está corrompendo silenciosamente dados 3% do tempo em vez de travar completamente.
Frequentemente são invisíveis até se tornarem consequentes. Uma AI que envia informações erradas a clientes, toma decisões discriminatórias em contratações ou vaza dados em um contexto de prompt não gera um erro 500. Pode gerar uma reclamação de cliente, uma consulta de regulador ou a ligação de um jornalista. Esse é um dos modos de falha de governança que compromete transformações de AI bem financiadas.
A causa raiz é mais difícil de encontrar. Incidentes de TI têm causas raiz técnicas: uma configuração incorreta, um bug de código, uma falha de hardware. Incidentes de AI podem resultar de comportamento do modelo (o modelo sempre iria falhar neste tipo de input), design de prompt (o prompt é inconsistente em certos casos extremos), qualidade de dados (os dados de treinamento ou recuperação estavam errados), falha de integração (o output correto foi gerado, mas a ação errada foi executada) ou comportamento do usuário (os humanos começaram a usar a ferramenta de uma forma para a qual não foi projetada).
Cada tipo de causa raiz exige uma resposta diferente.
"Incidentes de AI não se anunciam com um erro 500. Um modelo tendencioso de scoring pode operar por meses antes que alguém perceba. Uma AI que envia informações erradas a clientes não trava. Ela gera uma reclamação de cliente. O processo de resposta a incidentes que funciona para interrupções de TI perderá a maioria das falhas de AI até que se tornem crises." (Rework)
A Taxonomia de Incidentes de AI de 4 Tipos
Um framework de classificação para categorizar incidentes de AI por tipo de causa raiz, permitindo diagnóstico mais rápido e resposta mais direcionada. Tipo 1 (Alucinação): AI gerou conteúdo factualmente incorreto que foi utilizado. Tipo 2 (Erro de Execute): AI tomou uma ação consequente incorretamente, com consequências no mundo real. Tipo 3 (Viés): AI tomou decisões sistematicamente discriminatórias afetando uma subpopulação; maior exposição regulatória. Tipo 4 (Exposição de Dados): input de prompt ou output de AI revelou informações que deveriam ter sido protegidas; pode acionar a obrigação de notificação de 72 horas do GDPR Article 33. Tipo 5 (Deriva de Modelo): o desempenho de AI se degradou ao longo do tempo sem um único momento de falha detectável; o tipo de incidente mais frequentemente perdido. Cada tipo tem um sinal de detecção distinto, prazo de resposta e abordagem de investigação de causa raiz. Usar o protocolo de resposta errado para o tipo de incidente produz resolução mais lenta e pode perder problemas sistêmicos.
Taxonomia de incidentes de AI
Antes de poder responder a um incidente de AI, você precisa saber que tipo de incidente tem.
Tipo 1: Incidente de alucinação
A AI gerou conteúdo factualmente incorreto que foi utilizado. Um cliente recebeu informações erradas sobre a cobertura de sua apólice. Um agente de suporte usou uma resposta gerada por AI para resolver um ticket incorretamente. Um documento escrito por AI continha citações fabricadas.
Sinal de detecção: reclamação de cliente, revisão interna de qualidade, relato de funcionário, erro de sistema downstream causado por agir com base em informações incorretas.
Perguntas-chave na resposta: O output foi revisado antes de ser usado? Isso foi um caso único ou o modelo alucina consistentemente neste tipo de pergunta? Existe uma mudança de prompt que o corrigiria?
Tipo 2: Erro de Execute
A AI tomou uma ação consequente incorretamente. Este é o tipo de incidente mais sensível ao tempo, porque as ações Execute mudam o estado do mundo. Reembolso errado emitido. E-mail enviado para a lista de destinatários errada. Registros de CRM atualizados com dados incorretos. Workflow acionado quando não deveria ter sido.
Sinal de detecção: reclamação de cliente, discrepância de reconciliação financeira, erro de processo downstream, relato de funcionário.
Perguntas-chave na resposta: A ação pode ser revertida? Se sim, quem está autorizado a revertê-la e como? Quem foi afetado? A causa raiz está no modelo de AI, na lógica de gatilho ou na integração entre o output de AI e o sistema externo?
Tipo 3: Incidente de viés
A AI tomou decisões sistematicamente discriminatórias. Um modelo de scoring encaminhou desproporcionalmente candidatos de certo grupo demográfico para rejeição. Uma AI relacionada a crédito recusou aplicações a taxas diferentes para classes protegidas. Uma AI de contratação filtrou candidatos com base em fatores correlacionados com características protegidas.
Sinal de detecção: auditoria demográfica de resultados, relato de funcionário, consulta de regulador, contestação legal de um indivíduo afetado.
Perguntas-chave na resposta: Por quanto tempo o sistema operou com esse viés? Quantos indivíduos foram afetados? Que remediação é devida às partes afetadas? Este modelo ainda está em produção?
Este tipo de incidente tem a maior exposição regulatória. O assessor jurídico deve ser envolvido imediatamente.
Tipo 4: Incidente de exposição de dados
Input de prompt ou output de AI revelou informações que deveriam ter sido protegidas. As informações do Cliente A apareceram na resposta de AI do Cliente B. Os dados pessoais de um funcionário foram incluídos em um contexto de prompt acessível a usuários não autorizados. Dados internos confidenciais foram enviados ao sistema de AI de um fornecedor que não estava autorizado a recebê-los.
Sinal de detecção: reclamação de cliente sobre ver dados de outro usuário, auditoria interna, relato de funcionário, alerta de monitoramento sobre violações de classificação de dados.
Perguntas-chave na resposta: Quais dados foram expostos? Para quem? Eram PII, PHI, dados financeiros ou dados comerciais confidenciais? Foi um evento único ou uma falha sistemática?
Nota sobre o GDPR Article 33: se a exposição envolveu dados pessoais de residentes da UE, você pode ter uma obrigação de notificação de 72 horas à autoridade supervisora relevante. Isso não é opcional. O prazo começa quando você toma conhecimento do incidente, não quando conclui a investigação.
Tipo 5: Deriva de modelo
O desempenho de AI se degradou ao longo do tempo sem que ninguém tenha percebido. O modelo de scoring que estava 78% preciso no primeiro trimestre está em 61% de precisão no terceiro trimestre. O sistema de recuperação que retornava documentos corretos agora retorna documentos desatualizados. A qualidade de geração que era aceitável se degradou conforme o modelo ou o contexto de recuperação mudou.
Sinal de detecção: métricas de monitoramento (se você as construiu), métricas de resultados de negócio (taxa de conversão de leads caindo, satisfação do cliente diminuindo, qualidade de resolução de tickets de suporte diminuindo), relatos de funcionários de que a AI "não é tão boa quanto costumava ser".
Este é o tipo de incidente mais frequentemente perdido porque não há um único momento de falha. Ele se acumula.
O framework de resposta em 4 camadas

Depois de identificar o tipo de incidente, a camada determina quem responde, com que rapidez e o que acontece primeiro.
Camada 4: Investigar
Critérios: Erro interno de output de AI, sem exposição externa, sem impacto no cliente ainda. Uma alucinação descoberta durante revisão interna de qualidade. Um output de Generate que estava incorreto mas não foi utilizado. Deriva de modelo detectada pelo monitoramento interno antes de afetar os resultados.
Janela de resposta: 24 horas para avaliação inicial.
Quem responde: A equipe responsável pelo sistema de AI. Nenhuma escalada necessária, a menos que a avaliação revele exposição externa.
Ações: Documente o incidente no registro de risco de AI. Determine a causa raiz. Avalie se o problema é sistêmico ou isolado. Implemente correção ou solução alternativa. Agende revisão pós-incidente.
Camada 3: Conter
Critérios: Output incorreto voltado ao cliente que não foi utilizado pelo cliente. Uma resposta de chatbot que estava errada, mas o cliente não agiu com base nela. Um e-mail em rascunho com informações incorretas que foi detectado antes do envio.
Janela de resposta: 4 horas para decisão de contenção.
Quem responde: Líder de equipe mais contato de segurança de TI. Notificação da gestão (nenhuma escalada para o CIO necessária, a menos que se torne Camada 2 ou superior).
Ações: Contenha o problema (desabilite a funcionalidade de AI afetada se ainda estiver produzindo outputs incorretos). Avalie a amplitude: apenas este cliente foi afetado ou potencialmente outros? Documente. Determine se a comunicação proativa com o cliente é justificada (geralmente não para a Camada 3, a menos que o output incorreto possa causar dano ao cliente se ele agir com base nele posteriormente).
Camada 2: Resposta a incidentes
Critérios: Erro de Execute voltado ao cliente, incidente de exposição de dados que foi contido, alucinação que foi utilizada por clientes.
Janela de resposta: 1 hora para resposta inicial, gerenciamento contínuo até a resolução.
Quem responde: CIO e líder de segurança notificados dentro da hora. Assessor jurídico em standby. Equipe de comunicações envolvida para elaboração de notificação ao cliente.
Ações: Avalie o impacto (quantos clientes, quais dados, quais ações tomadas). Contenha (desabilite o workflow afetado, reverta ações Execute onde possível). Plano de comunicação com o cliente: os clientes afetados precisam ser notificados? O que eles precisam saber? Avaliação de notificação regulatória: isso constitui uma violação notificável sob o GDPR Article 33? Documente tudo em tempo real.
Camada 1: Crise
Critérios: Exposição regulatória confirmada ou provável, grande impacto no cliente, incidente de viés com indivíduos afetados, exposição de dados envolvendo dados pessoais sensíveis em escala.
Janela de resposta: Imediata. O CEO e o Diretor Jurídico devem estar informados dentro da primeira hora.
Quem responde: Liderança executiva, assessoria jurídica, comunicações externas, assuntos regulatórios se aplicável.
Ações: Decisão executiva sobre se suspender o sistema de AI inteiramente pendente de investigação. Assessoria jurídica externa envolvida. Comunicação ao cliente e ao regulador elaborada e revisada. Revisão pós-crise agendada. Se dados pessoais da UE estiverem envolvidos e a violação for notificável, o prazo de 72 horas sob o GDPR Article 33 está correndo.
GDPR Article 33 e requisitos de notificação
O GDPR Article 33 exige notificação à autoridade supervisora relevante dentro de 72 horas após tomar conhecimento de uma violação de dados pessoais, a menos que a violação "provavelmente não resultará em um risco para os direitos e liberdades das pessoas naturais".
Um incidente de AI pode constituir uma violação de dados pessoais se:
- Um sistema de AI processou dados pessoais de uma forma que resultou em divulgação não autorizada
- Um output de AI contendo dados pessoais foi enviado a um destinatário não autorizado
- Um sistema de AI tomou uma decisão automatizada usando dados pessoais de uma forma que não foi divulgada aos titulares de dados
- Injeção de prompt ou outra exploração levou à exfiltração de dados
O prazo de 72 horas começa quando você toma conhecimento da violação, não quando a investigação é concluída. Você pode enviar uma notificação inicial dizendo "estamos cientes de um incidente, a investigação está em andamento" e complementá-la posteriormente. Aguardar até que a investigação seja concluída antes de notificar não é compatível com a norma.
Para organizações baseadas nos EUA que operam em setores regulados, existem requisitos análogos: a Regra de Notificação de Violação HIPAA para violações de PHI, regras de divulgação de segurança cibernética da SEC para incidentes materiais de segurança cibernética e leis de notificação de violação em nível estadual.
Revisão pós-incidente: análise de causa raiz de AI
A revisão pós-incidente para um incidente de AI segue uma estrutura diferente da post-mortem de TI padrão.
As post-mortems de TI perguntam: qual falha técnica causou a interrupção? Corrija a falha técnica, restaure o serviço.
As revisões pós-incidente de AI fazem quatro perguntas:
Foi uma falha do modelo? A AI produziu um output incorreto porque o modelo subjacente estava errado, alucinando ou com desempenho ruim neste tipo de input? Se sim: quais mudanças de prompt, melhorias de recuperação ou atualizações de modelo evitariam a recorrência? Este modelo deve continuar sendo usado para este caso de uso?
Foi uma falha de prompt ou design? A AI produziu um output incorreto porque o prompt estava ambíguo, a janela de contexto era insuficiente ou o workflow não foi projetado para lidar com este input? Se sim: esta é frequentemente a causa raiz mais corrigível. Redesenhe o template de prompt, adicione validação de input ou adicione guardrails.
Foi uma falha de dados? A AI produziu um output incorreto porque os dados de recuperação estavam desatualizados, os dados de treinamento eram tendenciosos ou os dados de input estavam malformados? Se sim: a governança de dados é a correção, não o modelo.
Foi uma falha de integração? A AI produziu o output correto, mas a integração entre o sistema de AI e o sistema Execute downstream falhou? Se sim: a causa raiz de governança de AI é menos importante do que a correção de engenharia de integração. Mas também: havia uma etapa de revisão humana que deveria ter detectado isso antes do Execute?
Documente a causa raiz no registro de risco de AI. Atualize os documentos de governança de AI relevantes. Se o incidente revelou uma lacuna no seu design humano no fluxo, corrija a lacuna.
Construindo a cultura de relato
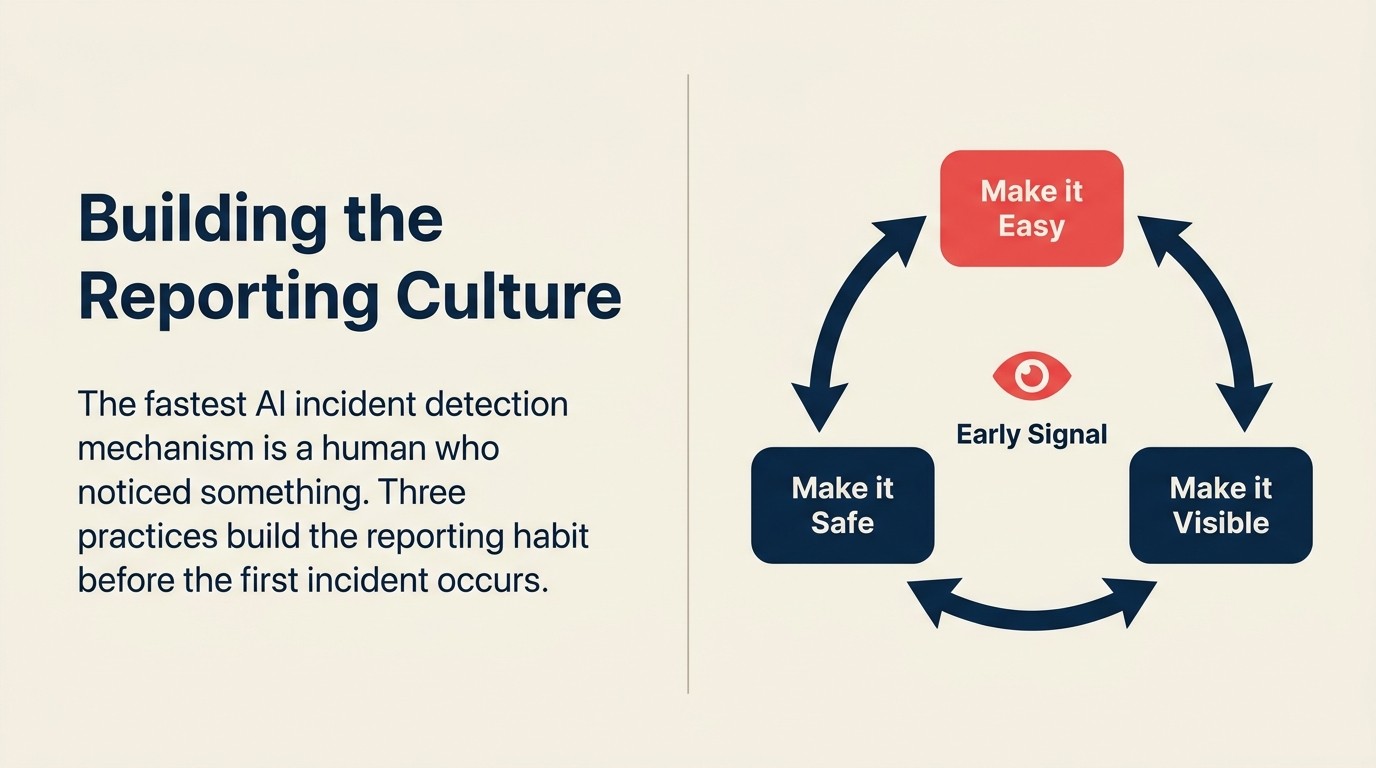
A lacuna mais perigosa em qualquer programa de resposta a incidentes de AI não é o playbook. São os funcionários que veem um problema e não o relatam.
Um funcionário que percebeu que o chatbot de AI estava dando informações erradas sobre reembolsos na terça-feira passada. Um engenheiro que viu um padrão anômalo nos logs de output de AI, mas não tinha certeza se importava. Um gerente de customer success que ouviu uma reclamação sobre uma recomendação gerada por AI, mas a atribuiu a um caso único.
