Del Ticket de Soporte al Elemento del Backlog: El Pipeline Operativo que los Equipos de CS Necesitan
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Dos equipos están resolviendo el mismo problema. Los agentes de soporte responden cada semana la misma pregunta sobre el flujo de trabajo de exportación masiva. Han creado un script para ello, lo han añadido a las preguntas frecuentes y lo resuelven en menos de cuatro minutos. Al otro lado del edificio, el equipo de producto está decidiendo si invertir tiempo de ingeniería en funcionalidades de exportación este trimestre.
Nunca han hablado.
Esto no es un fallo de comunicación. Es un fallo de pipeline. Soporte tiene la señal: frecuencia, lenguaje literal, distribución por cuentas. Producto tiene la autoridad de decisión. Pero entre ambos existe una brecha desestructurada donde las señales mueren como tickets cerrados y las decisiones de producto se toman por intuición y según quién apareció en la reunión de roadmap.
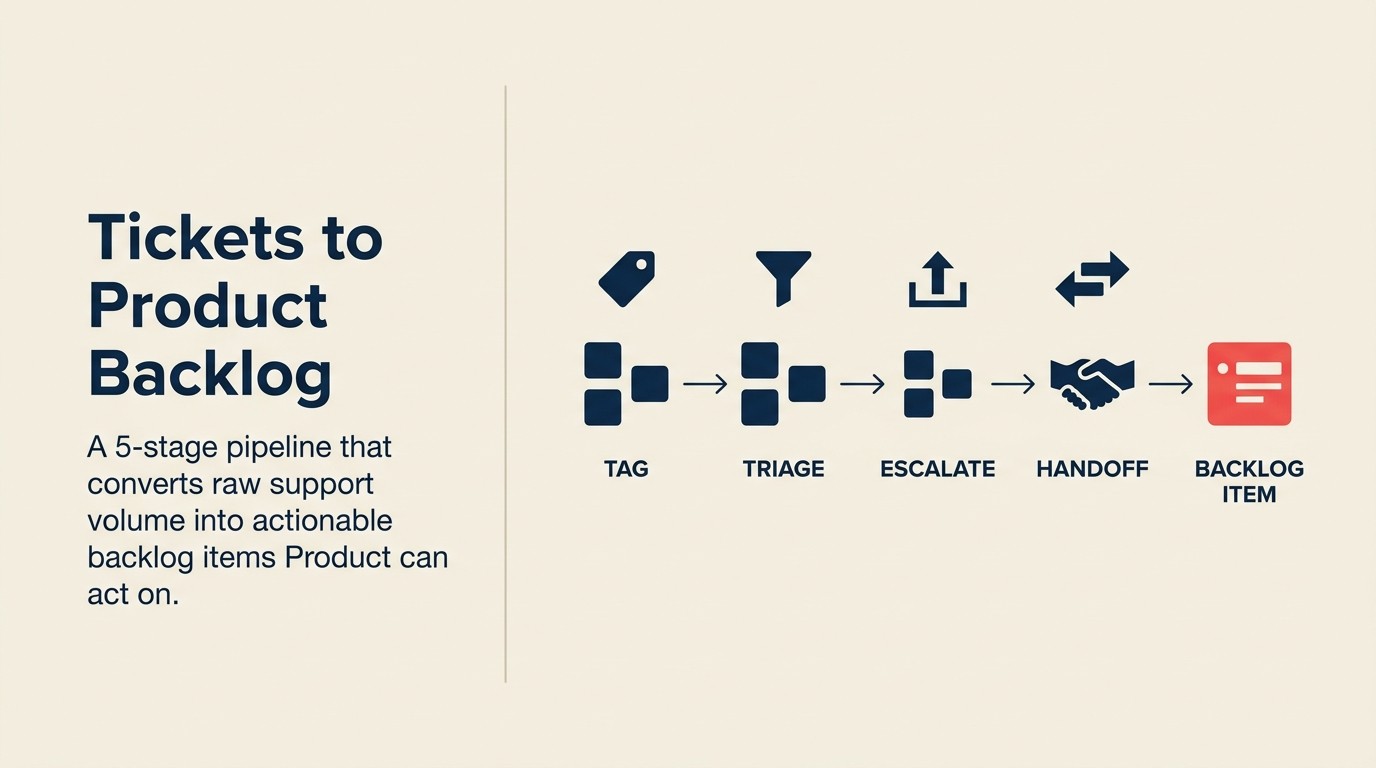
La solución no es una reunión general semanal. Es un pipeline operativo con cinco etapas definidas y responsables claros en cada transferencia. El glosario de alineación CS-Producto define qué significan exactamente "escalamiento", "elemento de backlog" y "cierre del ciclo de retroalimentación". Eso importa cuando soporte, CS y producto utilizan esas palabras de manera diferente.
