SaaS顧客のためのAIヘルススコアリング

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
シリーズB以降のほぼすべてのSaaS企業には顧客ヘルススコアがあります。CSM(Customer Success Manager)にそれを信頼しているか聞いてみると、ほとんどはマネージャーに何かを正当化する必要がある時に確認し、その後は直感に戻ると答えます。
これがルールベースのヘルススコアリングの失敗パターンです。概念が間違っているのではありません。実際のChurn結果からではなく委員会の意見によって設定されたウェイトで、すべてのアカウントに均一に適用されるルールは、技術的には入力されていても実質的には役に立たないスコアを生み出します。
AIヘルススコアリングは違います。AIが魔法だからではなく、モデルが「プロダクトマネージャーが重要と推測したこと」ではなく「このようなアカウントに実際に何が起きたか」で訓練されているからです。
ルールベースのスコアリングとAIヘルススコアリング
ルールベースのヘルススコアは通常このようになります。NPS(Net Promoter Score)が8以上で、ログイン頻度が週4回以上で、アカウントが過去3回のCSMメールに返答していれば、Greenとします。そうでなければYellow。キャンセルリクエストを提出したらRed。
このアプローチには2つの問題があります。
Key Facts:SaaSのためのAIヘルススコアリング
- 例外ベースのCSモデル(AIがリスクアカウントをフラグし、CSMがフラグされたアカウントのみを扱う)を導入した企業は、手動監視と比べて25〜40%高いリテンション率と、Customer Success人員投資に対して3〜5倍のROIを報告しています(Benchmarkit 2025 SaaSパフォーマンス指標)
- 80以上の行動シグナルで訓練されたAI Churnモデルは75〜82%の予測精度を達成しており、「選択肢を評価しています」のようなフレーズを検出するLLMベースのセンチメント埋め込みの追加によって2025〜2026年の最大の精度向上がもたらされ、90日以内のChurn確率が4〜6倍になることが示されています(Arete SaaS Research、2025年)
- SaaS企業の70%がAIをリテンション戦略に不可欠と考えており、市場はパイロット段階を過ぎてフルスケールのCS AI実装に移行し、18ヶ月以内にAIヘルススコアリングを業務上の基準にしています(EverAfter顧客Churn研究、2025年)
第一に、ウェイトが恣意的です。誰かがNPSは30点、ログイン頻度は20点と決めました。それらのウェイトはChurn履歴から導き出されたものではありません。チームが何が重要かについての信念を反映しており、実態と一致している場合もあればそうでない場合もあります。
第二に、ルールはすべてのアカウントを同じように扱います。500人のユーザーが週2回ログインするエンタープライズアカウントは、プロダクトを日常的なワークフローツールとして深く組み込んでいる可能性があります。毎日ログインする10人のユーザーのスタートアップは、競合他社とプロダクトを評価している可能性があります。生のシグナルは実際のリスクとは逆に見えます。
