Vom Support-Ticket zum Backlog-Eintrag: Die operative Pipeline, die CS-Teams brauchen
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Zwei Teams lösen dasselbe Problem. Support-Mitarbeitende beantworten jede Woche dieselbe Frage zum Massen-Export-Workflow. Sie haben ein Skript dafür entwickelt, es der FAQ hinzugefügt und bearbeiten es in unter vier Minuten. Auf der anderen Seite des Gebäudes entscheidet das Product-Team, ob es in diesem Quartal Entwicklungszeit in Export-Funktionalität investieren soll.
Sie haben nie miteinander gesprochen.
Das ist kein Kommunikationsfehler. Es ist ein Pipeline-Fehler. Support hat das Signal: Häufigkeit, verbatim verwendete Sprache, Kontoverteilung. Product hat die Entscheidungshoheit. Aber zwischen den beiden liegt eine unstrukturierte Lücke, in der Signale als geschlossene Tickets sterben und Produktentscheidungen auf Basis von Bauchgefühl und der Anwesenheit bei Roadmap-Meetings getroffen werden.
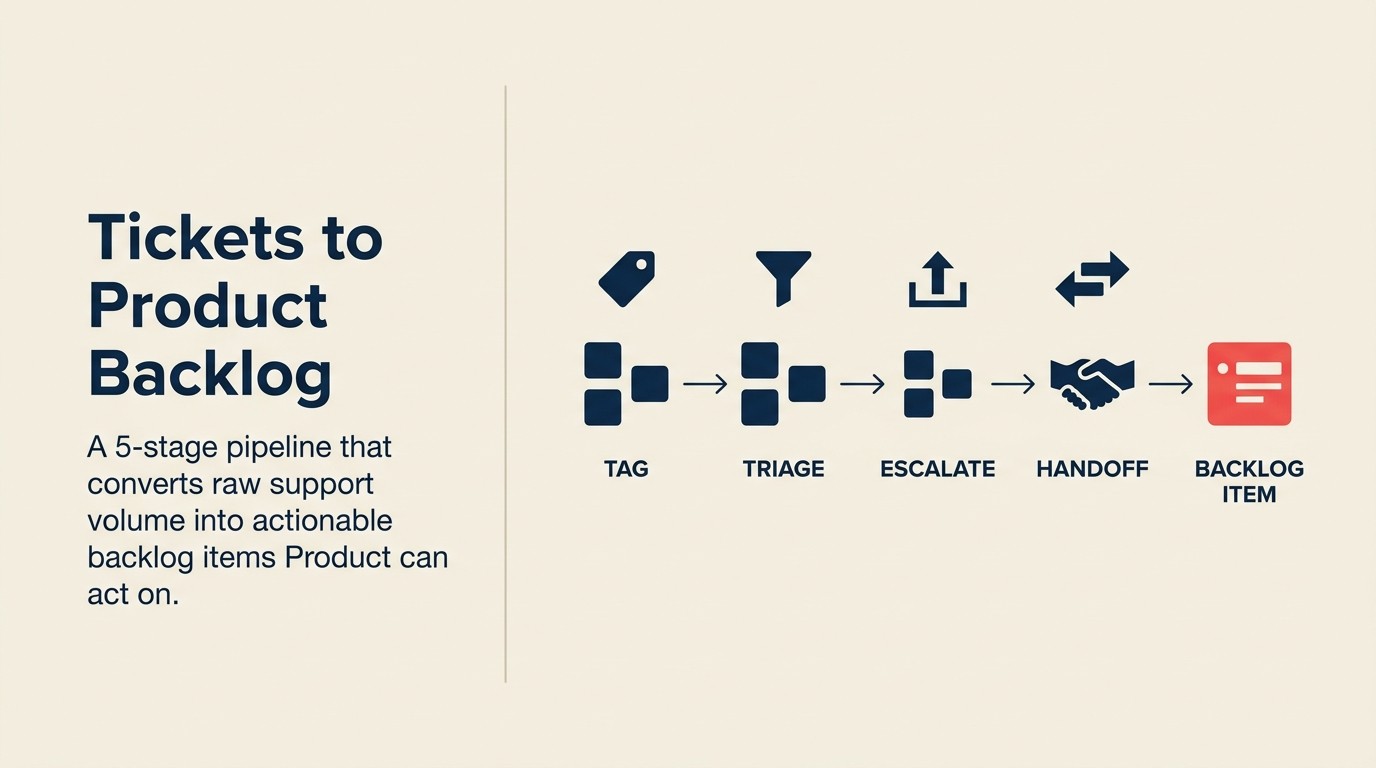
Die Lösung ist keine wöchentliche Versammlung. Es ist eine operative Pipeline mit fünf definierten Stufen und klaren Verantwortlichen an jedem Übergabepunkt. Das CS-Product Alignment Glossar definiert, was „Eskalation", „Backlog-Eintrag" und „Schließen der Feedback-Schleife" präzise bedeuten. Das ist wichtig, wenn Support, CS und Product diese Begriffe jeweils unterschiedlich verwenden.
