AI Incident Response Playbook: Wie Sie reagieren, wenn AI versagt

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ein AI-Chatbot teilt einem Kunden mit, er habe Anspruch auf eine Erstattung, die ihm nicht zusteht. Ein AI-Summarizer lässt bei einer Due-Diligence-Prüfung eine kritische Vertragsklausel aus, und die Auslassung wird erst nach der Unterzeichnung bemerkt. Ein AI-Lead-Scoring-Modell beginnt, Ihre wertvollsten Interessenten an die falschen Vertriebsmitarbeiter weiterzuleiten, und niemand bemerkt dies drei Wochen lang.
Das sind AI-Vorfälle. Und sie unterscheiden sich von den IT-Vorfällen, mit denen Ihr Team bereits vertraut ist.
Erkennt Ihr Incident-Response-Prozess den Unterschied? Wenn nicht, reagieren Sie zu langsam auf die falschen Signale, eskalieren die falschen Dinge und übersehen Probleme, die still hunderte von Entscheidungen beeinflussen, bevor jemand etwas bemerkt.
Dieses Playbook richtet sich an Chief Information Officers (CIOs), Sicherheitsverantwortliche und Transformationsteams, die ihre erste AI-spezifische Incident-Response-Fähigkeit aufbauen oder prüfen, ob ihr bestehender Prozess ausreicht. Es verbindet sich mit dem Aufbau Ihrer AI-Nutzungsrichtlinie (die den autorisierten AI-Umfang definiert) und Audit Trails für AI Execute-Aktionen (das die Beweisgrundlage für Untersuchungen liefert).
Wie AI-Vorfälle sich von IT-Vorfällen unterscheiden

Key Facts: AI Incident-Risiko
- GDPR Artikel 33 verlangt eine Meldung an die zuständige Aufsichtsbehörde innerhalb von 72 Stunden nach Bekanntwerden einer Verletzung personenbezogener Daten; die 72-Stunden-Frist beginnt, wenn die Organisation von dem Vorfall erfährt, nicht wenn die Untersuchung abgeschlossen ist (GDPR Artikel 33)
- AI-Vorfallskategorien umfassen Halluzination, Execute-Fehler, Bias, Datenschutzverletzung und Model Drift; die traditionelle IT-Incident-Response (die auf binären Ausfällen aufbaut) übersieht die latente, probabilistische Natur von AI-Fehlern, die hunderte von Entscheidungen beeinflussen können, bevor sie entdeckt werden (NIST Cybersecurity Framework)
- Gartner prognostiziert, dass über 40 % der agentischen AI-Projekte bis 2027 eingestellt werden, wobei fehlende Governance-Frameworks die Hauptursache sind; Incident-Response-Infrastruktur ist eine der drei am häufigsten fehlenden Governance-Komponenten (Gartner, 2025)
Die traditionelle IT-Incident-Response basiert auf einem einfachen Modell: Systeme sind entweder verfügbar oder nicht. Ein Server geht offline, ein Dienst gibt einen 500-Fehler zurück, eine Netzwerkverbindung fällt aus. Der Vorfall ist binär und unmittelbar. Die Erkennung ist schnell, meist automatisiert. Die Behebung ist technischer Natur: den Dienst wiederherstellen.
AI-Vorfälle funktionieren nicht so. Die Respond-Funktion des NIST Cybersecurity Framework beschreibt Incident Response als das Eindämmen und Managen von Auswirkungen erkannter Ereignisse, aber das CSF wurde rund um binäre, erkennbare technische Ausfälle konzipiert. AI-Vorfälle erfordern ein deutlich anderes Erkennungs- und Reaktionsmodell.
Sie sind probabilistisch. Ein AI-System, das "meistens" einwandfrei funktioniert, trifft möglicherweise für eine bestimmte Eingabe-Teilpopulation falsche Entscheidungen: ein bestimmtes Kundensegment, ein bestimmter Dokumenttyp, eine bestimmte Sprache. Die Gesamtgenauigkeitsmetriken sehen akzeptabel aus. Der Randbereich versagt gravierend.