AIヘルススコアリングは実際のChurn履歴で訓練します。モデルはどのシグナルが、どの組み合わせで、どのアカウントで、Churnの結果の前に現れたかを学習します。ウェイトは何が重要かについての内部意見からではなくデータから導き出されます。Churn予測の行動モデリングに関する研究では、実際の結果で訓練された使用パターンシグナルがルールベースの閾値を上回り、トレーニングセットが成長するにつれてモデルの精度が大幅に向上することが確認されています。
結果として、CSMが実際に調べることができるスコアが生まれます。単なるGreenまたはRedのフラグではなく、「このアカウントのサポートチケットのセンチメントは過去45日間で悪化しており、この規模のアカウントで歴史的にこのパターンが見られた場合、68%の確率でChurnにつながっています」という理由コードが付きます。
このメカニズムを可能にしているのは、スコアの下で継続的に実行されているAnomaly Agentです。
下で動くAnomaly Agentパターン
ACE FrameworkでAIヘルススコアリングを考える正しい方法は、継続的なAnomaly Agentとしてです。モデルは月に一度アカウントをスコアリングしてダッシュボードを更新するのではありません。シグナルの継続的なストリームを取り込み、各アカウントの通常の行動のベースラインを確立し、そのベースラインからChurnリスクと歴史的に相関する方法で行動が逸脱した時にフラグを立てます。
Anomaly AgentパターンはIngest(継続的なシグナル)、Analyze(アカウント固有のベースラインからの逸脱)、Predict(Churnリスクの変化)、Execute(ワークフローのトリガーまたはアラート)を実行します。これは閾値ベースのアラートとは異なります。なぜならベースラインはアカウント固有だからです。通常高いデイリーエンゲージメントを持つアカウントでのログイン頻度の20%低下は、常に低頻度だったアカウントでの同じ低下より強いシグナルです。
そのアカウント固有性こそが、AIヘルススコアリングをルールよりも正確にする点です。また、実装をより難しくする点でもあります。意味のあるベースラインを確立するには、アカウントタイプごとに十分な過去データが必要です。
そのモデルに供給するシグナルが、出力の精度と実用性を決定します。
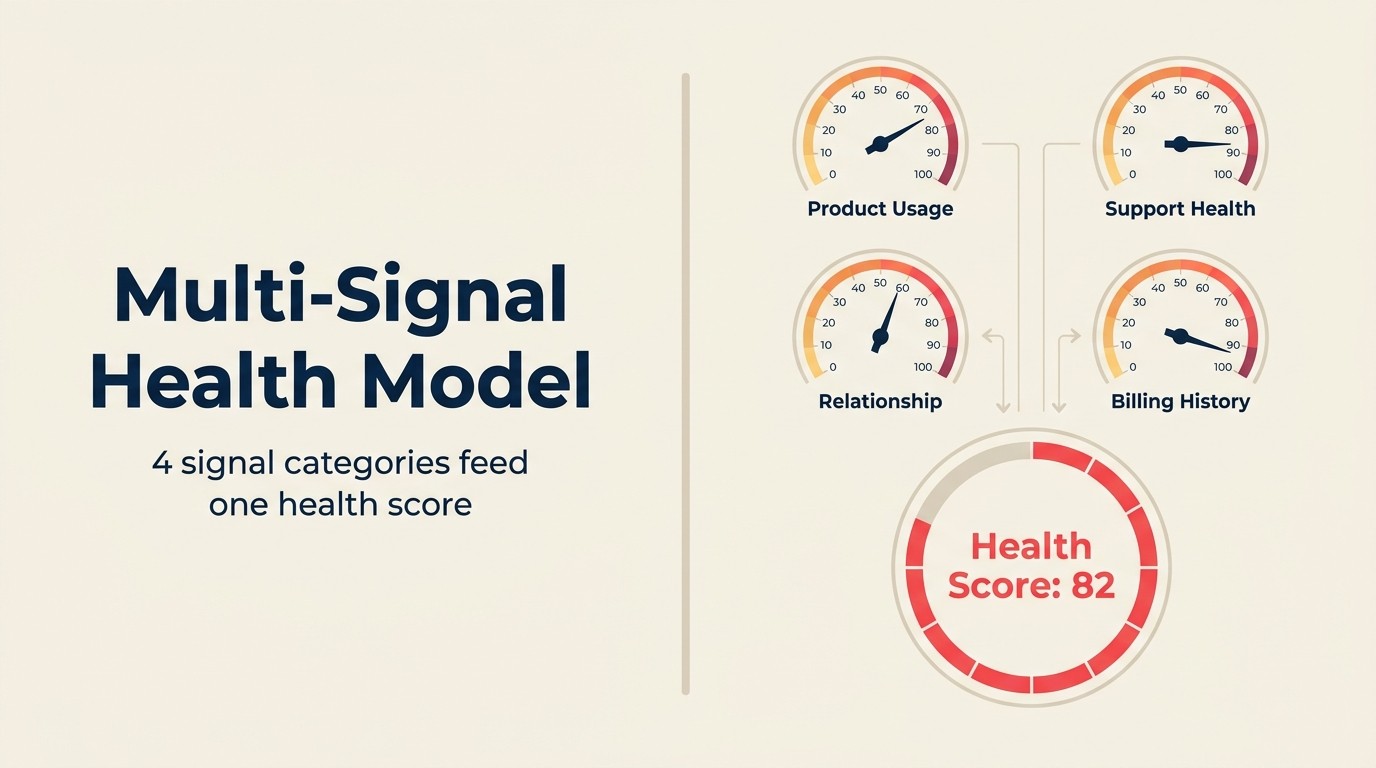
Multi-Signal Health Model
Multi-Signal Health Modelは、CSMが実際に信頼するスコアを生み出すAIヘルススコアリングのフレームワークです。使用シグナル(アカウント固有ベースラインに対するプロダクト行動のトレンド)、関係シグナル(コールセンチメント、CSMの応答率、チャンピオンの安定性)、商業シグナル(請求書のタイミング、契約使用率、価格ティアの適合度)、サポートセンチメントシグナル(チケット量のトレンド、エスカレーション率、満足度)を、可視的な理由コードを持つ複合スコアに組み合わせます。各シグナルカテゴリは独立して貢献し、ウェイトは委員会の前提ではなく実際のChurn結果から導き出されます。モデルは継続的なAnomaly Agentとして実行されます。週次のダッシュボードスコアを再計算するのではなく、アカウント固有のベースラインからのリアルタイムの逸脱を検出します。優れたMulti-Signal Health Modelの実用テスト:CSMは理由コードを読んで、なぜアカウントが色を変えたか、どのような行動をとるべきかをすぐに理解できるはずです。
シグナルカテゴリと実際に予測するもの
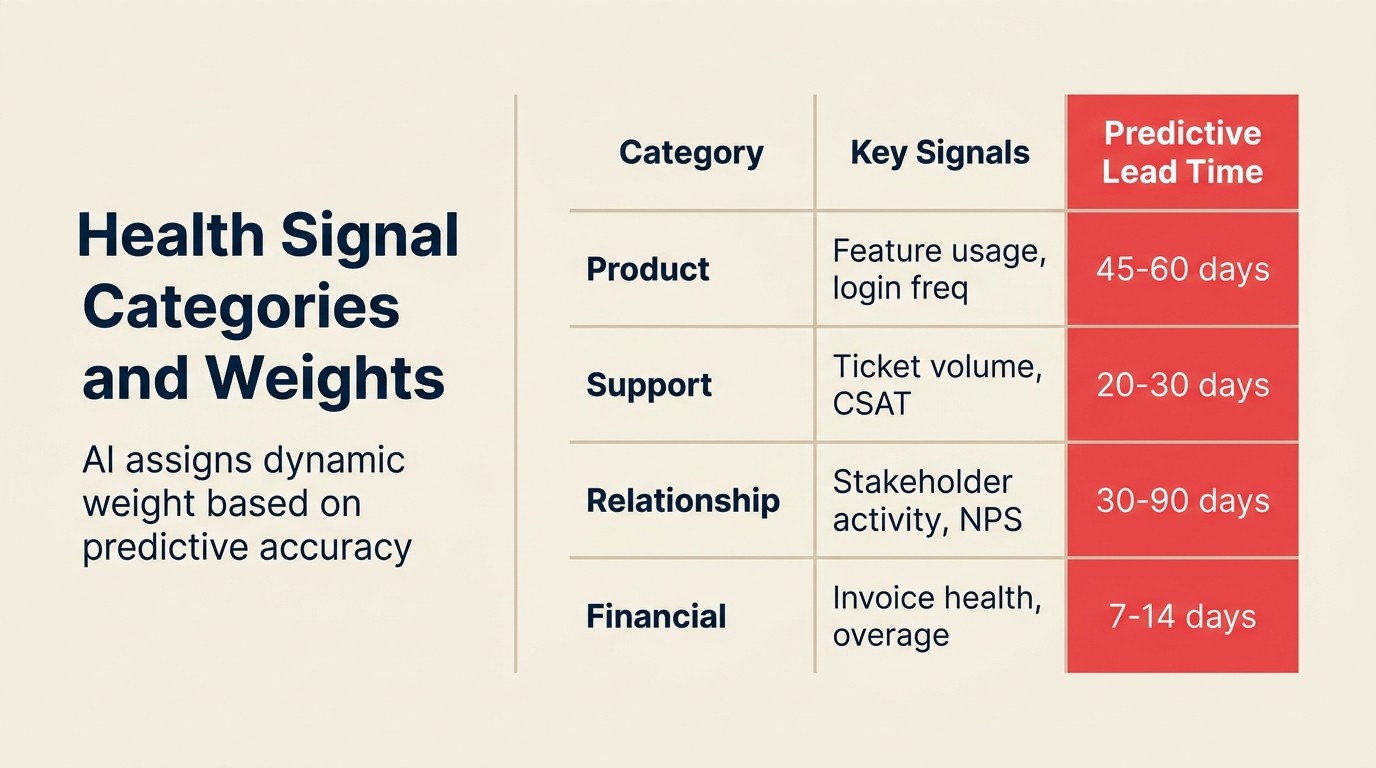