El Pipeline de Soporte al Backlog en 5 Etapas estructura ese recorrido: Etiquetado en la Entrada → Puerta de Triage → Puente CS → Transferencia al Backlog → Cierre del Ciclo. Cada etapa tiene un responsable definido, un SLA con tiempo límite y un resultado específico del que depende la etapa siguiente. Omita cualquier etapa y la señal se degrada o desaparece por completo.
Por Qué los Tickets de Soporte Son la Señal de Producto Más Infrautilizada
Los tickets de soporte tienen tres propiedades que ningún otro canal de retroalimentación iguala: volumen, frecuencia y lenguaje literal del cliente.
Un consejo consultivo de clientes le da profundidad. Un QBR le da contexto estratégico. Pero los tickets de soporte le dan lo que los clientes dicen realmente cuando están frustrados y no actúan para una audiencia. El lenguaje que un cliente usa para describir un error o una solicitud de solución provisional suele ser más útil diagnósticamente que cualquier cosa que dijeran en una entrevista estructurada.
Pero ninguna de esas señales vive en una herramienta de planificación de roadmap. Vive en Zendesk, Intercom o Freshdesk, cerrada y archivada tras la resolución, invisible para el equipo de PM que construye el sprint del próximo trimestre. La investigación de McKinsey sobre operaciones de customer success confirma que la experiencia de producto es uno de los dos principales impulsores de los resultados de customer success. Sin embargo, menos del 10% de las empresas han asignado a los product managers una responsabilidad formal para actuar sobre las señales derivadas del soporte.
El pipeline que se describe a continuación conecta esos dos mundos. No requiere nuevas herramientas. Requiere nuevos hábitos en cinco puntos definidos.
Datos Clave: La Brecha de Señal entre Soporte y Producto
- Solo el 23% de los tickets de soporte al cliente que contienen retroalimentación de producto se escalan formalmente a los equipos de producto (informe de Tendencias de la Experiencia del Cliente de Zendesk). El 77% restante se resuelve y archiva sin llegar al backlog.
- Las empresas con un pipeline formal de retroalimentación de soporte a producto resuelven los problemas recurrentes a nivel de producto un 40% más rápido que las que no tienen ninguno (Gainsight, 2024).
- El 61% de los líderes de CS reporta que su equipo de soporte y su equipo de producto utilizan un lenguaje diferente para describir los mismos problemas de clientes, lo que hace que el análisis a nivel de ticket sea poco fiable sin una taxonomía compartida (Customer Success Collective, 2024).
Etapa 1: Etiquetado en la Entrada
La taxonomía es la base. Sin ella, ninguna etapa posterior ocurre o produce ruido.
Las cuatro categorías de tickets:
- Error: El producto no se comporta según la documentación. El comportamiento esperado existe y es incorrecto. Enrutamiento: triage de ingeniería.
- Solicitud de solución provisional: El cliente está haciendo algo manualmente que debería estar automatizado. El producto funciona según el diseño, pero el diseño genera fricción. Enrutamiento: equipo de plataforma CS o PM, según la gravedad y la frecuencia.
- Brecha de funcionalidad: El cliente necesita una funcionalidad que no existe y no puede aproximarse con las funciones existentes. Enrutamiento: vía de escalamiento CS-PM.
- Problema de formación: El producto ya puede hacer lo que el cliente solicita. La brecha está en la documentación o en la incorporación, no en el producto. Enrutamiento: habilitación de CS, no PM.