Die 5-stufige Support-to-Backlog-Pipeline strukturiert diesen Weg: Tagging bei Eingang → Triage-Gate → CS-Brücke → Backlog-Übergabe → Schließen der Feedback-Schleife. Jede Stufe hat einen definierten Verantwortlichen, ein zeitgebundenes SLA und einen spezifischen Output, von dem die nächste Stufe abhängt. Überspringt man eine Stufe, verschlechtert sich das Signal oder verschwindet vollständig.
Warum Support-Tickets das am meisten unterschätzte Produktsignal sind
Support-Tickets haben drei Eigenschaften, die kein anderer Feedback-Kanal übertrifft: Volumen, Häufigkeit und verbatim verwendete Kundensprache.
Ein Customer Advisory Board gibt Ihnen Tiefe. Ein QBR gibt Ihnen strategischen Kontext. Aber Support-Tickets geben Ihnen, was Kunden tatsächlich sagen, wenn sie frustriert sind und keine Rolle spielen. Die Sprache, die ein Kunde verwendet, um einen Fehler oder eine Workaround-Anfrage zu beschreiben, ist oft diagnostisch wertvoller als alles, was er in einem strukturierten Interview sagen würde.
Aber keines dieser Signale lebt in einem Roadmap-Planungs-Tool. Es lebt in Zendesk, Intercom oder Freshdesk, nach der Lösung geschlossen und archiviert, für das PM-Team, das den Sprint des nächsten Quartals plant, unsichtbar. McKinseys Forschung zu Customer Success Operations bestätigt, dass Produkterfahrung einer der zwei wichtigsten Treiber von Customer Success-Ergebnissen ist. Trotzdem haben weniger als 10 % der Unternehmen Product Managern eine formelle Verantwortung für das Handeln auf support-basierte Signale zugewiesen.
Die folgende Pipeline verbindet diese zwei Welten. Sie erfordert keine neuen Tools. Sie erfordert neue Gewohnheiten an fünf definierten Punkten.
Key Facts: Die Signal-Lücke zwischen Support und Product
- Nur 23 % der Kundensupport-Tickets, die Produktfeedback enthalten, werden formal an Product-Teams eskaliert (Zendesk Customer Experience Trends Report). Die verbleibenden 77 % werden gelöst und archiviert, ohne den Backlog zu erreichen.
- Unternehmen mit einer formellen Support-to-Product-Feedback-Pipeline lösen wiederkehrende Probleme auf Produktebene 40 % schneller als solche ohne eine solche Pipeline (Gainsight, 2024).
- 61 % der CS-Führungskräfte berichten, dass ihr Support-Team und ihr Product-Team unterschiedliche Sprache verwenden, um dieselben Kundenprobleme zu beschreiben, was die Ticket-Analyse ohne eine gemeinsame Taxonomie unzuverlässig macht (Customer Success Collective, 2024).
Stufe 1: Tagging bei Eingang
Die Taxonomie ist das Fundament. Ohne sie passiert in jeder nachgelagerten Stufe entweder nichts oder sie erzeugt Rauschen.
Die vier Ticket-Kategorien:
- Fehler (Bug): Das Produkt verhält sich nicht wie dokumentiert. Erwartetes Verhalten existiert und ist falsch. Weiterleitung: Engineering-Triage.
- Workaround-Anfrage: Der Kunde tut etwas manuell, das automatisiert sein sollte. Das Produkt funktioniert wie vorgesehen, aber das Design erzeugt Reibung. Weiterleitung: CS-Plattform-Team oder PM, abhängig von Schweregrad und Häufigkeit.
- Funktionslücke (Feature Gap): Der Kunde benötigt Funktionalität, die nicht existiert und mit bestehenden Funktionen nicht angenähert werden kann. Weiterleitung: CS-PM-Eskalationspfad.
- Schulungsproblem: Das Produkt kann bereits tun, was der Kunde fragt. Die Lücke liegt in der Dokumentation oder im Onboarding, nicht im Produkt. Weiterleitung: CS Enablement, nicht PM.