すべてのシグナルが等しいウェイトを持つわけではなく、ウェイトはプロダクトの種類と顧客セグメントによって異なります。4つの主要カテゴリの考え方を以下に示します。
プロダクト使用シグナル。 PLG(Product-Led Growth)企業や毎日のアクティブな使用が期待されるツールでは、これらのシグナルが最も高いウェイトを持ちます。ログイン頻度、機能採用の幅、アクティブなワークフロー、API呼び出し量のトレンド、コラボレーション指標(アクティブなチームメート数)が最も強い入力です。重要なのは絶対的なレベルではなくトレンドです。60日間使用量が低下しているアカウントは、同じ絶対的な使用量レベルでも横ばいのアカウントよりリスクが高いです。
関係品質シグナル。 これはハイタッチのエンタープライズアカウントに最も重要です。コール頻度、CSMの応答率、QBRの完了、NPSスコア、コールトランスクリプトからのセンチメント。チャンピオンが沈黙したら、それはシグナルです。CSMとのコールが継続的に延期されているなら、それはシグナルです。Meeting Intelligence(ACE Frameworkから)はコール録音を分析してセンチメントを時系列でスコアリングし、トーンがエンゲージメントから手続き的なものに変化した時にフラグを立てることができます。
商業健全性シグナル。 請求書の支払いタイミング、契約上限に対する使用量、価格や契約条件に異議を唱えるサポートチケットの数、更新会話の開始。これらは先行指標ではなく遅行シグナルですが、精度が高いです。請求書の明細項目に疑問を持ち始めるアカウントは、期限通りに支払うアカウントよりはるかにChurnしやすいです。
サポートセンチメントシグナル。 チケット量のトレンド、エスカレーション率、オープンチケットのテキストのトーン、解決時間の満足度評価、チケットが製品の問題についてか返金やキャンセルを求めるものかどうか。サポートチケットの急増と低い満足度評価の組み合わせは、最も強い短期Churn予測の1つです。
しかし、これらのシグナルは独自のChurn履歴に対してそれらを較正するトレーニングデータがある場合にのみ使用できます。
トレーニングセットの構築
これがほとんどのチームが行き詰まる部分です。AIヘルススコアリングには訓練のための過去データが必要であり、どんなデータでもよいわけではありません。
意味のあるChurn予測モデルを訓練するには、通常2〜3年のアカウント履歴とトレーニングセットに少なくとも100件のChurnしたアカウントが必要です。モデルはアカウントの種類、規模、プロダクト使用パターンにわたってChurnがどのように見えるかを学ぶ必要があります。ChurnベースがあまりにもSmallまたは均質すぎると、モデルは過学習して現在のポートフォリオのアカウントにはうまく汎化しません。ChartMogulのSaaSリテンションベンチマークは、トレーニングセットがまだ構築中の時に独自の過去データを補完できる、異なるARR(Annual Recurring Revenue)ステージでのChurn率のベンチマークを提供しています。
まだそのデータがない場合、AI ヘルススコアリングをスキップするのは正しい動きではありません。今すぐ適切に設計されたルールベースのスコアリングから始め、追跡しているすべてのシグナルをログし、体系的にトレーニングデータセットを構築し始めることです。Churnしたアカウントの記録と、その前の90日間のシグナル履歴を文書化してください。18ヶ月後には、AIベースのスコアリングへの移行を意味のあるものにするデータが揃います。
