AI-Anbieter-Lock-in: Minderungsstrategien für CIOs und CTOs
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ihre Organisation hat 2024 GPT-4 für ihre AI-Infrastruktur gewählt. Sie haben 15 interne Tools darauf aufgebaut. Ihr Prompt-Engineering-Team hat drei Monate damit verbracht, System-Prompts und Few-Shot-Beispiele zu optimieren. Ihre Entwickler haben benutzerdefinierte API-Integrationen über sechs interne Systeme aufgebaut.
Dann hat OpenAI die Enterprise-API-Preise um 40 % erhöht. Oder das Modell mit 6-monatiger Ankündigung eingestellt. Oder Anthropic hat ein Modell veröffentlicht, das für Ihren spezifischen Anwendungsfall erheblich besser ist, zu niedrigeren Kosten pro Token. Oder ein Datenleck bei der Infrastruktur von OpenAI schafft einen 72-Stunden-Zeitraum, in dem Ihre AI-gestützten Operationen ausfallen.
Wie schnell können Sie wechseln? Wenn Sie diese Frage nicht durchdacht haben, sind Sie möglicherweise bereits eingesperrt.
Anbieter-Lock-in in herkömmlicher Software ist kostspielig, aber üblicherweise begrenzt. Sie können Ihre Daten aus Salesforce exportieren, auch wenn es Aufwand erfordert. Sie können von AWS (Amazon Web Services) migrieren, auch wenn es ein Jahr dauert. Die Wechselkosten sind groß, aber endlich. Gartner prognostiziert, dass bis 2027 35 % der Länder in regionsspezifische AI-Plattformen mit proprietären Kontextdaten eingesperrt sein werden, was signalisiert, dass AI-Plattform-Lock-in zu einem geopolitischen sowie kommerziellen Problem wird.
AI-Anbieter-Lock-in hat zusätzliche Dimensionen, die es schwieriger zu quantifizieren und teurer zu lösen machen. Ihre Prompt-Engineering-Arbeit ist modellspezifisch. Ihr Fine-Tuning ist modellspezifisch. Die Intuition Ihres Teams darüber, wie man mit dem AI arbeitet, ist modellspezifisch.
Dieser Artikel behandelt die drei Formen von AI-Anbieter-Lock-in, spezifische Minderungen für jede und die wichtige Realitätsprüfung: Ein Teil des Lock-ins ist akzeptabel, und das Ziel ist informierter Lock-in, kein Zero-Lock-in.
Warum Lock-in in AI sich von herkömmlicher Software unterscheidet
Key Facts: AI-Anbieter-Lock-in
- 94 % der Organisationen sind besorgt über AI-Anbieter-Lock-in, wobei 45 % sagen, es habe bereits ihre Fähigkeit beeinträchtigt, bessere Tools zu adoptieren. (Parallels 2026 Cloud Survey)
- Nur 6 % der Enterprise-Führungskräfte sagen, sie könnten ihren primären AI-Anbieter ohne Disruption wechseln, und 47 % sagen, eine wichtige Geschäftsfunktion würde aufhören, wenn ihr primärer Anbieter ausfiele. (Zapier)
- Unternehmen, die von Anfang an für Portabilität gebaut haben, stehen bei einem Anbieterwechsel vor 60-80 % niedrigeren Migrationskosten als jene, die ohne Abstraktionsschichten eng integriert haben. (Kellton)
In herkömmlicher Software ist Anbieter-Lock-in primär eine Frage der Datenportabilität und Integrationsarbeit.
In AI operiert Lock-in auf drei zusätzlichen Ebenen.
Modellverhalten ist nicht portabel. Wenn Sie Workflows aufgebaut haben, die auf dem spezifischen Verhalten von GPT-4o basieren (sein Ton, seine Formatierungspräferenzen, seine Fehlerbehandlung, seine Antwort auf spezifische Prompt-Muster), gibt Ihnen der Wechsel zu Claude 3.7 Sonnet nicht dasselbe Verhalten, auch wenn es technisch bessere Ergebnisse liefert.