Die Unterscheidung zwischen Schulungsproblem und Funktionslücke ist diejenige, die Support-Mitarbeitende am häufigsten falsch einschätzen. Ein Ticket, das wie „wir können keine Massenexporte durchführen" aussieht, ist manchmal „wir können nicht herausfinden, wie man Massenexporte durchführt." Hier falsch zu liegen bedeutet, dass PM-Posteingänge mit Schulungsanfragen gefüllt werden, die zum Wissensbasis-Team hätten gehen sollen.
Tag-Struktur: [Produktbereich] + [Ticket-Kategorie] + [Kontostufe]
Beispiel: CRM > Funktionslücke > Enterprise
Diese Tag-Struktur macht das Ticket über drei Dimensionen abfragbar. Sie können in unter 30 Sekunden fragen „wie viele Enterprise-Funktionslücken-Tickets haben diesen Monat das CRM-Modul betroffen?"
Was passiert, wenn Tickets ungetaggt bleiben: Das Signal verschwindet. Ungetaggte Tickets sind einzeln suchbar, aber kollektiv unsichtbar. Keine Aggregation ist möglich. Der Mustererkennnungsschritt findet nie statt. PMs treffen Entscheidungen basierend auf den lautesten Stimmen, nicht auf den häufigsten Mustern. Sobald das Tagging konsistent ist, stellt sich die nächste Frage, welche getaggten Tickets tatsächlich die Support-Queue verlassen.
Tool-agnostischer Hinweis: Diese Taxonomie funktioniert in Zendesk, Intercom, Freshdesk und jedem anderen Support-Tool, das benutzerdefinierte Tags oder Felder unterstützt. Die spezifische Implementierung variiert; die Taxonomiestruktur nicht. Der aufeinander abgestimmte CS- und CRM-Plattform-Stack deckt ab, wie Ihre vorgelagerten Tools (das CRM und die CS-Plattform) verknüpft sein müssen, bevor Ticket-Level-Tagging ohne manuellen Neu-Eintrag sauber in den Produkt-Backlog fließen kann.
Stufe 2: Triage-Gate: Support-Problem oder Produktproblem?
Nicht jedes getaggte Ticket muss weiterreisen. Das Triage-Gate entscheidet, welche Tickets das Support-System verlassen und welche dort abgeschlossen werden.
Entscheidungskriterien:
Kann dies mit bestehender Produktfunktionalität gelöst werden? Wenn ja, bleibt es im Support. Wenn nein, oder wenn die Antwort einen Workaround erfordert, der nicht notwendig sein sollte, geht es zum Produkt-Eskalationspfad über.
Wer die Entscheidung trifft:
Für Fehler- und Funktionslücken-Tickets trifft der Support-Team-Lead die erste Entscheidung. Für alle Tickets, bei denen die Entscheidung unklar ist, ist CSM-Validierung der nächste Schritt (Stufe 3). Weisen Sie uneindeutige Tickets nicht direkt an den PM weiter. Das erzeugt den „lautes Rauschen"-Fehlermodus, bei dem PM-Posteingänge mit halb triagieren Problemen gefüllt werden.
Eskalations-SLA:
Mit dem Produkt-Flag versehene Tickets sollten innerhalb von 48 Stunden nach dem Tagging vom CS-Team geprüft werden. Wenn ein Ticket länger als 48 Stunden als Produktproblem getaggt ohne CSM-Prüfung sitzt, ist es praktisch verloren. Der Kundenkontext ist veraltet, und der Support-Mitarbeitende kann keine weiteren Details hinzufügen, ohne den Kunden erneut zu kontaktieren.
Triage-Fehlermuster:
Über-Eskalation: Support markiert alles für Product, weil „auf Nummer sicher gehen besser ist." Der PM-Posteingang überflutet. PMs beginnen, den Eskalationskanal zu ignorieren. Echte Signale werden im Rauschen vergraben.
Unter-Eskalation: Support löst alles lokal, weil „das ist unsere Aufgabe." Bekannte Fehler bleiben monatelang verborgen. Funktionslücken tauchen nie auf. PMs glauben, das Produkt funktioniere besser als es tatsächlich tut.
Das Triage-Gate funktioniert nur, wenn Support-Leads in den Entscheidungskriterien geschult und für das 48-Stunden-SLA verantwortlich gemacht werden. Keines davon passiert automatisch.
Stufe 3: Eskalation an CS: Der Brücken-Schritt
Wenn Support ein Ticket als Produktproblem markiert, ist CS die Brücke zwischen der kundenseitigen Realität und dem Arbeitsvokabualar des Product-Teams.
Was der CSM tut:
Zuerst validieren, ob das Problem konto-spezifisch oder kontoübergreifend ist. Ein konto-spezifisches Problem könnte ein Konfigurationsproblem oder eine Schulungslücke sein, die sich als Funktionsanfrage tarnt. Ein kontoübergreifendes Problem ist ein Produktsignal. Der CSM hat den Kontokontext, um den Unterschied zu erkennen.
Zweitens das Ticket mit den Informationen anreichern, die PMs tatsächlich benötigen: der ARR der betroffenen Konten, das Verlängerungsdatum des höchst-gefährdeten Kontos, das das Problem meldet, der Health Score jedes Kontos und jeder strategische Wichtigkeitskontext (benannte Konten, laufende Ausweitung-Gespräche).
Drittens das Bridge-Ticket erstellen: die formatierte Eskalation, die das PM-Team erhält. Das ist kein weitergeleitetes Support-Ticket, sondern ein synthetisiertes Produktsignal.
Bridge-Ticket-Format:
Zusammenfassung des Problems: [1-2 Sätze in einfacher Sprache]
Produktbereich: [aus der Tag-Taxonomie]
Ticket-Kategorie: [Fehler / Workaround-Anfrage / Funktionslücke]
Betroffene Konten: [Auflistung nach Name]
Gesamt betroffener ARR: $[X]
Höchst-gefährdetes Konto: [Name, ARR, Verlängerungsdatum, Health Score]
Häufigkeit: [N eindeutige Konten, N Gesamt-Tickets in den letzten 90 Tagen]
Verbatim Kundensprache: "[Zitat aus dem Ticket: dies ist Gold für UX]"
Reproduktionsschritte (nur für Fehler): [nummerierte Schritte]
Erwartetes vs. tatsächliches Verhalten (nur für Fehler): [klare Beschreibung]
CSM-Prioritätseinstufung: P1 / P2 / P3 [mit kurzer Begründung]
Dieses Format erhält PM-Aufmerksamkeit, weil es die Fragen beantwortet, die PMs stellen, bevor sie irgendetwas triagieren: wie viele Kunden, wie viel ARR, wie reproduzierbar, wie dringend.
Stufe 4: Produkt-Backlog-Übergabe
Das Bridge-Ticket bringt den PM dazu hinzuzuschauen. Das Backlog-Übergabeformat entscheidet, ob der PM handelt.
Wie ein gut geformter Backlog-Eintrag aussieht:
Titel: [Massenexport: Kunden können nicht mehr als 500 Zeilen ohne Datenschnitt exportieren]
Kunden-Impact-Statement: 14 Konten (gesamt ARR $1,2 M) haben dies in den letzten 90 Tagen gemeldet.
Drei Konten haben es als Verlängerungsrisiko markiert. Zwei befinden sich in aktiven Ausweitung-
Gesprächen, bei denen diese Einschränkung ein Hindernis darstellt.
Reproduktionsschritte: [nummeriert, von Support verifiziert]
Erwartetes Verhalten: Benutzer kann den vollständigen Datensatz unabhängig von der Zeilenanzahl exportieren
Tatsächliches Verhalten: Export bricht bei 500 Zeilen ohne Fehlermeldung ab
Verbatim Kundensprache: „Wir müssen vier Exporte ausführen und sie in Excel zusammensetzen.
Das ist vor dem Team peinlich."
Betroffener ARR: $1,2 M über 14 Konten
Abwanderungsrisiko-Konten: 3 (von CSMs als gefährdet markiert)
Häufigkeit: 22 Tickets in den letzten 90 Tagen, 14 eindeutige Konten
Prioritätsempfehlung: P2 (erheblicher ARR-Impact, kein aktueller Workaround ohne Datenmanipulation)
Wie ein schlecht geformter Backlog-Eintrag aussieht:
Titel: [Massenexport-Problem]
Beschreibung: Mehrere Kunden haben sich über den Export beschwert. Können wir das beheben?
Die schlecht geformte Version wird nicht priorisiert, nicht weil PMs nicht reagieren, sondern weil sie sie nicht bewerten können. Kein ARR-Impact, keine Reproduktionsschritte, keine Häufigkeitsdaten, keine Kundensprache. Jeder PM im Team schaut auf 30 Einträge, die so aussehen. Sie priorisieren die, die sie verstehen.
Wer die Übergabe verantwortet:
In Teams mit weniger als 10 CSMs verantwortet der CSM, der das Ticket eskaliert hat, die Übergabe. In größeren Teams verantwortet CS Ops oder ein designierter Produkt-Liaison-CSM die Synthese und Übergabe für alle kontoübergreifenden Probleme.
Backlog-Pflege:
Unterscheiden Sie drei Zustände: geschlossene Tickets (im Support gelöst, keine weiteren Maßnahmen), offene Feedback-Einträge (von PM anerkannt, in Bewertung) und akzeptierte Backlog-Einträge (in einem Sprint oder Roadmap-Quartal zugesagt). Wenn Sie diese Unterscheidungen nicht aufrechterhalten, wird „an Product übermittelt" bedeutungslos. Alles Eingereichte sieht genauso aus wie alles Bearbeitete.
Stufe 5: Schließen der Feedback-Schleife zu Support und Kunden
Dies ist der Schritt, den die meisten Teams überspringen. Es ist auch der Schritt, der bestimmt, ob die Pipeline in sechs Monaten noch funktioniert.
Support benachrichtigen, wenn ein Ticket ein Backlog-Eintrag wird:
Der Support-Mitarbeitende, der das ursprüngliche Ticket bearbeitet hat, sollte wissen, dass seine Eskalation wichtig war. Nicht als Motivationsübung, sondern als operatives Signal. Wenn Support-Mitarbeitende nie hören, was mit den Tickets passiert, die sie markieren, hören sie auf zu markieren. Die Pipeline verschlechtert sich durch Nichtgebrauch.
Eine einfache Slack-Nachricht oder ein Ticket-Kommentar reicht: „Das Massenexport-Problem, das Sie eskaliert haben (Ticket #12847), wurde als Backlog-Eintrag protokolliert. Aktuelle Priorität: P2. Erwartete Prüfung im nächsten Sprint-Planning."
Den Kunden benachrichtigen, wenn ihr Ticket eine Produktentscheidung beeinflusst hat:
Hier zögern die meisten Teams, weil sie sich zu keinem Zeitplan verpflichten wollen. Aber es gibt Formulierungen, die die Feedback-Schleife schließen, ohne Versprechen zu machen. Kundenschulungsinhalte behandelt, wie man aus diesen Updates proaktive Dokumentation macht, sodass der nächste Kunde, der dasselbe Problem hat, einen Hilfeartikel findet, bevor er ein Ticket öffnet.
„Wir möchten Sie darüber informieren, dass das Problem, das Sie im [Monat] gemeldet haben, als Produkt-Backlog-Eintrag protokolliert wurde. Wir können uns zu keinem konkreten Zeitplan verpflichten, aber Ihr Bericht hat dazu beigetragen, dass das Team dies priorisiert. Wir melden uns, wenn es eine Statusaktualisierung gibt."
Was nicht gesagt werden sollte: „Wir beheben das in Q3." Das ist ein Versprechen. Die Nachricht zur Schließung der Feedback-Schleife ist eine Benachrichtigung, keine Verbindlichkeit.
HBRs Framework zum Einbetten von Feedback-Schleifen in Produkte empfiehlt, das Schließen der Feedback-Schleife als Produktfunktion statt als Prozessschritt zu behandeln. Kunden, die nach einem gemeldeten Problem eine Rückmeldung erhalten, sind wesentlich wahrscheinlicher, das nächste Signal zu melden.
Was zu sagen ist, wenn das Ticket NICHT bearbeitet wird:
„Wir haben das von Ihnen gemeldete Problem geprüft. Basierend auf aktuellen Prioritäten und der Anzahl betroffener Konten hat es es nicht in den aktiven Backlog geschafft. Wir behalten es in den Unterlagen und werden es im nächsten Planungszyklus neu bewerten. Vielen Dank für die Details. Sie helfen, auch wenn die unmittelbare Antwort nein ist."
Das ist die schwerste Nachricht zu senden. Sie ist auch diejenige, die langfristig das meiste Vertrauen aufbaut.
Metriken zur Messung der Pipeline-Gesundheit
Gartners Stimme-des-Kunden-Leitfaden stellt fest, dass VoC-Erkenntnisse aus Service-Interaktionen eines der am wenigsten genutzten strategischen Assets in den meisten Organisationen sind. Teams erfassen sie, erstellen aber selten einen kontinuierlichen Prozess, um auf Produktebene darauf zu handeln.
| Metrik | Zielwert | Was eine Abweichung signalisiert |
|---|---|---|
| % der Support-Tickets, die beim Eingang getaggt werden | 90 %+ | Schulungslücke in der Taxonomie oder Tool-Konfigurationsproblem |
| % der Produktflag-Tickets, die innerhalb des 48-Stunden-SLA geprüft werden | 85 %+ | CSM-Kapazitätsproblem oder Breakdown des Eskalationskanals |
| Ticket-to-Backlog-Konversionsrate | 25 bis 40 % | Entweder Über-Eskalation (zu viele Tickets erreichen PM) oder mangelnde Aktion (PM triagiert nicht) |
| Kunden-Benachrichtigungsrate, wenn Tickets bearbeitet werden | 100 % | Schritt zum Schließen der Feedback-Schleife wird übersprungen |
| Mediane Zeit vom ersten Ticket bis zur PM-Triage | <10 Werktage | Triage-Engpass, meist in Stufe 2 oder Stufe 3 |
Monatlich verfolgen. Wenn die Tagging-Rate unter 80 % fällt, produziert der Rest der Pipeline unzuverlässige Daten, unabhängig davon, wie gut die anderen Stufen funktionieren.
Häufige Fehlermuster
Das schwarze Loch: Tickets werden getaggt und eskaliert. Nichts kommt zurück. CSMs hören auf zu eskalieren, weil es keinen Beweis gibt, dass es wichtig ist. Die Pipeline leert sich von oben.
Lösung: Ein verbindliches PM-Anerkennungs-SLA einrichten. Innerhalb von fünf Werktagen nach Eingang eines Bridge-Tickets bestätigt PM den Empfang und gibt eine vorläufige Prioritätsbewertung. Sogar „priorisieren wir dieses Quartal nicht" schließt die Feedback-Schleife. CS Troubleshooting Call Best Practices behandelt, wie CSMs den Anrufmoment strukturieren können, wenn eine bekannte Produktlücke auftaucht, und Zeit kaufen, ohne Versprechen zu machen, während der Backlog-Eintrag geprüft wird.
Das laute Rauschen: Über-Eskalation überschwemmt den PM-Posteingang. PMs entwickeln einen mentalen Filter, der alles von CS deprioritiert, weil das Signal-Rauschen-Verhältnis zu gering ist.
Lösung: Stufe-2-Kriterien verschärfen. Nur kontoübergreifende Probleme mit ARR-Impact über einem definierten Schwellenwert eskalieren zu PM. Einzelkonto-Probleme werden in Stufe 3 gelöst, es sei denn, sie erfüllen spezifische strategische Kontokriterien.
Versprechen-Schleichen: Ein Support-Mitarbeitender oder CSM sagt einem Kunden „Ich stelle sicher, dass Product davon erfährt" auf eine Weise, die der Kunde als Verbindlichkeit interpretiert. Es werden Erwartungen gesetzt, die die Pipeline nicht erfüllen kann.
Lösung: Support und CS in der genauen Formulierung für jede Stufe schulen: Was „ich eskaliere das" bedeutet (es geht in die Pipeline, keine direkte PM-Aktion), was „es wurde protokolliert" bedeutet (es existiert im Backlog, nicht dass es geliefert wird) und was „wir halten Sie auf dem Laufenden" bedeutet (Sie hören von CS, wenn sich der Status ändert, nicht täglich).
Wie das mit Mustererkennung zusammenhängt
Die Support-Ticket-Pipeline erfasst einzelne Signale. Mustererkennung über CSMs hinweg ist das, was passiert, wenn man diese Signale über das gesamte Kontoergebnis-Portfolio aggregiert und nach Themen sucht, die kein einzelnes Ticket offenbart. Die beiden Prozesse sind sequenziell: Einzelne Tickets müssen getaggt und strukturiert werden (diese Pipeline), bevor kontoübergreifende Muster erkannt werden können. Und sobald Muster auftauchen, ist Customer-Impact Scoring das, was Product die ARR-gewichtete, abwanderungsrisiko-angepasste Sicht gibt, die ein Muster in eine vertretbare Prioritätsempfehlung verwandelt.
Die VoC-Pipeline von CS zu Product bietet den breiteren Kontext dafür, wie die Support-Ticket-Eskalation in das gesamte Spektrum der Stimme-des-Kunden-Kanäle passt. Feedback systematisch erfassen: Von CSM-Notizen zum Backlog deckt den parallelen Kanal ab, in dem Feedback in CSM-Gesprächen statt in Support-Interaktionen entsteht. Und CS-Plattform-zu-Produkt-Backlog-Integration deckt die Tooling-Ebene ab, die die hier beschriebenen Übergabeschritte automatisiert.
Rework-Analyse: Unternehmen, die die 5-stufige Support-to-Backlog-Pipeline mit allen Stufen besetzt und SLA-gesteuert betreiben, erreichen eine Ticket-to-Backlog-Konversionsrate von 25 bis 40 %, verglichen mit unter 5 % in Organisationen ohne formale Pipeline. Die Investition mit dem höchsten Hebel ist Stufe 1 (Taxonomie), weil sie bestimmt, ob jede nachgelagerte Stufe funktionieren kann. Teams, die das Taxonomiedesign überspringen und direkt zu Eskalationspfaden übergehen, stellen fest, dass PM-Posteingänge sich innerhalb von 60 Tagen mit unlabelierten Rauschen füllen, und der Eskalationskanal wird informell aufgegeben. Unsere Framework-Empfehlung: Zuerst die vier-Kategorien-Taxonomie aufbauen, sie einen Monat lang pilotieren, bevor das Triage-Gate aktiviert wird, und PM-Posteingänge erst verbinden, wenn die Tagging-Rate konstant 80 % übersteigt.
Mehr erfahren
- Mustererkennung über CSMs: Das systemische Problem
- Die VoC-Pipeline: Wie CS Product versorgt
- Feedback systematisch erfassen: CSM-Notizen zum Backlog
- Schließen der Feedback-Schleife mit Kunden
- CS-Plattform-zu-Produkt-Backlog-Integration
Häufig gestellte Fragen
Was ist die 5-stufige Support-to-Backlog-Pipeline?
Die 5-stufige Support-to-Backlog-Pipeline ist ein strukturierter operativer Prozess, der Kundensupport-Tickets von der rohen Beschwerde zum verwertbaren Produkt-Backlog-Eintrag bewegt. Die fünf Stufen sind: Tagging bei Eingang (taxonomiebasierte Klassifizierung), Triage-Gate (Entscheidung Support-Problem vs. Produktproblem), CS-Brücke (CSM-Anreicherung und Eskalation), Backlog-Übergabe (strukturiertes PM-fähiges Format) und Schließen der Feedback-Schleife (Benachrichtigung zurück an Support-Mitarbeitende und Kunden). Jede Stufe hat einen definierten Verantwortlichen und ein zeitgebundenes SLA.
Warum erreichen nur 23 % der Support-Tickets mit Produktfeedback das Product-Team?
Die meisten Organisationen haben keinen formalen Eskalationspfad, der Support und Product verbindet. Laut Zendesks Customer Experience Trends Report werden 77 % der Tickets mit Produktfeedback gelöst und archiviert, ohne den Backlog zu erreichen. Nicht weil das Feedback nicht wertvoll ist, sondern weil Support-Mitarbeitende keinen strukturierten Mechanismus haben, um es weiterzuleiten. Die drei fehlenden Elemente sind eine gemeinsame Taxonomie (damit Tickets klassifizierbar sind), ein Triage-Gate mit klaren Entscheidungskriterien und ein Bridge-Format, das Ticket-Sprache in PM-fähige Daten übersetzt.
Was ist ein Bridge-Ticket und was sollte es enthalten?
Ein Bridge-Ticket ist die formatierte Eskalation, die ein CSM erstellt, wenn ein Support-Problem als Signal auf Produktebene bestätigt wird. Es ist kein weitergeleitetes Support-Ticket. Es ist ein synthetisiertes Dokument, das enthält: Zusammenfassung des Problems in einfacher Sprache, Produktbereich und Ticket-Kategorie, betroffene Kontonamen und gesamt ARR, höchst-gefährdetes Konto mit Verlängerungsdatum und Health Score, Häufigkeitsdaten (eindeutige Konten und Gesamt-Tickets in 90 Tagen), verbatim Kundensprache, Reproduktionsschritte für Fehler und eine CSM-Prioritätseinstufung mit Begründung. Dieses Format erhält PM-Aufmerksamkeit, weil es die vier Fragen beantwortet, die PMs vor der Triage stellen: wie viele Kunden, wie viel ARR, wie reproduzierbar und wie dringend.
Wie sieht ein gut geformter Backlog-Eintrag im Vergleich zu einem schlecht geformten aus?
Ein gut geformter Backlog-Eintrag hat einen spezifischen Titel (z. B. „Massenexport: Kunden können nicht mehr als 500 Zeilen ohne Datenschnitt exportieren"), ein Kunden-Impact-Statement mit ARR und benannten Abwanderungsrisiko-Konten, von Support verifizierte Reproduktionsschritte, erwartetes vs. tatsächliches Verhalten, verbatim Kundensprache, Häufigkeitsdaten über eindeutige Konten und eine Prioritätsempfehlung mit Begründung. Ein schlecht geformter Eintrag sagt „Massenexport-Problem: mehrere Kunden beschwert sich, können wir das beheben?" Die schlecht geformte Version wird deprioritiert, nicht weil PMs nicht reagieren, sondern weil sie sie nicht gegen die 30 anderen Einträge vor ihnen bewerten können.
Was ist das Triage-Gate und wer verantwortet es?
Das Triage-Gate ist Stufe 2 der 5-stufigen Support-to-Backlog-Pipeline. Es ist der Entscheidungspunkt, an dem ein Support-Team-Lead bestimmt, ob ein getaggtes Ticket ein Support-Problem (kann mit bestehender Produktfunktionalität gelöst werden) oder ein Produktproblem ist (erfordert einen Workaround, der nicht notwendig sein sollte, oder Funktionalität, die nicht existiert). Für Fehler- und Funktionslücken-Tickets mit uneindeutiger Klassifizierung geht das Ticket zur CSM-Validierung, nicht direkt zum PM. Das 48-Stunden-SLA für die CSM-Prüfung ist der Durchsetzungsmechanismus des Gates. Tickets, die länger als 48 Stunden als Produktprobleme getaggt sitzen, verlieren Kundenkontext und werden faktisch zu geschlossenen Signalen.
Wie schließt man die Feedback-Schleife, ohne Verbindlichkeiten einzugehen?
Die empfohlene Formulierung, wenn ein Ticket bearbeitet wird: „Wir möchten Sie darüber informieren, dass das Problem, das Sie im [Monat] gemeldet haben, als Produkt-Backlog-Eintrag protokolliert wurde. Wir können uns zu keinem konkreten Zeitplan verpflichten, aber Ihr Bericht hat dazu beigetragen, dass das Team dies priorisiert. Wir melden uns, wenn es eine Statusaktualisierung gibt." Wenn ein Ticket nicht bearbeitet wird: „Wir haben das von Ihnen gemeldete Problem geprüft. Basierend auf aktuellen Prioritäten und der Anzahl betroffener Konten hat es es nicht in den aktiven Backlog geschafft. Wir behalten es in den Unterlagen und werden es im nächsten Planungszyklus neu bewerten. Vielen Dank für die Details." Beide Nachrichten schließen die Schleife, ohne Versprechen zu machen.
Welche Metriken zeigen, dass die Support-to-Backlog-Pipeline gesund ist?
Fünf Metriken: Tagging-Rate beim Eingang (Ziel 90 %+), Prüfung von Produktflag-Tickets innerhalb des 48-Stunden-SLA (Ziel 85 %+), Ticket-to-Backlog-Konversionsrate (Ziel 25 bis 40 %), Kunden-Benachrichtigungsrate wenn Tickets bearbeitet werden (Ziel 100 %) und mediane Zeit vom ersten Ticket bis zur PM-Triage (Ziel unter 10 Werktage). Wenn die Tagging-Rate unter 80 % fällt, produziert der Rest der Pipeline unzuverlässige Daten, unabhängig davon, wie gut die anderen Stufen funktionieren. Monatlich verfolgen; ein Rückgang der Tagging-Rate ist immer das erste Symptom eines Pipeline-Zusammenbruchs.

Senior Operations & Growth Strategist
On this page
- Warum Support-Tickets das am meisten unterschätzte Produktsignal sind
- Stufe 1: Tagging bei Eingang
- Stufe 2: Triage-Gate: Support-Problem oder Produktproblem?
- Stufe 3: Eskalation an CS: Der Brücken-Schritt
- Stufe 4: Produkt-Backlog-Übergabe
- Stufe 5: Schließen der Feedback-Schleife zu Support und Kunden
- Metriken zur Messung der Pipeline-Gesundheit
- Häufige Fehlermuster
- Wie das mit Mustererkennung zusammenhängt
- Mehr erfahren
- Häufig gestellte Fragen
- Was ist die 5-stufige Support-to-Backlog-Pipeline?
- Warum erreichen nur 23 % der Support-Tickets mit Produktfeedback das Product-Team?
- Was ist ein Bridge-Ticket und was sollte es enthalten?
- Wie sieht ein gut geformter Backlog-Eintrag im Vergleich zu einem schlecht geformten aus?
- Was ist das Triage-Gate und wer verantwortet es?
- Wie schließt man die Feedback-Schleife, ohne Verbindlichkeiten einzugehen?
- Welche Metriken zeigen, dass die Support-to-Backlog-Pipeline gesund ist?