GainsightのAIヘルススコアリングはこのように機能します。顧客ベース全体のChurnパターンから得たGainsight独自のベンチマークデータから始めて、そのデータが積み上がるにつれて徐々にあなたの特定の過去パターンに適応できます。Planhatはシグナルアーキテクチャを定義してモデルが独自のアカウント履歴で訓練されるデータモデルアプローチを取ります。ChurnZeroは、独自のChurn履歴がまだ不十分な場合に役立つ、同様のステージの企業との業界ベンチマーク比較スコアを使用します。
適切に訓練されたモデルでも、スコア自体が誤った確信を生む問題があります。
誤った確信の問題
その後Churnするアカウントをグリーンと予測するヘルススコアは、スコアなしよりも悪いです。CSM(とCSリーダーシップ)に誤った確信を与え、介入が機能したウィンドウでのリスクアカウントへの投資不足につながります。
追跡すべき指標はRedの分類の精度です。モデルがRedと言った時、どのくらいの頻度でそれが正しいか?100件のアカウントをRedにフラグして80件が実際にChurnするモデル(80%の精度)は、100件をRedにフラグして40件がChurnするモデルよりはるかに実用的です。
ここにはトレードオフがあります。Redフラグの高い精度は、確信がある時のみアラームを上げることを意味し、実際にリスクのある一部のアカウントはフラグされません。高い再現率はより多くのリスクアカウントをフラグしますが、CSMの作業負荷を急増させてスコアへの信頼を損なう誤検知も多く生成します。
容量が限られているほとんどのCSチームにとって、精度は再現率より重要です。確実にChurnを予測するより少数の真にハイリスクなフラグは、CSMが本物のシグナルとノイズを区別できない包括的なリストより役に立ちます。
実際の結果に対してモデルを定期的にテストしてください。6ヶ月前にGreenと評価されたアカウントのコホートを取り上げましょう。何件がChurnしましたか?Redと評価されたコホートを取り上げましょう。何件が更新しましたか?これらのバックテストは、モデルが実際に結果を予測しているのか、単に遅れている行動を測定しているだけなのかを教えてくれます。
モデルの精度は前提条件です。しかしCSMにスコアに従って行動させることはより難しい問題です。
CSMの信頼と採用
CSMが無視するヘルススコアはゼロの価値を提供します。採用を得ることはテクノロジーの問題ではなく信頼の問題を解決することを必要とします。
CSMがヘルススコアを不信頼する理由は3つあります。第一に、スコアはあることを言い、自分の関係の感覚は別のことを言うが、スコアは修正を提出しても更新されることはない。第二に、スコアは説明なしに変わる。アカウントが一夜にしてYellowからRedに変わっても理由コードがない。第三に、スコアが間違っている場合、必要のないアカウントを追いかける時間が無駄になる。
これらのそれぞれは解決可能です。
理由コードを可視化しましょう。「使用量が低下したからRed」ではなく、「このアカウントのログイン頻度は過去30日で45%低下しており、このプロファイルのアカウントでこのパターンが見られた場合、90日以内にChurnする歴史的確率は72%です」というように。スコアの背景にある証拠を見ることができるCSMはそれに取り組みます。静かに上書きするのではなく。