Sie sind latent. Ein verzerrtes Scoring-Modell, eine halluzinierende Wissensbasis, eine Prompt-Injection-Schwachstelle -- diese können Wochen oder Monate in Betrieb sein, bevor jemand etwas bemerkt. Das IT-Incident-Äquivalent wäre ein Server, der stillschweigend 3 % der Zeit Daten beschädigt, anstatt vollständig auszufallen.
Sie sind oft unsichtbar, bis sie schwerwiegend werden. Ein AI, der Kunden falsche Informationen sendet, diskriminierende Entscheidungen bei Einstellungen trifft oder Daten in einen Prompt-Kontext verliert, erzeugt keinen 500-Fehler. Er erzeugt eine Kundenbeschwerde, eine Regulierungsanfrage oder den Anruf eines Journalisten. Dies ist einer der Governance-Fehlermodi, die sonst gut finanzierte AI-Transformationen zum Scheitern bringen.
Die Ursache ist schwerer zu finden. IT-Vorfälle haben technische Ursachen: eine Fehlkonfiguration, ein Code-Fehler, ein Hardwareausfall. AI-Vorfälle können auf Modellverhalten zurückzuführen sein (das Modell würde bei diesem Eingabetyp immer versagen), auf Prompt-Design (der Prompt ist bei bestimmten Grenzfällen inkonsistent), auf Datenqualität (die Trainings- oder Abrufdaten waren falsch), auf Integrationsfehler (die richtige Ausgabe wurde erzeugt, aber die falsche Aktion wurde ausgeführt) oder auf Nutzerverhalten (Menschen begannen das Tool auf eine Weise zu nutzen, für die es nicht konzipiert wurde).
Jeder Ursachentyp erfordert eine andere Reaktion.
"AI-Vorfälle kündigen sich nicht mit einem 500-Fehler an. Ein verzerrtes Scoring-Modell kann monatelang laufen, bevor es jemand bemerkt. Ein AI, der Kunden falsche Informationen sendet, stürzt nicht ab. Er erzeugt eine Kundenbeschwerde. Der Incident-Response-Prozess, der bei IT-Ausfällen funktioniert, übersieht die Mehrheit der AI-Fehler, bis sie zu Krisen werden." (Rework)
Die 4-Typ-AI-Incident-Taxonomie
Ein Klassifizierungsrahmen zur Kategorisierung von AI-Vorfällen nach Ursachentyp, der eine schnellere Diagnose und zielgerichtetere Reaktion ermöglicht. Typ 1 (Halluzination): AI generierte sachlich falsche Inhalte, auf die reagiert wurde. Typ 2 (Execute-Fehler): AI führte eine folgenreiche Aktion falsch aus, mit realen Konsequenzen. Typ 3 (Bias): AI traf systematisch diskriminierende Entscheidungen, die eine Teilpopulation betreffen; höchstes regulatorisches Risiko. Typ 4 (Datenschutzverletzung): Prompt-Eingabe oder AI-Ausgabe offenbarte Informationen, die hätten geschützt sein sollen; kann die 72-Stunden-Meldepflicht gemäß GDPR Artikel 33 auslösen. Typ 5 (Model Drift): AI-Leistung hat sich im Laufe der Zeit ohne einen einzelnen erkennbaren Fehlerzeitpunkt verschlechtert; der am häufigsten übersehene Vorfallstyp. Jeder Typ hat ein eigenes Erkennungssignal, eine eigene Reaktionszeit und einen eigenen Ansatz zur Ursachenanalyse.
AI-Incident-Taxonomie
Bevor Sie auf einen AI-Vorfall reagieren können, müssen Sie wissen, um welche Art von Vorfall es sich handelt.