Optimierungsarbeit ist modellspezifisch. Prompt Engineering ist kein übertragbares Artefakt. System-Prompts, die für GPT-4 optimiert wurden, performen auf Anthropic-Modellen oft erheblich schlechter ohne wesentliches Neu-Engineering. Fine-Tuning ist vollständig modellspezifisch.
Das Lernen ist nicht transferierbar. Wenn Sie sechs Monate damit verbracht haben zu lernen, wie sich ein spezifisches Modell in Randfällen verhält, migriert dieses Wissen nicht.
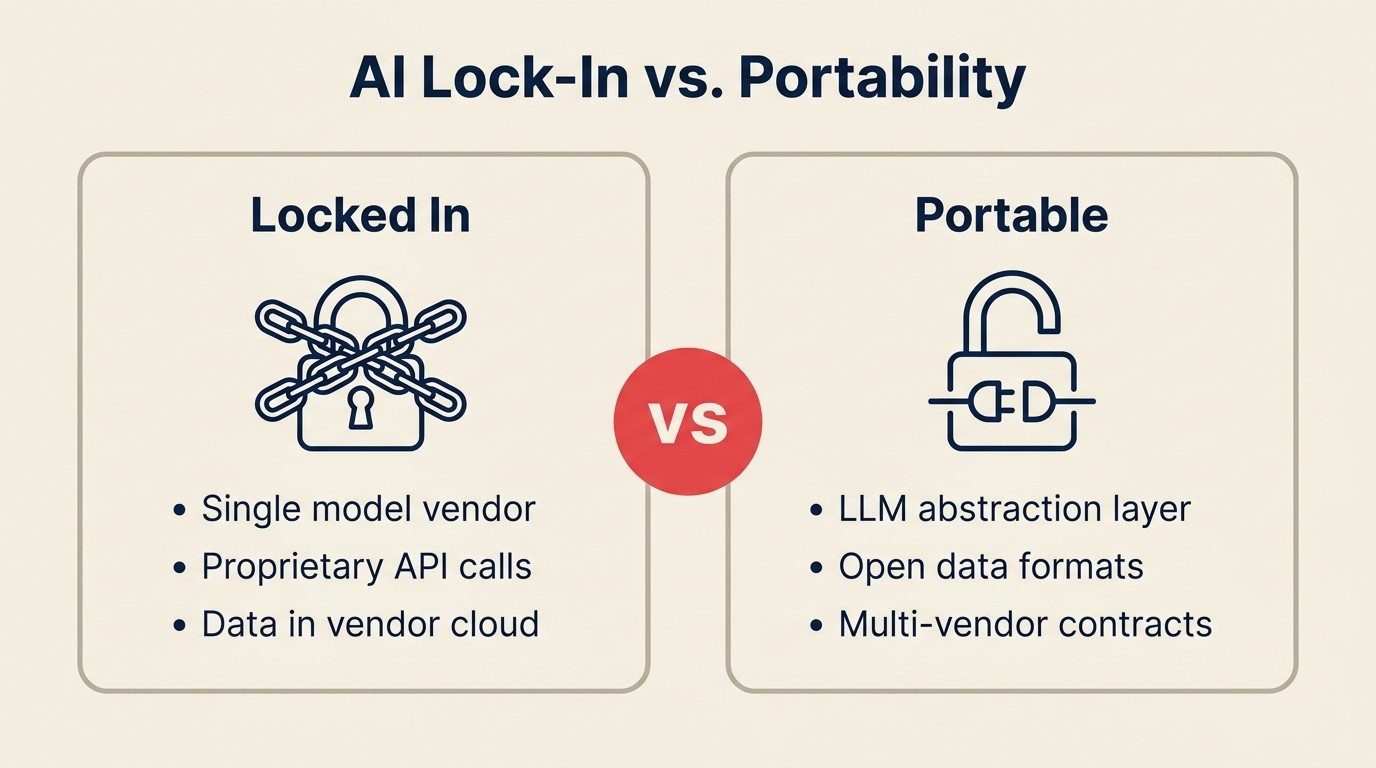
Die 3 Formen von AI-Anbieter-Lock-in

Modell-Lock-in
Modell-Lock-in tritt auf, wenn Ihre Anwendungslogik eng an das spezifische Verhalten des Modells eines Anbieters gekoppelt ist. Sie haben Prompts dafür optimiert, Ihre QA-Prozesse auf seine Ergebnisse kalibriert und Ihr Team versteht sein spezifisches Verhalten gut genug, um effektiv damit zu arbeiten.
Das Signal, dass Sie Modell-Lock-in haben: Wenn Sie gefragt werden "was würde ein Wechsel zu einem anderen Modell erfordern?", lautet die Antwort "mehrere Wochen Neu-Testen und Neu-Optimierung über alle unsere AI-Workflows." Das ist Modell-Lock-in.
Model-Deprecation ist der primäre Auslöser für Modell-Lock-in-Kosten. OpenAI hat den ursprünglichen GPT-3.5-Instruct-Endpunkt im Januar 2024 mit sechs Monaten Ankündigung eingestellt. Anthropic hat seinen Modell-Lineup ähnlich aktualisiert. Claude 1, Claude 2, Claude 2.1, Claude 3 Haiku, Sonnet und Opus, Claude 3.5 und Claude 4-Serien sind innerhalb von unter drei Jahren aufeinander gefolgt.
Modell-Lock-in-Minderung:
Die primäre architekturelle Minderung ist eine Abstraktionsschicht, die Ihre Anwendungslogik von der Modell-API trennt. Tools wie LiteLLM (eine Python-Bibliothek, die eine einheitliche Schnittstelle über OpenAI, Anthropic, Cohere und andere Anbieter bietet) oder LangChain (ein Anwendungsframework, das Modell-Calls abstrahiert) ermöglichen es Ihnen, das zugrunde liegende Modell durch Änderung eines Konfigurationsparameters zu wechseln, statt API-Integrationscode neu zu schreiben.
LiteLLM gibt Ihnen speziell ein einzelnes API-Call-Format, das zu welchem Modell auch immer Sie angeben weiterleitet. Ihr Anwendungscode ruft heute litellm.completion(model="gpt-4o", messages=...) auf. Wenn Sie zu claude-3-7-sonnet-20250219 wechseln wollen, ändern Sie den Modell-Parameter, nicht den umgebenden Code.
Multi-Modell-Testkadenz hilft ebenfalls. Wenn Sie Ihre wichtigsten Workflows regelmäßig vierteljährlich gegen 2 bis 3 Modelle benchmarken, werden Sie wissen, ob eine geeignete Alternative existiert.
Daten-Lock-in
Daten-Lock-in tritt auf, wenn Ihre AI-Trainingsdaten, Fine-Tuning-Datensätze oder Vektor-Embeddings im proprietären Format eines Anbieters gespeichert sind, was den Ausstieg teuer und komplex macht.
Daten-Lock-in-Minderung:
Vektor-Embeddings sind das primäre AI-spezifische Datengut, das es zu schützen gilt. Wenn Sie ein RAG (Retrieval-Augmented Generation)-System betreiben, repräsentieren Ihre Dokument-Embeddings erhebliche Investitionen. Speichern Sie diese in Open-Format-Vektordatenbanken (FAISS, Chroma, Weaviate, Qdrant) statt in Anbieter-proprietärem Embedding-Speicher. Alle unterstützen Standard-Exportformate.
Quelldokumente sind gleichermaßen wichtig. Speichern Sie Quelldokumente in Ihren eigenen Systemen (Ihrem eigenen S3-Bucket, Ihrem eigenen SharePoint-Tenant) statt im Speicher des Anbieters.
Fine-tuned Modell-Gewichte sind das schwierigste AI-Datengut zu verwalten. Verhandeln Sie in Enterprise-Vereinbarungen explizite Gewichts-Export-Rechte. Sie können diese Gewichte möglicherweise nicht immer anderswo ausführen, aber das Export-Recht bedeutet, dass Sie zumindest validieren können, was Sie verlieren, bevor Sie unterzeichnen.
Vertragsklauseln zur Daten-Lock-in-Minderung:
Jeder AI-Anbieter-Vertrag sollte enthalten:
- Explizite Aussage, dass Kundendaten ohne ausdrückliche Einwilligung nicht für Modelltraining verwendet werden
- Daten-Export-Rechte einschließlich Formatspezifikation und Antwortzeit-Verpflichtung
- Daten-Löschrechte mit Zertifizierung der Löschung innerhalb von 30 Tagen nach Vertragsbeendigung
- Portabilitätsgarantie: Daten werden in offenen, Standard-Formaten zurückgegeben, nicht in proprietären Formaten
Integration-Lock-in
Integration-Lock-in tritt auf, wenn Ihre Systeme sich tief mit dem spezifischen API-Design, den Antwortformaten und Integrationsmustern eines Anbieters verbinden. Benutzerdefinierter Code, der das SDK (Software Development Kit) eines Anbieters umschließt, interne Tools, die auf dem Agent-Framework eines Anbieters aufgebaut sind, und Workflow-Automatisierungen, die vom spezifischen Event-Format eines Anbieters abhängen, stellen alle Integration-Lock-in dar.
Integration-Lock-in-Minderung:
API-Abstraktion ist das primäre architekturelle Muster. Statt jedes interne System direkt die AI-Anbieter-API aufrufen zu lassen, routen Sie alle AI-Calls durch einen internen Service, den Sie kontrollieren. Wenn Sie Anbieter wechseln müssen, aktualisieren Sie den Abstraktions-Service, nicht jedes System, das AI verwendet.
Das gibt Ihnen auch Beobachtbarkeit, die direkte Integration nicht bietet. Jeder AI-Call in Ihrer Infrastruktur wird vom Abstraktions-Service protokolliert. Gartner warnt, dass Organisationen ohne sorgfältige Kostenarchitektur 500-1000 % Fehler in ihren GenAI-Kostenberchnungen machen könnten, wenn die Nutzung skaliert, was zentralisiertes Monitoring von Pro-Call-Kosten von Anfang an wesentlich macht.
Die 3-Lock-in-Typ-Karte
Die 3-Lock-in-Typ-Karte unterscheidet die drei Formen von AI-Anbieter-Lock-in, die jeweils unterschiedliche Minderungsstrategien erfordern: Modell-Lock-in (Anwendungslogik eng an das Modellverhalten, die Optimierungsarbeit und die Team-Intuitionen eines Anbieters gekoppelt), Daten-Lock-in (Trainingsdaten, Fine-Tuning-Datensätze oder Vektor-Embeddings in proprietären Formaten gespeichert) und Integration-Lock-in (interne Systeme direkt mit dem spezifischen API-Design, den Antwortformaten und den Event-Strukturen eines Anbieters verbunden). Die Minderung erfordert unterschiedliche architekturelle Eingriffe für jeden Typ, und das Adressieren nur eines Typs lässt Organisationen den anderen beiden gegenüber exponiert.
Quotable: "Unternehmen, die von Anfang an für Portabilität gebaut haben, stehen bei einem Anbieterwechsel vor 60-80 % niedrigeren Migrationskosten als jene, die ohne Abstraktionsschichten eng integriert haben. Die Portabilitätsinvestitionskosten sind gering; die Migrationskosten ohne sie sind groß." (Kellton)
Quotable: "Informierter Lock-in sieht so aus: 'Wir haben GPT-4o Vision gewählt, weil es das am besten performende Modell für unseren Anwendungsfall ist, und wir haben einen 6-Monats-Wechsel-zu-Alternative-Plan überprüft und sind bereit, ihn auszuführen.' Versehentlicher Lock-in sieht so aus: 'Wir haben dieses Modell seit zwei Jahren verwendet und haben nie bewertet, ob wir wechseln könnten.'"