上書きメカニズムを構築しましょう。CSMはスコアが不正確だとフラグして理由コードを追加できるべきです。それらの上書きがトレーニングデータになります。CSMが継続的に低使用量アカウントをGreenとマークし、それらが継続的に更新するなら、モデルはそのアカウントタイプでの低使用量はChurnシグナルでないことを学習します。
四半期ごとにキャリブレーションセッションを実施しましょう。CSチームを集め、モデルが正しかったアカウントと間違いを犯したアカウントを確認し、パターンを議論します。これはモデルが何をしているかの共通理解を構築し、透明性を通じて信頼を構築します。
信頼は採用をもたらします。採用はスコアが行動を促進する場合にのみ重要です。
ワークフロートリガーとしてのヘルススコア
ヘルススコアリングで最も重要な考え方の転換はこれです。スコアはダッシュボードの指標ではありません。ワークフローの入力です。
GreenからYellowへの変化はCSMタスクを自動的にトリガーすべきです。「アカウントXがYellowに変化しました。5営業日以内に使用データを確認してチェックインの予定を立ててください。」YellowからRedへの変化はエスカレーションをトリガーすべきです。CSMリードのレビュー、エグゼクティブスポンサーへのアウトリーチオプション、save playの開始。
そのワークフローの統合なしでは、ヘルススコアは取締役会の前に誰かが見るダッシュボードの数字に過ぎません。それがあれば、すべてのリスクシグナルが行動を生成します。
ヘルススコアのトリガーをオンにする前に、save playを先に構築しましょう。最も一般的な実装の間違いは応答ワークフローが存在する前にヘルススコアリングをアクティブ化することです。つまりアカウントがRedになった時、誰も何をすべきか知りません。システムはリスクを正確に特定しましたが、何も起きませんでした。
サブスクリプションモデルにおけるAI Churn予測では、コホートレベルの予測と介入タイミングの商業的な計算を含む予測モデリングレイヤーをより詳しく説明しています。
SaaS AIにおけるプロダクトテレメトリの優位性では、SaaS企業がヘルススコアリングにおいて他の業界にはない構造的なデータ優位性を持つ理由を説明しています。プロダクト自体がリアルタイムで最も予測性の高いシグナルを生成します。
より広いCSスタックとの接続
ヘルススコアリングは基盤です。拡張AI(UpsellとCross-sellに関するコンパニオン記事でカバー)はその上に構築されます。拡張の会話を推進する前にアカウントが健全であることを知る必要があります。健全性がYellowからRedのアカウントは拡張のアウトリーチを受けるべきではありません。
B2B SaaSのためのAI Customer Success Managerでは、ヘルススコアリングがQBR準備、拡張プレー、更新ワークフロー自動化と接続されたCSインテリジェンスシステムとしてどのように統合されるかを説明しています。
成功した状態の見え方
200件のエンタープライズアカウントを持つSaaS企業での成熟したAIヘルススコアリング実装はおおよそこのような形です。すべてのアカウントに毎日更新されるヘルススコアがあります。スコアにはそれを促進した主要なシグナルを説明する3〜5個の理由コードが付いています。CSMには今日、今週、今月対応が必要なフラグが立った変化のキューがあります。すべてのsave playの対話がトレーニングデータとしてシステムに記録されます。Gartnerの2025年のカスタマーサービス研究では、カスタマーサービスリーダーの85%が2025年にAIを試験運用または展開することを示しており、AI支援CSの運用成熟度が18ヶ月以内に差別化要因ではなく競争上の基準になります。