Typ 1: Halluzinations-Vorfall
Der AI generierte sachlich falsche Inhalte, auf die reagiert wurde. Ein Kunde erhielt falsche Informationen zu seinem Versicherungsschutz. Ein Support-Agent nutzte eine AI-generierte Antwort, um ein Ticket falsch zu lösen. Ein AI-geschriebenes Dokument enthielt erfundene Zitate.
Erkennungssignal: Kundenbeschwerde, interne Qualitätsprüfung, Mitarbeitermeldung, nachgelagerter Systemfehler durch Handeln auf Basis falscher Informationen.
Wichtige Fragen bei der Reaktion: Wurde die Ausgabe vor der Nutzung geprüft? War dies ein Einzelfall oder halluziniert das Modell bei diesem Fragetyp konsistent? Gibt es eine Prompt-Änderung, die das Problem beheben würde?
Typ 2: Execute-Fehler
Der AI führte eine folgenreiche Aktion falsch aus. Dies ist der zeitkritischste Vorfallstyp, da Execute-Aktionen den Zustand der Welt verändern. Falsche Erstattung ausgestellt. E-Mail an die falsche Empfängerliste gesendet. CRM-Datensätze mit falschen Daten aktualisiert. Workflow ausgelöst, der nicht hätte ausgelöst werden sollen.
Erkennungssignal: Kundenbeschwerde, Diskrepanz bei der Finanzabstimmung, Fehler im nachgelagerten Prozess, Mitarbeitermeldung.
Wichtige Fragen bei der Reaktion: Kann die Aktion rückgängig gemacht werden? Wenn ja, wer ist befugt, sie rückgängig zu machen und wie? Wer war betroffen? Liegt die Ursache im AI-Modell, der Trigger-Logik oder der Integration zwischen AI-Ausgabe und dem externen System?
Typ 3: Bias-Vorfall
Der AI traf systematisch diskriminierende Entscheidungen. Ein Scoring-Modell leitete Kandidaten einer bestimmten demografischen Gruppe überproportional zur Ablehnung weiter. Ein kreditnahes AI lehnte Anträge für verschiedene geschützte Klassen mit unterschiedlichen Raten ab. Ein Einstellungs-AI filterte Kandidaten auf Basis von Faktoren heraus, die mit geschützten Merkmalen korrelieren.
Erkennungssignal: demografisches Audit der Ergebnisse, Mitarbeitermeldung, Regulierungsanfrage, rechtliche Anfechtung durch eine betroffene Person.
Wichtige Fragen bei der Reaktion: Wie lange lief das System mit diesem Bias? Wie viele Personen waren betroffen? Welche Entschädigung wird betroffenen Parteien geschuldet? Ist dieses Modell noch in der Produktion?
Dieser Vorfallstyp hat das schwerwiegendste regulatorische Risiko. Rechtsbeistand muss sofort einbezogen werden.
Typ 4: Datenschutzverletzungs-Vorfall
Prompt-Eingabe oder AI-Ausgabe offenbarte Informationen, die hätten geschützt sein sollen. Die Informationen von Kunde A erschienen in der AI-Antwort für Kunde B. Personenbezogene Daten eines Mitarbeiters wurden in einen Prompt-Kontext aufgenommen, auf den nicht autorisierte Nutzer Zugriff hatten. Vertrauliche interne Daten wurden an das AI-System eines Anbieters gesendet, das nicht zum Empfang autorisiert war.
Erkennungssignal: Kundenbeschwerde über das Sehen der Daten eines anderen Nutzers, internes Audit, Mitarbeitermeldung, Monitoring-Alert bei Datenschutzverletzungen.
Wichtige Fragen bei der Reaktion: Welche Daten wurden offenbart? An wen? Handelte es sich um personenbezogene Daten (PII), geschützte Gesundheitsinformationen (PHI), Finanzdaten oder vertrauliche Geschäftsdaten? War dies ein Einzelereignis oder ein systematischer Fehler?