La distinción formación/brecha de funcionalidad es la que los agentes de soporte se equivocan con más frecuencia. Un ticket que parece "no podemos hacer exportaciones masivas" a veces significa "no sabemos cómo hacer exportaciones masivas." Equivocarse en esto hace que las bandejas de entrada de PM se llenen de solicitudes de formación que deberían haber ido al equipo de la base de conocimiento.
Estructura de etiquetas: [Área de producto] + [Categoría de ticket] + [Nivel de cuenta]
Ejemplo: CRM > Brecha de Funcionalidad > Enterprise
Esta estructura de etiquetas hace el ticket consultable en tres dimensiones. Puede preguntar "¿cuántos tickets de brecha de funcionalidad enterprise llegaron al módulo CRM este mes?" en menos de 30 segundos.
Qué ocurre cuando los tickets no tienen etiquetas: La señal desaparece. Los tickets sin etiquetar son individualmente buscables pero colectivamente invisibles. No es posible ninguna agregación. La etapa de detección de patrones nunca se activa. Los PM toman decisiones basándose en las voces más fuertes, no en los patrones más comunes. Una vez que el etiquetado es consistente, la siguiente pregunta es qué tickets etiquetados salen realmente de la cola de soporte.
Nota sobre herramientas: esta taxonomía funciona en Zendesk, Intercom, Freshdesk y cualquier otra herramienta de soporte que admita etiquetas o campos personalizados. La implementación específica varía; la estructura de la taxonomía no. El stack de plataforma CS y CRM alineado cubre cómo sus herramientas de upstream (el CRM y la plataforma CS) deben estar conectadas antes de que el etiquetado a nivel de ticket pueda fluir limpiamente hacia el backlog de producto sin reingreso manual.
Etapa 2: Puerta de Triage: ¿Problema de Soporte o Problema de Producto?
No todos los tickets etiquetados necesitan avanzar. La puerta de triage decide qué tickets salen del sistema de soporte y cuáles se cierran allí.
Criterios de decisión:
¿Puede resolverse esto usando la funcionalidad existente del producto? Si la respuesta es sí, se queda en soporte. Si no, o si la respuesta requiere una solución provisional que no debería ser necesaria, avanza hacia la vía de escalamiento de producto.
Quién toma la decisión:
Para los tickets de error y brecha de funcionalidad, el líder del equipo de soporte toma la decisión inicial. Para cualquier ticket donde la decisión sea ambigua, la validación del CSM es el siguiente paso (Etapa 3). No enrute tickets ambiguos directamente al PM. Eso crea el modo de fallo de "escalamiento ruidoso" donde las bandejas de entrada de PM se llenan de problemas a medio filtrar.
SLA de escalamiento:
Los tickets marcados como problemas de producto deben ser revisados por el equipo de CS en las 48 horas siguientes al etiquetado. Si un ticket permanece etiquetado como problema de producto durante más de 48 horas sin revisión del CSM, efectivamente se pierde. El contexto del cliente está desactualizado y el agente de soporte no puede añadir más detalles sin volver a contactar al cliente.
Modos de fallo del triage:
Sobreescalamiento: Soporte marca todo para producto porque "más vale prevenir que lamentar." La bandeja de entrada del PM se inunda. Los PM empiezan a ignorar el canal de escalamiento. Las señales reales quedan enterradas en el ruido.
Infraescalamiento: Soporte resuelve todo localmente porque "ese es nuestro trabajo." Los errores conocidos permanecen ocultos durante meses. Las brechas de funcionalidad nunca salen a la superficie. Los PM creen que el producto funciona mejor de lo que realmente funciona.
La puerta de triage solo funciona cuando los líderes de soporte están capacitados en los criterios de decisión y son responsables del SLA de 48 horas. Ninguna de esas dos cosas ocurre automáticamente.
Etapa 3: Escalamiento a CS: El Paso Puente
Cuando soporte marca un ticket como problema de producto, CS es el puente entre la realidad de cara al cliente y el vocabulario de trabajo del equipo de producto.