年2回、CS Opsチームはバックテストを実行し、6ヶ月前のスコアと実際のChurnおよび更新結果を比較します。精度が合意した閾値を下回ったら、モデルは再訓練されます。
そのシステムからのNRR(Net Revenue Retention)の改善は測定可能です。スコアが魔法だからではなく、プロアクティブなアウトリーチがまだ機能する90日ウィンドウの間にどのハイリスクアカウントも見逃されないことを確実にするからです。
CSMが信頼するスコアを構築しましょう。それを実際に使用するワークフローに接続しましょう。そしてそれが正しいアカウントを予測しているか測定しましょう。それ以外はすべて実装の詳細です。AIがSaaSの運用モデルをどのように再構成するかに関するより広いコンテキストについては、CS対ARR比率の議論をご参照ください。
ヘルスモデルにサポートセンチメントシグナル、特にサポートチケットとコールトランスクリプトのLLMベースの言語分析を追加することは、2025〜2026年の展開で最大の精度向上を一貫して生み出します。「選択肢を評価しています」や「期待していたROIが得られていません」のようなフレーズを使う顧客は、90日以内にChurnする確率が4〜6倍高くなります。純粋な使用量モデルはこのシグナルを検出できません。会話データにアクセスできるモデルのみが検出できます。(Arete SaaS Research、2025年)
Rework Analysis: 私たちが最も一貫して観察する実装の間違いは、save playワークフローを構築する前にヘルススコアのダッシュボードを作成することです。チームはヘルスの可視化に興奮し、アラートをアクティブ化し、アカウントがRedになった時に定義された応答を持ちません。CSMはアラートを見て何をすべきかわからず、何もせず、アカウントはChurnします。システムはリスクを正確に特定しました。人間が行動する準備ができていませんでした。機能するシーケンス:最初にsave playワークフローを設計し(健全性がRedになった時に何をするか?)、5つのリスクアカウントで手動でテストし、次にAIヘルスアラートをそのワークフローを自動的にトリガーするようにアクティブ化します。アラート量ではなく、save play実行率でシステムをスコアリングします。
| シグナルカテゴリ | ウェイト | 例 | 予測リードタイム |
|---|---|---|---|
| プロダクト使用シグナル | 最高(PLGと毎日使用ツール) | ログイン頻度トレンド、機能採用深度、API呼び出し量、コラボレーションの幅 | 3〜8週間 |
| 関係シグナル | エンタープライズアカウントに最高 | コールセンチメントトレンド、CSM応答率、QBR完了、チャンピオンの安定性 | 4〜8週間 |
| 商業シグナル | 高精度だが遅行 | 請求書の支払いタイミング、契約上限に対する使用量、価格ティアの会話開始 | 1〜3週間 |
| サポートセンチメント | 複合(フラストレーションに先行、キャンセルに遅行) | チケット量のトレンド、CSATの低下、エスカレーション率、チケットの言語分析 | 2〜6週間 |
出典:Gainsight、ChurnZero、Planhat、Arete SaaS Research(2024〜2025年)
よくある質問
AIヘルススコアリングとはどのようなもので、ルールベースのスコアリングとどう違うのですか?