GDPR Artikel 33 Hinweis: Wenn die Offenbarung personenbezogene Daten von EU-Bürgern betraf, haben Sie möglicherweise eine 72-Stunden-Meldepflicht gegenüber der zuständigen Aufsichtsbehörde. Das ist nicht optional. Die Frist beginnt, wenn Sie von dem Vorfall erfahren, nicht wenn Sie die Untersuchung abschließen.
Typ 5: Model Drift
Die AI-Leistung hat sich im Laufe der Zeit verschlechtert, ohne dass jemand es bemerkt hat. Das Scoring-Modell mit 78 % Genauigkeit in Q1 liegt in Q3 bei 61 %. Das Retrieval-System, das korrekte Dokumente zurücklieferte, gibt nun veraltete zurück. Die Generierungsqualität, die akzeptabel war, hat sich verschlechtert, als sich Modell oder Retrieval-Kontext verändert haben.
Erkennungssignal: Monitoring-Metriken (falls Sie diese aufgebaut haben), Geschäftsergebnis-Metriken (sinkende Lead-Conversion-Rate, sinkende Kundenzufriedenheit, sinkende Qualität der Support-Ticket-Lösung), Mitarbeitermeldungen, dass das AI "nicht mehr so gut wie früher ist".
Dies ist der Vorfallstyp, der am häufigsten übersehen wird, weil es keinen einzelnen Fehlerzeitpunkt gibt. Er akkumuliert sich.
Der 4-stufige Reaktionsrahmen

Sobald Sie den Vorfallstyp identifiziert haben, bestimmt die Stufe, wer reagiert, wie schnell und was zuerst passiert.
Stufe 4: Untersuchen
Kriterien: Interner AI-Ausgabefehler, keine externe Exposition, noch keine Kundenauswirkung. Eine intern bei der Qualitätsprüfung entdeckte Halluzination. Eine Generate-Ausgabe, die falsch war, aber nicht umgesetzt wurde. Model Drift, der durch internes Monitoring erkannt wurde, bevor er Ergebnisse beeinflusst hat.
Reaktionsfenster: 24 Stunden bis zur ersten Bewertung.
Wer reagiert: Das für das AI-System zuständige Team. Keine Eskalation erforderlich, es sei denn, die Bewertung zeigt externe Exposition.
Aktionen: Vorfall im AI-Risikoregister dokumentieren. Ursache ermitteln. Bewerten, ob das Problem systemisch oder isoliert ist. Korrektur oder Workaround implementieren. Post-Incident-Review ansetzen.
Stufe 3: Eindämmen
Kriterien: Kundenseitige fehlerhafte Ausgabe, auf die der Kunde nicht reagiert hat. Eine Chatbot-Antwort, die falsch war, aber der Kunde nicht darauf reagiert hat. Ein Entwurfs-E-Mail mit falschen Informationen, der vor dem Versenden aufgefangen wurde.
Reaktionsfenster: 4 Stunden bis zur Eindämmungsentscheidung.
Wer reagiert: Teamleiter plus IT-Sicherheitskontakt. Management-Benachrichtigung (keine Eskalation zum CIO erforderlich, es sei denn, es wird zu Stufe 2 oder höher).
Aktionen: Problem eindämmen (betroffene AI-Funktion deaktivieren, falls sie weiterhin falsche Ausgaben erzeugt). Reichweite bewerten: War dieser Kunde betroffen, oder möglicherweise andere? Dokumentieren. Bestimmen, ob eine proaktive Kundenkommunikation angemessen ist (in der Regel nicht für Stufe 3, es sei denn, die fehlerhafte Ausgabe könnte dem Kunden schaden, wenn er später danach handelt).
Stufe 2: Incident Response
Kriterien: Kundenseitiger Execute-Fehler, eingedämmter Datenschutzverletzungsvorfall, Halluzination, auf die Kunden reagiert haben.
Reaktionsfenster: 1 Stunde bis zur ersten Reaktion, fortlaufendes Management bis zur Lösung.