Quotable: "Gartner prognostiziert, dass bis 2027 35 % der Länder in regionsspezifische AI-Plattformen mit proprietären Kontextdaten eingesperrt sein werden, was signalisiert, dass AI-Plattform-Lock-in zu einem geopolitischen Problem sowie zu einem kommerziellen wird." (Gartner)
| Lock-in-Typ | Primäres Signal | Architekturelle Minderung | Vertragsminderung |
|---|---|---|---|
| Modell-Lock-in | "Wechseln würde Wochen Neu-Testen erfordern" | LiteLLM oder LangChain Abstraktionsschicht; vierteljährliches Multi-Modell-Benchmarking | Modellversions-Pinning-Rechte; Deprecation-Ankündigungsverpflichtung |
| Daten-Lock-in | Embeddings und Fine-Tuning-Gewichte im Anbieter-Speicher | Open-Format-Vektordatenbanken (FAISS, Chroma, Qdrant); Quelldokumente im eigenen Speicher | Daten-Export-Rechte mit Formatspezifikation; Löschzertifizierung innerhalb von 30 Tagen |
| Integration-Lock-in | "Wir müssten 15-20 benutzerdefinierte Integrationen neu schreiben" | Interner AI-Abstraktions-Service, den alle Systeme aufrufen; zentralisiertes Logging | SLA-Migrationsunterstützungsverpflichtung; 90-Tage-Support bei Vertragsbeendigung |
Rework-Analyse: Basierend auf Enterprise-AI-Infrastrukturmustern ist die gefährlichste Form von Lock-in Integration-Lock-in, weil er am wenigsten sichtbar ist, bis eine Migration im Gange ist. Modell-Lock-in ist sichtbar (Re-Test-Kosten sind schätzbar). Daten-Lock-in ist teilweise sichtbar (Sie können aufzählen, was wo gespeichert ist). Integration-Lock-in wird erst sichtbar, wenn Sie den benutzerdefinierten Code zählen, der das SDK eines Anbieters über jedes interne System umschließt.
Die Realitätsprüfung: Informierter Lock-in ist akzeptabel

Lock-in vollständig zu eliminieren ist kein realistisches Ziel, und es aggressiv zu verfolgen hat seine eigenen Kosten. Übermäßiges Engineering für Anbieter-Neutralität erhöht die Implementierungskomplexität, reduziert die Performance (Abstraktionsschichten fügen Latenz hinzu) und verhindert oft die Nutzung modellspezifischer Funktionen, die Ihren Anwendungsfall erheblich verbessern würden.
Informierter Lock-in sieht so aus: "Wir haben beschlossen, eng auf den Vision-Fähigkeiten von GPT-4o zu integrieren, weil es das am besten performende Modell für unseren Rechnungsverarbeitungsanwendungsfall ist, und die Wechselkosten sind angesichts der Performance-Prämie akzeptabel. Wir haben diese Entscheidung dokumentiert und haben einen 6-Monats-Wechsel-zu-Alternative-Plan, den wir überprüft haben und der ausführbar ist."
Versehentlicher Lock-in sieht so aus: "Wir haben GPT-4 seit zwei Jahren verwendet und haben nie bewertet, ob wir wechseln könnten. OpenAI hat gerade die Preise geändert und wir versuchen herauszufinden, wie tief wir eingesperrt sind."
Modell-Deprecation-Planung
Die Modell-Deprecation-Geschichte von Frontier-AI-Anbietern gibt Ihnen einen realistischen Planungshorizont dafür, wie lange ein bestimmtes Modell verfügbar sein wird.
Die praktische Planungsimplikation: Bauen Sie Ihre AI-Infrastruktur in der Annahme auf, dass jede spezifische Modellversion innerhalb von 12 bis 18 Monaten eingestellt wird. Das bedeutet:
- Keine Anheftung an spezifische Modellversions-Strings im Produktionscode ohne geplanten Review-Zyklus
- Einbauen von Neu-Validierungskapazität in die vierteljährliche Arbeit Ihres AI-Teams (nehmen Sie 1 bis 2 wichtige Modell-Tests pro Jahr an)
- Budgetierung für Neu-Optimierungsarbeit jedes Jahr, statt die aktuelle Modell-Performance als permanent zu betrachten
Lock-in ist nicht der Feind. Überraschung ist der Feind. Die Organisationen, die AI-Anbieter-Beziehungen am besten managen, sind jene, die ihre Exposition verstanden haben, bevor sie zu einem Problem wurde.

Co-Founder, Rework.com