Qué hace el CSM:
Primero, validar si el problema es específico de una cuenta o es transversal. Un problema específico de una cuenta puede ser un problema de configuración o una brecha de formación disfrazada de solicitud de funcionalidad. Un problema transversal es una señal de producto. El CSM tiene el contexto de cuenta para distinguir entre ambos.
Segundo, enriquecer el ticket con la información que los PM realmente necesitan: el ARR de las cuentas afectadas, el calendario de renovación de la cuenta con mayor riesgo que reporta el problema, la puntuación de salud de cada cuenta y cualquier contexto de importancia estratégica (cuentas nombradas, conversaciones de expansión en curso).
Tercero, crear el ticket puente: el escalamiento formateado que recibe el equipo de PM. No es un ticket de soporte reenviado. Es una señal de producto sintetizada.
Formato del ticket puente:
Resumen del problema: [1-2 frases en lenguaje sencillo]
Área de producto: [según la taxonomía de etiquetas]
Categoría de ticket: [Error / Solicitud de Solución Provisional / Brecha de Funcionalidad]
Cuentas afectadas: [lista por nombre]
ARR total afectado: $[X]
Cuenta con mayor riesgo: [Nombre, ARR, fecha de renovación, puntuación de salud]
Frecuencia: [N cuentas únicas, N tickets totales en los últimos 90 días]
Lenguaje literal del cliente: "[cita del ticket: oro para UX]"
Pasos de reproducción (solo errores): [pasos numerados]
Comportamiento esperado vs. comportamiento real (solo errores): [descripción clara]
Valoración de prioridad del CSM: P1 / P2 / P3 [con breve justificación]
Este formato obtiene la atención del PM porque responde las preguntas que los PM hacen antes de priorizar cualquier cosa: cuántos clientes, cuánto ARR, qué tan reproducible, qué tan urgente.
Etapa 4: Transferencia al Backlog de Producto
El ticket puente logra que el PM lo revise. El formato de transferencia al backlog determina si el PM actúa.
Cómo es un elemento de backlog bien formado:
Título: [Exportación masiva: los clientes no pueden exportar más de 500 filas sin truncamiento de datos]
Declaración de impacto en el cliente: 14 cuentas (ARR total $1,2M) han reportado esto en los últimos 90 días.
Tres cuentas lo han señalado como riesgo de renovación. Dos están en conversaciones activas de expansión
donde esta limitación es un bloqueador.
Pasos de reproducción: [numerados, verificados por soporte]
Comportamiento esperado: El usuario puede exportar el conjunto de datos completo independientemente del número de filas
Comportamiento real: La exportación se trunca a 500 filas sin mensaje de error
Lenguaje literal del cliente: "Tenemos que ejecutar cuatro exportaciones y unirlas en Excel.
Esto es vergonzoso para mostrar al equipo."
ARR afectado: $1,2M en 14 cuentas
Cuentas con riesgo de abandono: 3 (marcadas por CSMs como en riesgo)
Frecuencia: 22 tickets en los últimos 90 días, 14 cuentas únicas
Recomendación de prioridad: P2 (impacto significativo en ARR, sin solución provisional actual sin manipulación de datos)
Cómo es un elemento de backlog mal formado:
Título: [Problema de exportación masiva]
Descripción: Varios clientes se han quejado de la exportación. ¿Podemos arreglarlo?
La versión mal formada queda sin prioridad no porque los PM no sean receptivos, sino porque no pueden evaluarla. Sin impacto en ARR, sin pasos de reproducción, sin datos de frecuencia, sin lenguaje del cliente. Cada PM del equipo tiene 30 elementos que se ven así. Priorizan los que entienden.
Quién es responsable de la transferencia:
En equipos de menos de 10 CSMs, el CSM que escalonó el ticket es responsable de la transferencia. En equipos más grandes, CS Ops o un CSM designado como enlace de producto es responsable de la síntesis y transferencia de todos los problemas transversales.