Wer reagiert: CIO und Sicherheitsverantwortlicher werden innerhalb der Stunde benachrichtigt. Rechtsbeistand in Bereitschaft. Kommunikationsteam für die Ausarbeitung von Kundenbenachrichtigungen eingebunden.
Aktionen: Auswirkung bewerten (wie viele Kunden, welche Daten, welche Maßnahmen ergriffen). Eindämmen (betroffenen Workflow deaktivieren, Execute-Aktionen wo möglich rückgängig machen). Kundenkommunikationsplan: Müssen betroffene Kunden benachrichtigt werden? Was müssen sie wissen? Regulatorische Meldungsbewertung: Stellt dies eine meldepflichtige Verletzung gemäß GDPR Artikel 33 dar? Alles in Echtzeit dokumentieren.
Stufe 1: Krise
Kriterien: Regulatorisches Risiko ist bestätigt oder wahrscheinlich, große Kundenauswirkung, Bias-Vorfall mit betroffenen Personen, Datenschutzverletzung mit sensiblen personenbezogenen Daten im größeren Maßstab.
Reaktionsfenster: Sofort. Der Chief Executive Officer (CEO) und der General Counsel müssen innerhalb der ersten Stunde informiert sein.
Wer reagiert: Unternehmensführung, Rechtsbeistand, externe Kommunikation, Regulierungsabteilung falls zutreffend.
Aktionen: Führungsentscheidung, ob das AI-System bis zum Abschluss der Untersuchung vollständig ausgesetzt werden soll. Externer Rechtsbeistand einbezogen. Kunden- und Behördenkommunikation ausgearbeitet und geprüft. Post-Krisen-Review angesetzt. Wenn EU-Personaldaten betroffen sind und die Verletzung meldepflichtig ist, läuft die 72-Stunden-Frist gemäß GDPR Artikel 33.
GDPR Artikel 33 und Meldepflichten
GDPR Artikel 33 verlangt eine Meldung an die zuständige Aufsichtsbehörde innerhalb von 72 Stunden nach Bekanntwerden einer Verletzung personenbezogener Daten, es sei denn, die Verletzung "führt voraussichtlich nicht zu einem Risiko für die Rechte und Freiheiten natürlicher Personen".
Ein AI-Vorfall kann eine Verletzung personenbezogener Daten darstellen, wenn:
- Ein AI-System personenbezogene Daten auf eine Weise verarbeitete, die zu einer unbefugten Offenbarung führte
- Eine AI-Ausgabe mit personenbezogenen Daten an einen nicht autorisierten Empfänger gesendet wurde
- Ein AI-System eine automatisierte Entscheidung unter Verwendung personenbezogener Daten auf eine Weise traf, die den betroffenen Personen nicht mitgeteilt worden war
- Prompt Injection oder andere Ausnutzung zu einer Datenexfiltration führte
Die 72-Stunden-Frist beginnt, wenn Sie von der Verletzung erfahren, nicht wenn die Untersuchung abgeschlossen ist. Sie können eine erste Meldung einreichen, die besagt: "Wir sind uns eines Vorfalls bewusst, die Untersuchung läuft" und sie später ergänzen. Es ist nicht konform, bis zum Abschluss der Untersuchung mit der Meldung zu warten.
Für US-amerikanische Organisationen in regulierten Branchen gelten analoge Anforderungen: die HIPAA Breach Notification Rule für PHI-Verletzungen, SEC-Vorschriften zur Offenlegung von Cybersicherheitsvorfällen für wesentliche Cybersicherheitsvorfälle und staatliche Datenschutzverletzungs-Meldungsgesetze.
Post-Incident-Review: AI-Ursachenanalyse
Der Post-Incident-Review für einen AI-Vorfall folgt einer anderen Struktur als das Standard-IT-Post-Mortem.
IT-Post-Mortems fragen: Welcher technische Fehler hat den Ausfall verursacht? Den technischen Fehler beheben, den Dienst wiederherstellen.
AI-Post-Incident-Reviews stellen vier Fragen:
War dies ein Modellversagen? Produzierte der AI eine fehlerhafte Ausgabe, weil das zugrunde liegende Modell falsch war, halluzinierte oder bei diesem Eingabetyp schlecht abschnitt? Wenn ja: Welche Prompt-Änderungen, Retrieval-Verbesserungen oder Modellaktualisierungen würden ein Wiederauftreten verhindern? Sollte dieses Modell weiterhin für diesen Anwendungsfall eingesetzt werden?
War dies ein Prompt- oder Design-Versagen? Produzierte der AI eine fehlerhafte Ausgabe, weil der Prompt mehrdeutig war, das Kontextfenster unzureichend war oder der Workflow nicht für diese Eingabe konzipiert war? Wenn ja: Dies ist oft die am leichtesten behebbare Ursache. Überarbeiten Sie die Prompt-Vorlage, fügen Sie Eingabevalidierung hinzu oder fügen Sie Guardrails ein.
War dies ein Datenversagen? Produzierte der AI eine fehlerhafte Ausgabe, weil die Retrieval-Daten veraltet waren, die Trainingsdaten verzerrt waren oder die Eingabedaten fehlerhaft waren? Wenn ja: Data Governance ist die Lösung, nicht das Modell.
War dies ein Integrationsversagen? Produzierte der AI die richtige Ausgabe, aber die Integration zwischen dem AI-System und dem nachgelagerten Execute-System versagte? Wenn ja: Die AI-Governance-Ursache ist weniger wichtig als die Integrations-Engineering-Lösung. Aber auch: Gab es einen menschlichen Prüfschritt, der dies vor der Ausführung hätte auffangen sollen?
Dokumentieren Sie die Ursache im AI-Risikoregister. Aktualisieren Sie die relevanten AI-Governance-Dokumente. Wenn der Vorfall eine Lücke in Ihrem Human-in-the-Loop-Design aufgedeckt hat, schließen Sie die Lücke.
Eine Meldekultur aufbauen
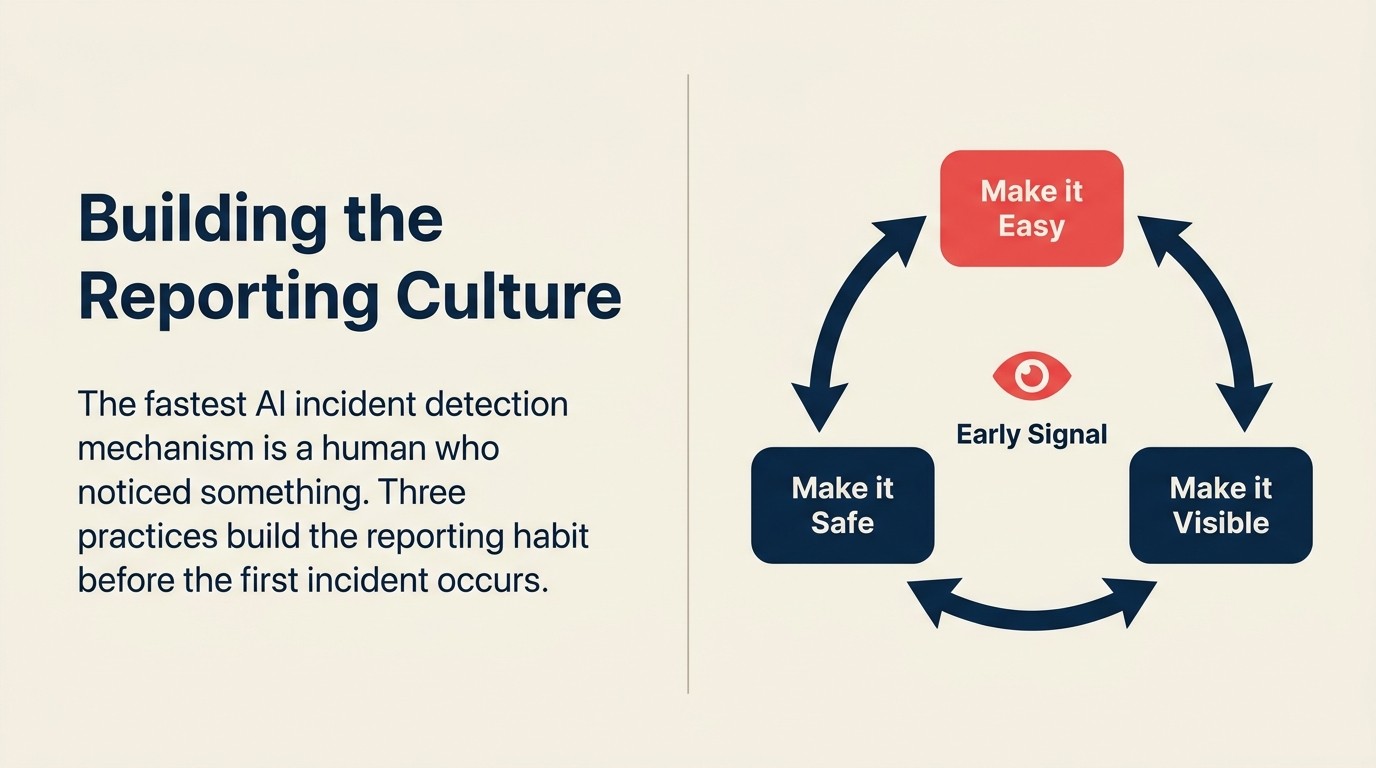
Die gefährlichste Lücke in jedem AI-Incident-Response-Programm ist nicht das Playbook. Es sind die Mitarbeiter, die ein Problem sehen und es nicht melden.
Ein Mitarbeiter, der bemerkte, dass der AI-Chatbot letzten Dienstag falsche Erstattungsinformationen gab. Ein Ingenieur, der ein anomales Muster in den AI-Ausgabe-Logs sah, aber nicht sicher war, ob es wichtig war. Ein Customer Success Manager, der eine Beschwerde über eine AI-generierte Empfehlung hörte, sie aber als Einzelfall abtat.
Jedes dieser Ereignisse ist ein frühes Signal. Die meisten AI-Vorfälle, die zu Krisen werden, begannen als Signale, die gesehen aber nicht weiterverfolgt wurden.
Eine Meldekultur aufzubauen bedeutet drei Dinge:
Melden einfach machen. Ein interner Kanal, ein Formular, eine E-Mail-Adresse. Mitarbeiter sollten sich nicht durch Organisationshierarchien arbeiten müssen, um ein potenzielles AI-Problem zu melden.
Melden sicher machen. Mitarbeiter, die Probleme melden, dürfen nicht für den Vorfall oder für einen falschen Alarm verantwortlich gemacht werden. Die Reaktion auf eine Meldung, auch wenn sie sich als Nicht-Vorfall herausstellt, sollte "Danke, dass Sie das gemeldet haben" sein. Wenn Melder sich schuldig fühlen, hören sie auf zu melden.
Melden sichtbar machen. Wenn eine Meldung dazu führt, dass ein echter Vorfall frühzeitig aufgefangen wird, teilen Sie das dem Team mit. Nicht "wir hatten einen schwerwiegenden Vorfall", sondern "weil jemand letzte Woche eine Anomalie gemeldet hat, haben wir ein Problem aufgefangen, bevor es Kunden betroffen hat". Sozialer Beweis, dass Melden wichtig ist, baut die Gewohnheit auf.
Die Governance-Dokumente, die Audit Trails und die Reaktionsstufen dienen alle dazu, Vorfälle nach ihrem Auftreten zu managen. Die Meldekultur bestimmt, ob Sie früh oder spät von Problemen erfahren.
Was dieses Playbook nicht ersetzt
Dieses Playbook regelt die AI-spezifische Incident Response. Es ersetzt nicht Ihren bestehenden IT-Incident-Response-Prozess, Ihren Datenschutzverletzungs-Reaktionsprozess gemäß GDPR oder CCPA (California Consumer Privacy Act) oder Ihren HR-Incident-Prozess für diskriminierungsbezogene Beschwerden. Diese Prozesse gelten weiterhin. Bei Vorfällen, die sowohl einen AI-Fehler als auch eine Datenschutzverletzung beinhalten, laufen beide Playbooks parallel.
Verbinden Sie dieses Playbook mit Ihrem Audit Trail-Framework, das die Beweise liefert, die Sie bei der Vorfallsuntersuchung benötigen werden. Verbinden Sie es mit Ihrer AI-Nutzungsrichtlinie, die den autorisierten Umfang von AI-Aktionen definiert. Und verbinden Sie es mit Ihrem AI-Risikoregister, wo bekannte Risikomuster aus vergangenen Vorfällen dokumentiert werden, damit zukünftige Vorfälle schneller erkannt werden.
Rework-Analyse: Basierend auf Enterprise-AI-Incident-Mustern ist der häufigste Grund, warum kleinere AI-Vorfälle zu Krisen eskalieren, nicht der Vorfall selbst, sondern die Erkennungsverzögerung. Ein Bias-Vorfall, der 15 % der Ausgaben eines Scoring-Modells betrifft, kann 8-12 Wochen laufen, bevor er in Geschäftsmetriken erscheint. Eine Datenschutzverletzung in einem gemeinsamen AI-Kontext kann nicht auftauchen, bis ein Kunde berichtet, die Daten eines anderen Nutzers gesehen zu haben. Der Abschnitt zur Meldekultur in diesem Playbook existiert, weil der schnellste Erkennungsmechanismus ein Mensch ist, der etwas bemerkt hat und es gemeldet hat. Jede Woche Erkennungsverzögerung vervielfacht das regulatorische Risiko, die Anzahl betroffener Kunden und die Komplexität der Abhilfe.
Das Ziel ist nicht, ein Playbook zu haben, das Sie nie benutzen müssen. Es geht darum, bereit zu sein, wenn Sie es tun.
Und die Unternehmen, die die saubersten Incident Responses durchführen, sind diejenigen, die die Meldekultur lange vor dem ersten Vorfall aufgebaut haben. Die eigentliche Frage lautet daher: Weiß Ihr Team, wohin es sich wenden soll, wenn es etwas Falsches sieht?
Siehe auch:
- AI Approval Gates und Anbieterprüfung: das Pre-Deployment-Gate, das reduziert, wie oft Sie dieses Playbook benötigen werden
- Datenklassifizierung für AI-Zugriffsregeln: das Datentier-Framework, das bestimmt, ob ein Typ-4-Vorfall eine Datenschutzverletzungsmeldung erfordert
- Stufe 3 zu 4: Von Scaled zu Integrated: warum formelle Incident Response ab Stufe 4 nicht optional wird
- Die 18-Monats-CEO-AI-Agenda: wo Incident-Response-Infrastruktur in Phase 1 der Transformations-Roadmap passt

Co-Founder, Rework.com
On this page
- Wie AI-Vorfälle sich von IT-Vorfällen unterscheiden
- Die 4-Typ-AI-Incident-Taxonomie
- AI-Incident-Taxonomie
- Typ 1: Halluzinations-Vorfall
- Typ 2: Execute-Fehler
- Typ 3: Bias-Vorfall
- Typ 4: Datenschutzverletzungs-Vorfall
- Typ 5: Model Drift
- Der 4-stufige Reaktionsrahmen
- Stufe 4: Untersuchen
- Stufe 3: Eindämmen
- Stufe 2: Incident Response
- Stufe 1: Krise
- GDPR Artikel 33 und Meldepflichten
- Post-Incident-Review: AI-Ursachenanalyse
- Eine Meldekultur aufbauen
- Was dieses Playbook nicht ersetzt