AIヘルススコアリングは実際のChurn履歴で訓練して、前提からではなく結果からシグナルウェイトを導き出します。相対的な異常を検出します。均一に適用される絶対閾値ではなく、各アカウント独自の行動ベースラインからの逸脱。ルールベースのスコアは週5回未満のログインがあるアカウントをフラグします。AIヘルススコアは、独自の90日平均から40%低下したアカウントをフラグします。AIモデルは理由コードも生成します。「このアカウントのサポートチケットのセンチメントは45日間悪化しており、類似アカウントでこのパターンが見られた場合は歴史的に68%の確率でChurnにつながっています。」
Multi-Signal Health Modelとは何ですか?
Multi-Signal Health Modelは、信頼できるヘルススコアを生成するために4つのシグナルカテゴリを組み合わせるフレームワークです。使用シグナル(アカウント固有ベースラインに対するプロダクト行動)、関係シグナル(コールセンチメント、チャンピオンの安定性、CSM応答率)、商業シグナル(請求書のタイミング、ティアの適合度、契約使用率)、サポートセンチメントシグナル(チケット量のトレンド、チケット言語のLLM分析)。ウェイトは委員会の意見ではなく実際のChurn結果から導き出されます。モデルはリアルタイムの逸脱を検出する継続的なAnomaly Agentとして実行されます。
AIヘルススコアリングにはどのようなトレーニングデータが必要ですか?
意味のあるChurn予測には2〜3年のアカウント履歴とトレーニングセットに少なくとも100件のChurnしたアカウントが必要です。データが不十分な場合、今すぐ適切に設計されたルールベースのスコアリングから始め、すべてのシグナルを体系的に記録し、Churnするアカウントの90日前のシグナル履歴を文書化しましょう。18ヶ月後にはトレーニングデータが揃います。GainsightはChurn顧客ベース全体のベンチマークデータからブートストラップできます。PlanhatはGainsightの顧客履歴を使用します。ChurnZeroはトレーニングデータが限られている場合に業界ベンチマークを使用します。
CSMにヘルススコアを信頼して使用させるにはどうすればよいですか?
3つの具体的な信頼の問題を解決します。理由コードを可視化します。「使用量が低下したからRed」ではなく、特定のパターンと類似アカウントでのChurnの歴史的な確率を示します。上書きメカニズムを構築します。CSMは不正確なスコアをフラグしてその理由を追加でき、それがトレーニングデータになります。四半期ごとにキャリブレーションセッションを実施します。モデルが正しかったケースと間違いのケースをチームで確認します。モデルの推論を調べることができるCSMはそれに取り組みます。説明できない色だけを見るCSMは静かに無視します。
AIヘルススコアリングの正しい実装シーケンスは何ですか?
最初にsave playワークフローを設計し(健全性がRedになった時に何をするか?)、5つのリスクアカウントで手動でテストし、次にAIアラートをそのワークフローを自動的にトリガーするようにアクティブ化します。これにより最も一般的な実装の失敗が防がれます。チームがヘルスダッシュボードを構築し、アラートをアクティブ化し、定義された応答がなく、行動しないアラートをCSMが見るという状況です。アラート量ではなく、save play実行率でシステムをスコアリングします。
ヘルスモデルで最大の精度向上をもたらすシグナルカテゴリはどれですか?
サポートセンチメントシグナル、特にサポートチケットとコールトランスクリプトのLLMベースの言語分析です。「選択肢を評価しています」のようなフレーズを使う顧客は、90日以内にChurnする確率が4〜6倍高くなります。純粋な使用量モデルはこれを検出できません。使用量モデルの上にセンチメントシグナルレイヤーを追加した企業は、会話の言語がどんな使用量の低下より先に顧客の決断状態を反映するため、2025〜2026年の展開で最も大きな精度のジャンプを報告しています。
関連記事:
