ROI por Capacidade do ACE Framework: Quais Investimentos em IA Retornam Mais Rápido

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A maioria das conversas sobre orçamento de IA dá errado pelo mesmo motivo: tratam todos os investimentos em IA como intercambiáveis. Uma apresentação ao conselho agrupa "gastos com IA" em uma única linha e pede um único número de retorno sobre investimento (ROI). Mas uma IA que Ingere documentos na entrada do seu fluxo de trabalho entrega um retorno fundamentalmente diferente de uma que Executa ordens de compra no final.
Tratá-las como equivalentes é como você acaba aprovando os projetos errados primeiro, e depois explicando ao conselho por que a "IA" não entregou o que foi prometido.
O ACE Framework define cinco capacidades da IA de negócios: Ingest, Analyze, Predict, Generate e Execute. Cada uma opera em um ponto diferente da cadeia de valor. Cada uma tem um perfil de ROI diferente: o que você mede, como são os retornos típicos e quão difícil é provar a causalidade. Entender esses perfis é o que permite sequenciar investimentos de forma racional e definir expectativas honestas com os stakeholders.
Este artigo mapeia cada uma das cinco capacidades ao seu perfil de ROI, incluindo um template simples de cálculo de ROI que você pode adaptar para apresentações internas.
Por que o ROI varia por capacidade do ACE Framework
Key Facts: Realidade do ROI por Capacidade de IA
- Implantações de IA agêntica (com forte componente Execute) retornam uma média de 171% de ROI em ambientes empresariais, aproximadamente 3x os retornos de automação tradicional, mas apenas 15-25% das organizações escalaram IA além do estágio piloto. (Menlo Ventures / Bain)
- O tempo até o ROI varia de duas semanas para automação de atendimento ao cliente (Generate + Execute) a mais de 12 meses para orquestração de cadeia de suprimentos (Predict + Execute). (AI Monk)
- A organização média abandonou 46% das provas de conceito de IA antes da produção em 2025, com dificuldade de atribuição e métricas pouco claras citadas como razões primárias. (Master of Code)
O ROI não é uniforme entre os tipos de IA porque a criação de valor acontece em pontos diferentes de um processo de negócio.
Ingest fica a montante, no momento em que a informação entra em seus sistemas. Seu benefício é invisível para as métricas de receita. Analyze fica no meio, afetando a velocidade e a qualidade com que os humanos tomam decisões. Predict fica no ponto de inflexão entre "temos dados" e "agimos com base neles" e tem o maior potencial teórico de atribuição de receita. Generate produz artefatos que os humanos então usam, criando uma camada entre o resultado da IA e o resultado de negócio. Execute muda o estado diretamente e é a capacidade mais próxima de eventos mensuráveis de custo ou receita.
Essa progressão de montante para jusante também é uma progressão de mais difícil de medir para mais fácil de medir. Mas é o inverso da hierarquia de risco: Execute é o mais fácil de provar ROI e também o mais caro quando dá errado.
Algumas outras variáveis explicam a variância.
A dificuldade de atribuição aumenta com a complexidade da decisão. Se uma IA gera um primeiro rascunho que um representante edita em um e-mail vencedor, quanto daquele negócio é atribuído à IA? Você não sabe. Se uma IA executa uma ordem de compra que previne uma ruptura de estoque, o custo da ruptura evitada é atribuível. Um tem uma cadeia causal limpa; o outro não tem.
O tempo até o valor varia. As capacidades Ingest (reconhecimento óptico de caracteres, transcrição, análise de documentos) estão frequentemente entre as mais rápidas de implantar e mais baratas de medir. As capacidades Execute levam mais tempo para implantar com segurança, mas criam a redução de custos mais persistente uma vez em operação.
A infraestrutura de mensuração importa. Provar o ROI de Predict requer infraestrutura de teste A/B: um grupo de controle que não usa o modelo versus um grupo de tratamento que o usa. A maioria das organizações não tem essa infraestrutura configurada quando começa seu primeiro projeto de IA. Isso não é um problema técnico; é um problema de processo.
Perfil de ROI do Ingest
O que Ingest faz: Converte sinais brutos (imagens, áudio, PDFs escaneados, fluxos de documentos) em informações com as quais a IA pode trabalhar. Reconhecimento óptico de caracteres (OCR), conversão de fala em texto, análise de documentos e extração de dados estruturados são operações canônicas de Ingest.
Métricas primárias:
- Redução no tempo de entrada manual de dados (horas por semana, por operador)
- Taxa de precisão de dados (erros por 1.000 registros, antes vs. depois)
- Volume de processamento (documentos processados por hora)
Retornos típicos: Uma equipe financeira inserindo manualmente faturas em um sistema de enterprise resource planning (ERP) pode gastar de 30 segundos a 2 minutos por documento. Uma IA Ingest processando os mesmos documentos normalmente roda em menos de 3 segundos com 95-99% de precisão. Para uma equipe processando 500 faturas por dia, isso representa 4 a 8 horas de trabalho manual eliminadas por dia, mais uma redução mensurável nos erros de digitação que anteriormente causavam problemas de reconciliação a jusante.
O custo por extração versus a linha de base humana é o template de ROI mais limpo para Ingest. Se uma hora de entrada de dados por humano custa R$125 e você processa 10.000 documentos por mês a 2 minutos cada, seu custo manual é de aproximadamente R$41.500/mês. Uma IA Ingest a R$2.500/mês (comum para ferramentas de automação de documentos para empresas de médio porte) mostra retorno claro.
Desafio de mensuração: Os benefícios do Ingest ficam a montante. Menos erros nos dados de origem significam menos problemas três etapas depois em contas a pagar, registros de clientes ou customer relationship management (CRM). Mas "os problemas de reconciliação que não tivemos" não aparecem em um Dashboard. Você precisa medir as métricas proxy certas (taxas de erros, horas de retrabalho) antes da implantação para fazer a comparação antes/depois. A maioria das equipes pula essa etapa e depois não consegue provar o que economizou. O artigo Vision Extract Pattern cobre o caso de uso de Ingest com mais detalhes, incluindo quais benchmarks de precisão usar como linhas de base pré-implantação.
Template de cálculo de ROI:
Economia mensal = (docs/mês × tempo_manual_médio_min / 60) × custo_hora_mão_de_obra
ROI = (economia_mensal - custo_ferramenta) / custo_ferramenta × 100%
Perfil de ROI do Analyze
O que Analyze faz: Dá sentido ao que foi ingerido. Classificação, extração, sumarização, detecção de sentimento e reconhecimento de entidades são todas operações de Analyze. Analyze é o que transforma texto bruto ou dados em algo acionável para um humano.
Métricas primárias:
- Velocidade de decisão: tempo desde a informação disponível até a decisão tomada (horas para minutos)
- Redistribuição de capacidade do analista: horas por semana liberadas para trabalho de maior julgamento
- Precisão de classificação vs. linha de base humana
Retornos típicos: Uma equipe de suporte ao cliente classificando 2.000 tickets por dia gasta tempo significativo de analista roteando o trabalho antes mesmo de tocá-lo. Uma IA Analyze que classifica e etiqueta os tickets recebidos com mais de 90% de precisão libera completamente as decisões de roteamento, reduzindo o tempo de humano até a primeira resposta de horas para segundos.
Em funções com muita pesquisa (inteligência competitiva, análise financeira, revisão jurídica), as capacidades Analyze podem comprimir horas de síntese em minutos. O ganho de produtividade típico reportado para trabalhadores do conhecimento que usam ferramentas de sumarização e extração de IA fica em 20-40% no tempo de tarefa, dependendo da complexidade do material de origem.
Desafio de mensuração: A qualidade da decisão é difícil de separar da qualidade da análise da IA. Se seu analista toma melhores decisões após ler um resumo gerado por IA, quanto desse resultado pertence à IA versus o julgamento do analista? Você pode medir a velocidade de decisão com precisão. Pode medir a redistribuição de capacidade do analista com rastreamento de tempo. Mas a atribuição de receita de decisões mais rápidas ou melhores requer experimentos controlados que a maioria das organizações não projetou. O artigo RAG Assistant Pattern cobre como instrumentar a capacidade Analyze para rastrear melhorias de qualidade de decisão ao longo do tempo.
A recomendação prática: comece medindo o proxy (economia de tempo, taxa de transferência), não o impacto na receita. Use os primeiros seis meses para construir dados de linha de base. A atribuição de receita vem depois, quando você tem decisões suficientes com resultados conhecidos.
Perfil de ROI do Predict
O que Predict faz: Pontua probabilidades, prevê resultados, classifica opções e detecta anomalias. Pontuação de leads, previsão de churn, previsão de demanda e detecção de fraude são aplicações canônicas de Predict.
Métricas primárias:
- Taxa de conversão (leads pontuados como "alto" pelo modelo versus os não pontuados)
- Taxa de redução de churn (contas sinalizadas versus não sinalizadas, comparação de resultado em 90 dias)
- Precisão da previsão (erro percentual absoluto médio, ou MAPE, antes versus após a previsão por IA)
- Taxas de falso positivo/negativo para detecção de anomalias
Retornos típicos: Predict tem o maior potencial de atribuição de receita de qualquer capacidade do ACE Framework porque influencia diretamente quais ações os humanos tomam nos resultados de negócio mais valiosos. Um modelo de pontuação de leads bem calibrado que ajuda os representantes a priorizar os 20% principais de leads (que normalmente respondem por 60-80% da conversão) pode melhorar materialmente o cumprimento de cota sem adicionar headcount. Modelos de previsão de churn que identificam contas em risco 30 a 60 dias antes da janela de decisão de renovação dão às equipes de Customer Success tempo para intervir.
A faixa de resultados reportados aqui é mais ampla do que para qualquer outra capacidade. Implementações fracas de Predict (modelos treinados com dados insuficientes, implantados sem processos de adoção pelos representantes) mostram ganho quase nulo. Implementações fortes com infraestrutura adequada de teste A/B e integração ao fluxo de trabalho dos representantes mostram melhoria de 10-30% na taxa de conversão em benchmarks comparáveis. A análise da McKinsey sobre o potencial econômico da IA generativa especificamente destaca marketing e vendas como o domínio onde as capacidades de Predict e pontuação concentram o valor mais mensurável, estimando uma melhoria de 3-5% na produtividade de vendas.
Desafio de mensuração: O ROI de Predict é o mais difícil de atribuir de forma limpa. Requer teste A/B para isolar a contribuição do modelo de tudo mais acontecendo simultaneamente (habilidade do representante, mudanças no produto, condições de mercado, movimentos de preços). Sem um grupo holdout, você não pode saber se a melhoria na conversão veio do modelo ou dos comportamentos dos representantes que coincidentemente se correlacionaram com ele.
A maioria das organizações que afirma ROI de Predict sem teste A/B está reportando correlação, não causalidade. Isso não é uma razão para evitar a capacidade Predict; é uma razão para projetar a infraestrutura de mensuração antes da implantação, não depois. O artigo Scoring and Routing Pattern cobre o design de teste A/B para implantações de Predict, incluindo a construção de grupo holdout que as equipes de vendas vão aceitar.
Perfil de ROI do Generate
O que Generate faz: Produz novos artefatos a partir de prompts e contexto. Rascunhos de e-mail, relatórios, código, resumos, imagens e planos estruturados são todos resultados de Generate. O artefato existe em forma de rascunho até que um humano o revise e implante.
Métricas primárias:
- Economia de tempo no primeiro rascunho (minutos por artefato)
- Volume de conteúdo com headcount constante
- Tempo de ciclo de edição até publicação (tempo desde o briefing até o rascunho final)
- Pontuação de consistência de marca (se usar IA com aplicação de guia de estilo)
Retornos típicos: A capacidade Generate entrega as economias de tempo mais claras de qualquer capacidade do ACE Framework, e essas economias são rápidas de medir porque o tempo do primeiro rascunho é fácil de observar. Uma equipe de marketing que gastava 4 horas escrevendo uma postagem de blog do zero normalmente reporta gastar 45 a 90 minutos no mesmo artigo ao usar a criação de rascunhos por IA. Um representante de vendas elaborando uma proposta personalizada foi de 60 a 90 minutos para 15 a 20 minutos.
A matemática sobre volume de conteúdo é simples: se uma equipe produzia 8 postagens de blog por mês antes da IA e agora produz 18 com o mesmo headcount, você pode calcular o custo efetivo por peça e compará-lo ao que os redatores contratados cobrariam. Volume de conteúdo com headcount constante é uma métrica de ROI de Generate limpa e defensável.
Desafio de mensuração: A mensuração de qualidade é a parte difícil. Volume é fácil de medir; qualidade não é. Um primeiro rascunho que requer edição humana significativa para se tornar publicável captura menos ROI do que um que requer edição leve. Medir a "distância de edição" (o quanto o resultado final difere do rascunho da IA) fornece um proxy de qualidade, mas requer ferramentas e rastreamento consistente que a maioria das equipes não tem.
O ROI de Generate é frequentemente superestimado em pilotos iniciais porque as equipes medem a economia de tempo da criação de rascunhos por IA sem contabilizar o tempo de revisão, a degradação da qualidade (conteúdo que tecnicamente existe, mas tem desempenho ruim) e o custo de coordenação de gerenciar o volume gerado por IA.
O enquadramento honesto: Generate economiza tempo significativo em primeiros rascunhos. Não substitui o julgamento necessário para tornar esses rascunhos bons. A pesquisa do MIT Sloan sobre escalonamento de IA generativa no local de trabalho descobriu que a satisfação dos funcionários com ferramentas de criação de rascunhos por IA se correlaciona mais fortemente com melhorias de qualidade percebidas do que com o tempo bruto economizado, razão pela qual medir ambas as dimensões importa.
Perfil de ROI do Execute
O que Execute faz: Muda o estado fora do sistema de IA. Envia e-mails, atualiza registros, aciona fluxos de trabalho, emite transações e roteia trabalho. Execute é onde a IA para de gerar sugestões e começa a tomar ações com consequências reais.
Métricas primárias:
- Taxa de automação de processo (porcentagem de um fluxo de trabalho tratado sem intervenção humana)
- Compressão de tempo de ciclo (tempo desde o gatilho até a conclusão)
- Taxa de redução de erros (erros de processo antes vs. depois da automação)
- Custo por transação vs. linha de base humana
Retornos típicos: A capacidade Execute entrega a redução de custos mais direta de qualquer capacidade do ACE Framework quando funciona bem. Um sistema de automação de contas a pagar que recebe uma fatura, a combina com uma ordem de compra, roteia exceções para humanos e paga automaticamente as faturas aprovadas comprime um processo de 5 a 7 dias para o mesmo dia ou dia seguinte para os casos claros. Em ambientes de transação de alto volume (e-commerce, serviços financeiros, logística), a automação Execute em escala elimina categorias inteiras de funções ou evita crescimento significativo de headcount à medida que o volume escala.
Mas os retornos só são limpos quando o processo em si é bem definido. Execute aplicado a um processo desordenado e cheio de exceções não entrega as economias esperadas e frequentemente cria novos problemas: ações executadas incorretamente em escala, casos extremos tratados errado, lacunas na trilha de auditoria.
Desafio de mensuração: O ROI de Execute é o mais claro de medir de qualquer capacidade, mas os incidentes são os mais caros de se recuperar. Um fluxo de trabalho Execute mal configurado que envia e-mails de cobrança incorretos para 10.000 clientes, ou aprova automaticamente compras além dos limites de autorização, cria custos que superam em muito as economias. A matemática de ROI deve incluir a probabilidade de incidente ajustada ao risco, não apenas as economias em estado estável.
O modelo de governança correto para Execute: meça as economias esperadas, estime a probabilidade e o custo do incidente, verifique se o ROI ajustado ao risco ainda se sustenta e implante com uma etapa de aprovação com humano no ciclo que você remove apenas após a confiança ser estabelecida. Veja Governance by Pattern para o modelo de supervisão e AI Pattern Cost Overruns para as categorias de custo de incidente que devem ser incluídas em qualquer modelo de ROI de Execute ajustado ao risco.
O Perfil de ROI por Capacidade
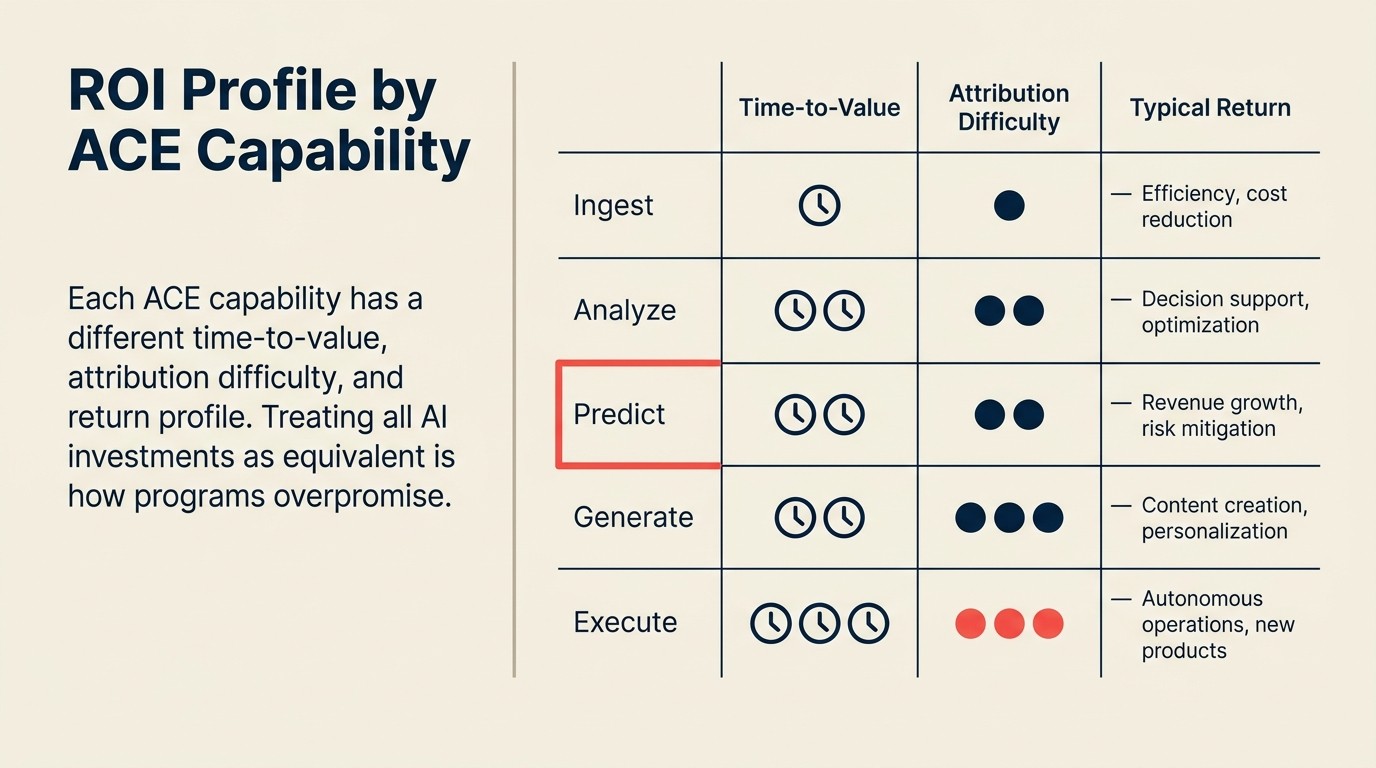
O Perfil de ROI por Capacidade mapeia cada uma das cinco capacidades do ACE Framework (Ingest, Analyze, Predict, Generate, Execute) à sua metodologia de mensuração distinta, janela de retorno típica e dificuldade de atribuição. Em vez de tratar o "ROI de IA" como um único número, este perfil permite que os patrocinadores do programa apresentem casos de investimento específicos por capacidade com a infraestrutura de mensuração certa para cada um.
Quotable: "A capacidade Predict tem o maior potencial de atribuição de receita de qualquer capacidade do ACE Framework, porque determina diretamente quais ações os humanos tomam nos resultados de negócio mais valiosos. Mas também requer infraestrutura de teste A/B que a maioria das organizações não constrói até depois que seu primeiro implantação de Predict falha em mostrar ROI defensável."
Quotable: "O ROI da capacidade Execute é o mais claro de medir e o mais caro quando dá errado. Um fluxo de trabalho Execute mal configurado enviando cobrança incorreta para 10.000 clientes cria custos que superam um ano inteiro de economias de automação."
Quotable: "Comece com Generate. Não requer integração, dados históricos nem processo de aprovação para implantação. O ROI é impreciso, mas real, e constrói familiaridade da equipe com IA antes de você enfrentar capacidades que custam mais quando falham."
| Capacidade ACE | Tempo até o Valor | Dificuldade de Atribuição | Métrica de ROI Principal | Retornos Típicos |
|---|---|---|---|---|
| Ingest | 2 a 6 semanas | Baixa (custo direto de mão de obra) | Custo por documento extraído | R$2.500/mês IA vs R$41.500/mês manual a 10 mil docs |
| Analyze | 4 a 8 semanas | Média (qualidade de decisão) | Velocidade de decisão, capacidade do analista | 20-40% de economia de tempo por trabalhador do conhecimento |
| Predict | 3 a 6 meses | Alta (requer teste A/B) | Taxa de conversão, redução de churn | 10-30% de melhoria na conversão com controles adequados |
| Generate | 2 a 4 semanas | Baixa a média (volume claro, qualidade menos) | Tempo do primeiro rascunho, volume de conteúdo | Redução de 60-75% no tempo do primeiro rascunho |
| Execute | 2 a 4 meses | Baixa (custo direto por transação) | Taxa de automação de processo, tempo de ciclo | Elimina crescimento de headcount proporcional em escala |
Rework Analysis: Com base em padrões de sequenciamento de implantação, organizações que começam com capacidades Generate ou Ingest constroem músculo de mensuração e confiança organizacional antes de enfrentar Predict e Execute, onde as apostas e a complexidade de mensuração são ambas mais altas. Começar com Execute porque tem o maior teto de ROI é o erro de sequenciamento mais comum em programas de IA em estágio inicial.
Sequenciamento de investimentos por estágio de maturidade
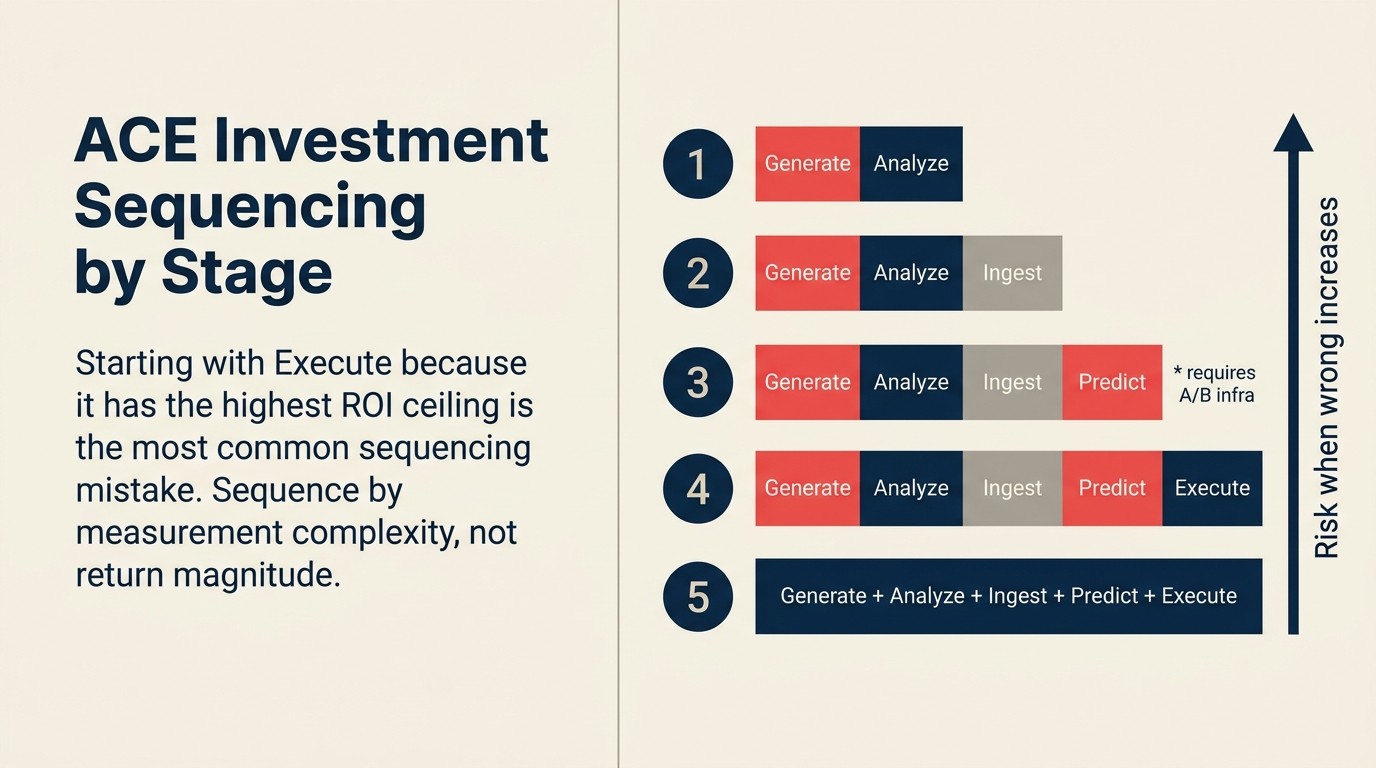
As capacidades do ACE Framework não fazem sentido todas ao mesmo tempo. Organizações em diferentes estágios de maturidade devem priorizar de forma diferente.
Estágio 1 (Ad-hoc): Comece com Generate. Não requer integração, dados históricos nem processo de aprovação para implantação. O ROI é impreciso, mas real, e constrói familiaridade da equipe com IA antes de você enfrentar capacidades mais difíceis. Adicione Analyze para resumos internos de documentos e classificação de tickets.
Estágio 2 (Piloto): Adicione Ingest para seus fluxos de trabalho de documentos ou entrada de dados de maior volume. O ROI é mensurável, a integração é delimitada e o risco é baixo. Comece a projetar a infraestrutura de mensuração para Predict (taxas de conversão de linha de base, auditoria de dados históricos) mesmo que não esteja implantando Predict ainda.
Estágio 3 (Escalado): Implante Predict em seu primeiro caso de uso onde você tem 12 ou mais meses de dados históricos limpos com resultados conhecidos. Invista na infraestrutura de teste A/B. Não pule isso; o ROI de Predict afirmado sem grupos holdout não é defensável para um CFO cético.
Estágio 4 (Integrado): Introduza Execute para seus fluxos de trabalho de maior volume e mais previsíveis primeiro. Não para processos cheios de exceções. Não para transações voltadas ao cliente até ter intervalos de confiança estabelecidos. Construa playbooks de resposta a incidentes antes da implantação.
Estágio 5 (Transformacional): Todas as cinco capacidades em funcionamento, integradas entre si, com humanos supervisionando em vez de executando o trabalho de rotina. O ROI nesse estágio é medido no nível do resultado de negócio, não no nível da capacidade.
O princípio de sequenciamento é simples: comece com capacidades que são mais baratas de medir e de menor risco quando erram. Avance em direção a capacidades de maior retorno e maior risco. Não pule a infraestrutura de mensuração ao longo do caminho.
Reunindo tudo para o seu CFO
A apresentação ao conselho que recebe aprovação não é a que promete o maior número de ROI. É a que é específica sobre o que está sendo medido, honesta sobre o que é difícil de provar e sequenciada de uma forma que constrói confiança organizacional.
Use os perfis de capacidade acima para enquadrar cada investimento com seu próprio modelo de mensuração, em vez de uma única afirmação de ROI combinada. "Nosso projeto Ingest visando a automação de contas a pagar mostra um ROI projetado de 3,2x contra uma linha de base mensurável" é uma declaração financiável. "A IA vai melhorar nosso negócio em 30%" não é.
Para as capacidades onde a atribuição é genuinamente difícil (Analyze, Generate, especialmente Predict), enquadre o investimento inicial como infraestrutura de mensuração: você está construindo a linha de base e o aparato de teste A/B para que o investimento em escala tenha ROI defensável. Isso é honesto, e é como as organizações que fazem isso bem realmente operam.
As 5 Dimensões do ROI em IA e Por Que o ROI em IA é Difícil de Provar estendem este framework mais adiante. Os SaaS AI Maturity Stages mapeiam a lógica de sequenciamento para o contexto do setor. E a Conversa com o CFO sobre Orçamento de IA mostra como traduzir perfis de ROI específicos por capacidade em linguagem orçamentária que recebe aprovação.
A visão específica por capacidade aqui é o ponto de partida. Entender que o ROI de Ingest e Generate é fácil de medir e médio em magnitude, enquanto o ROI de Predict é difícil de medir e potencialmente alto em magnitude, diz como fasejar seu investimento e como falar sobre ele com as pessoas que aprovam o orçamento.

Co-Founder, Rework.com