Cada um desses é um sinal precoce. A maioria dos incidentes de AI que se tornam crises começou como sinais que foram vistos e não foram atendidos.
Construir uma cultura de relato significa três coisas:
Torne o relato fácil. Um canal interno, um formulário, um endereço de e-mail. Os funcionários não devem precisar navegar por organogramas para relatar um possível problema de AI.
Torne o relato seguro. Os funcionários que relatam problemas não devem ser culpados pelo incidente ou por levantar um alarme falso. A resposta a um relato, mesmo que se revele um não-incidente, deve ser "obrigado por sinalizar isso". Se os relatores se sentirem culpados, eles pararão de relatar.
Torne o relato visível. Quando um relato leva a um incidente genuíno sendo detectado cedo, diga à equipe. Não "tivemos um incidente importante", mas "porque alguém sinalizou uma anomalia semana passada, detectamos um problema antes de afetar os clientes". A prova social de que o relato importa cria o hábito.
Os documentos de governança, as trilhas de auditoria e as camadas de resposta existem para gerenciar incidentes após ocorrerem. A cultura de relato é o que determina se você descobre sobre os problemas cedo ou tarde.
O que este playbook não substitui
Este playbook governa a resposta a incidentes específica de AI. Ele não substitui seu processo existente de resposta a incidentes de TI, seu processo de resposta a violações de dados sob o GDPR ou CCPA, nem seu processo de RH para reclamações relacionadas a discriminação. Esses processos ainda se aplicam. Para incidentes que envolvem tanto uma falha de AI quanto uma violação de dados, ambos os playbooks rodam em paralelo.
Conecte este playbook ao seu framework de trilha de auditoria, que fornece a evidência que você precisará durante a investigação de incidentes. Conecte-o à sua política de uso de AI, que define o escopo autorizado das ações de AI. E conecte-o ao seu registro de risco de AI, onde os padrões de risco conhecidos de incidentes passados são documentados para que incidentes futuros sejam detectados mais rapidamente.
Análise Rework: Com base em padrões de incidentes de AI corporativa, a razão mais comum pela qual incidentes menores de AI se tornam crises não é o próprio incidente, mas o atraso na detecção. Um incidente de viés afetando 15% dos outputs de um modelo de scoring pode rodar por 8 a 12 semanas antes de aparecer nas métricas de negócio. Uma exposição de dados em um contexto de AI compartilhado pode não surgir até que um cliente relate ver os dados de outro usuário. A seção de cultura de relato deste playbook existe porque o mecanismo de detecção mais rápido é um humano que notou algo e o relatou. Cada semana de atraso na detecção agrava a exposição regulatória, o número de clientes afetados e a complexidade de remediação.
O objetivo não é ter um playbook que você nunca precise usar. É estar pronto quando precisar.
E as empresas que executam as respostas a incidentes mais limpas são as que construíram a cultura de relato muito antes do primeiro incidente. Então a pergunta real é: sua equipe sabe para onde ir quando vê algo errado?
Veja também:
- Portões de Aprovação de AI e Revisão de Fornecedores: o portão pré-implantação que reduz a frequência com que você precisará deste playbook
- Classificação de Dados para Regras de Acesso de AI: o framework de camadas de dados que determina se um incidente do Tipo 4 exige notificação de violação
- Etapa 3 para 4: Do Escalado para o Integrado: por que a resposta formal a incidentes se torna não opcional na Etapa 4
- A Agenda de AI de 18 Meses para o CEO: onde a infraestrutura de resposta a incidentes se encaixa na Fase 1 do roadmap de transformação

Co-Founder & CMO, Rework
On this page
- Como incidentes de AI diferem de incidentes de TI
- A Taxonomia de Incidentes de AI de 4 Tipos
- Taxonomia de incidentes de AI
- Tipo 1: Incidente de alucinação
- Tipo 2: Erro de Execute
- Tipo 3: Incidente de viés
- Tipo 4: Incidente de exposição de dados
- Tipo 5: Deriva de modelo
- O framework de resposta em 4 camadas
- Camada 4: Investigar
- Camada 3: Conter
- Camada 2: Resposta a incidentes
- Camada 1: Crise
- GDPR Article 33 e requisitos de notificação
- Revisão pós-incidente: análise de causa raiz de AI
- Construindo a cultura de relato
- O que este playbook não substitui