Higiene del backlog:
Distinguir tres estados: tickets cerrados (resueltos en soporte, sin más acción), elementos de retroalimentación abiertos (reconocidos por el PM, en evaluación) y elementos de backlog aceptados (comprometidos para un sprint o trimestre del roadmap). Si no mantiene estas distinciones, "enviado a producto" pierde su significado. Todo lo enviado parece igual que todo lo que se actúa.
Etapa 5: Cierre del Ciclo hacia Soporte y el Cliente
Este es el paso que la mayoría de los equipos omite. También es el paso que determina si el pipeline seguirá funcionando seis meses después.
Notifique a soporte cuando un ticket se convierte en elemento de backlog:
El agente de soporte que gestionó el ticket original debe saber que su escalamiento importó. No como ejercicio de motivación, sino como señal operativa. Si los agentes de soporte nunca saben qué ocurre con los tickets que marcan, dejan de marcarlos. El pipeline se degrada por desuso.
Un mensaje sencillo en Slack o un comentario en el ticket es suficiente: "El problema de exportación masiva que escaló (Ticket #12847) ha sido registrado como elemento de backlog. Prioridad actual: P2. Revisión esperada en la próxima planificación de sprint."
Notifique al cliente cuando su ticket influyó en una decisión de producto:
Aquí es donde la mayoría de los equipos duda porque no quieren comprometerse con un calendario. Pero existe un lenguaje que cierra el ciclo sin hacer promesas. El contenido de formación del cliente cubre cómo convertir estas actualizaciones en documentación proactiva, para que el próximo cliente que tenga el mismo problema encuentre un artículo de ayuda antes de abrir un ticket.
"Queremos informarle de que el problema que reportó en [mes] ha sido registrado como elemento del backlog de producto. No podemos comprometernos con un calendario específico, pero su reporte contribuyó a que el equipo lo priorizara. Le contactaremos cuando haya una actualización del estado."
Qué no decir: "Lo estamos arreglando en el T3." Eso es una promesa. El mensaje de cierre del ciclo es una notificación, no un compromiso.
El marco de HBR sobre cómo incorporar ciclos de retroalimentación en los productos recomienda tratar el cierre del ciclo como una característica del producto en lugar de un paso del proceso. Los clientes que reciben respuesta tras plantear un problema son significativamente más propensos a comunicar la próxima señal.
Qué decir cuando el ticket NO va a gestionarse:
"Hemos revisado el problema que reportó. Basándonos en las prioridades actuales y en el número de cuentas afectadas, no ha podido incorporarse al backlog activo. Lo mantenemos en archivo y lo reevaluaremos en el próximo ciclo de planificación. Gracias por los detalles. Ayudan aunque la respuesta inmediata sea negativa."
Este es el mensaje más difícil de enviar. También es el que genera más confianza con el tiempo.
Métricas para Monitorear la Salud del Pipeline
Las orientaciones de Gartner sobre la voz del cliente señalan que los insights de VoC procedentes de las interacciones de servicio son uno de los activos estratégicos menos utilizados en la mayoría de las organizaciones. Los equipos los recopilan pero raramente crean un proceso continuo para actuar sobre ellos a nivel de producto.
| Métrica | Objetivo | Qué indica un incumplimiento |
|---|---|---|
| % de tickets de soporte etiquetados en la entrada | 90%+ | Brecha en la formación de taxonomía o problema de configuración de herramientas |
| % de tickets marcados como problema de producto revisados dentro del SLA de 48 horas | 85%+ | Problema de capacidad del CSM o fallo en el canal de escalamiento |
| Tasa de conversión de ticket a backlog | 25-40% | Sobreescalamiento (demasiados tickets llegando al PM) o infra-actuación (PM no hace triage) |
| Tasa de notificación al cliente cuando los tickets son gestionados | 100% | El paso de cierre del ciclo se está omitiendo |
| Tiempo medio desde el primer ticket hasta el triage del PM | menos de 10 días hábiles | Cuello de botella en el triage, normalmente en la Etapa 2 o la Etapa 3 |
Haga seguimiento mensual. Si la tasa de etiquetado cae por debajo del 80%, el resto del pipeline produce resultados deficientes independientemente de lo bien que funcionen las otras etapas.
Modos de Fallo Comunes
El agujero negro: Los tickets se etiquetan y escalan. Nada regresa. Los CSMs dejan de escalar porque no hay evidencia de que importe. El pipeline se vacía desde arriba.
Solución: Establezca un SLA de reconocimiento obligatorio del PM. En los cinco días hábiles siguientes a la llegada de un ticket puente, el PM reconoce su recepción y proporciona una evaluación de prioridad preliminar. Incluso "no se va a priorizar este trimestre" cierra el ciclo. Las mejores prácticas para llamadas de resolución de problemas de CS cubre cómo los CSMs pueden estructurar el momento en la llamada cuando aparece una brecha de producto conocida, ganando tiempo sin hacer promesas mientras el elemento de backlog está en revisión.
El escalamiento ruidoso: El sobreescalamiento inunda la bandeja de entrada del PM. Los PM crean un filtro mental que resta prioridad a cualquier cosa de CS porque la relación señal-ruido es demasiado baja.
Solución: Ajuste los criterios de la Etapa 2. Solo los problemas transversales con impacto en ARR por encima de un umbral definido escalan al PM. Los problemas de una sola cuenta se resuelven en la Etapa 3 a menos que cumplan criterios específicos de cuenta estratégica.
Promesas no intencionadas: Un agente de soporte o CSM le dice a un cliente "me aseguraré de que producto lo sepa" de una manera que el cliente interpreta como un compromiso. Se crean expectativas que el pipeline no puede cumplir.
Solución: Capacite a soporte y CS con el lenguaje exacto para cada etapa: qué significa "voy a escalar esto" (entra en el pipeline, no es una acción directa del PM), qué significa "ha sido registrado" (existe en el backlog, no que se vaya a lanzar) y qué significa "le mantendremos informado" (recibirá noticias de CS cuando cambie el estado, no diariamente).
Cómo Conecta Esto con el Reconocimiento de Patrones
El pipeline de tickets de soporte captura señales individuales. El reconocimiento de patrones entre CSMs es lo que ocurre cuando se agregan esas señales en todo el portafolio de cuentas y se buscan temas que ningún ticket individual revela. Los dos procesos son secuenciales: los tickets individuales deben estar etiquetados y estructurados (este pipeline) antes de que puedan detectarse patrones transversales. Y una vez que los patrones emergen, la puntuación de impacto en el cliente es la que da a producto la visión ponderada por ARR y ajustada por riesgo de abandono que convierte un patrón en una recomendación de prioridad defendible.
El pipeline VoC de CS a Producto proporciona el contexto más amplio de cómo el escalamiento de tickets de soporte encaja en el espectro completo de canales de la voz del cliente. La captura sistemática de retroalimentación desde notas de CSM al backlog cubre el canal paralelo donde la retroalimentación se origina en conversaciones del CSM en lugar de interacciones de soporte. Y la integración de la plataforma CS con el backlog de producto cubre la capa de herramientas que automatiza los pasos de transferencia descritos aquí.
Análisis de Rework: Las empresas que ejecutan el Pipeline de Soporte al Backlog en 5 Etapas con todas las etapas dotadas de personal y gobernadas por SLA alcanzan una tasa de conversión de ticket a backlog del 25-40%, frente a menos del 5% en organizaciones sin un pipeline formal. La inversión de mayor impacto es la Etapa 1 (taxonomía) porque determina si todas las etapas siguientes pueden funcionar. Los equipos que omiten el diseño de la taxonomía y van directamente a las vías de escalamiento descubren que las bandejas de entrada del PM se llenan de ruido sin etiqueta en un plazo de 60 días, y el canal de escalamiento queda abandonado de manera informal. Nuestra recomendación: construya primero la taxonomía de cuatro categorías, pruébela durante un mes antes de activar la puerta de triage, y no conecte con las bandejas de entrada del PM hasta que la tasa de etiquetado supere consistentemente el 80%.
Más Información
- Reconocimiento de Patrones entre CSMs: El Problema Sistémico
- El Pipeline VoC: Cómo CS Alimenta a Producto
- Captura Sistemática de Retroalimentación: Notas de CSM al Backlog
- Cierre del Ciclo de Retroalimentación con Clientes
- Integración de la Plataforma CS con el Backlog de Producto
Preguntas Frecuentes
¿Qué es el Pipeline de Soporte al Backlog en 5 Etapas?
El Pipeline de Soporte al Backlog en 5 Etapas es un proceso operativo estructurado que mueve los tickets de soporte al cliente desde la queja sin procesar hasta el elemento accionable del backlog de producto. Las cinco etapas son: Etiquetado en la Entrada (clasificación basada en taxonomía), Puerta de Triage (decisión de problema de soporte vs. problema de producto), Puente CS (enriquecimiento y escalamiento del CSM), Transferencia al Backlog (formato listo para el PM) y Cierre del Ciclo (notificación al agente de soporte y al cliente). Cada etapa tiene un responsable definido y un SLA con tiempo límite.
¿Por qué solo el 23% de los tickets de soporte con retroalimentación de producto llegan al equipo de producto?
La mayoría de las organizaciones no tienen una vía de escalamiento formal que conecte soporte y producto. Según el informe de Tendencias de la Experiencia del Cliente de Zendesk, el 77% de los tickets que contienen retroalimentación de producto se resuelven y archivan sin llegar al backlog. No porque la retroalimentación no sea valiosa, sino porque los agentes de soporte no tienen un mecanismo estructurado para enrutarla. Los tres elementos que faltan son una taxonomía compartida (para que los tickets sean clasificables), una puerta de triage con criterios de decisión claros y un formato puente que traduzca el lenguaje de tickets en datos listos para el PM.
¿Qué es un ticket puente y qué debe incluir?
Un ticket puente es el escalamiento formateado que crea un CSM cuando un problema de soporte se confirma como señal a nivel de producto. No es un ticket de soporte reenviado. Es un documento sintetizado que incluye: resumen del problema en lenguaje sencillo, área de producto y categoría de ticket, nombres de las cuentas afectadas y ARR total, cuenta con mayor riesgo con fecha de renovación y puntuación de salud, datos de frecuencia (cuentas únicas y tickets totales en 90 días), lenguaje literal del cliente, pasos de reproducción para errores y valoración de prioridad del CSM con justificación. Este formato obtiene la atención del PM porque responde las cuatro preguntas que los PM hacen antes de priorizar cualquier cosa: cuántos clientes, cuánto ARR, qué tan reproducible y qué tan urgente.
¿Cómo es un elemento de backlog bien formado frente a uno mal formado?
Un elemento de backlog bien formado tiene un título específico (p. ej., "Exportación masiva: los clientes no pueden exportar más de 500 filas sin truncamiento de datos"), una declaración de impacto en el cliente con ARR y cuentas con riesgo de abandono nombradas, pasos de reproducción verificados por soporte, comportamiento esperado vs. real, lenguaje literal del cliente, datos de frecuencia entre cuentas únicas y una recomendación de prioridad con justificación. Un elemento mal formado dice "problema de exportación masiva: varios clientes se quejaron, ¿podemos arreglarlo?" El mal formado queda sin prioridad no porque los PM no sean receptivos sino porque no pueden evaluarlo frente a los otros 30 elementos que tienen delante.
¿Qué es la puerta de triage y quién la gestiona?
La puerta de triage es la Etapa 2 del Pipeline de Soporte al Backlog en 5 Etapas. Es el punto de decisión donde un líder del equipo de soporte determina si un ticket etiquetado es un problema de soporte (puede resolverse con la funcionalidad existente del producto) o un problema de producto (requiere una solución provisional que no debería ser necesaria, o una funcionalidad que no existe). Para errores y tickets de brecha de funcionalidad con clasificación ambigua, el ticket va a validación del CSM en lugar de directamente al PM. El SLA de 48 horas para la revisión del CSM es el mecanismo de aplicación de la puerta. Los tickets que permanecen etiquetados como problemas de producto más de 48 horas pierden el contexto del cliente y se convierten efectivamente en señales cerradas.
¿Cómo se cierra el ciclo de retroalimentación sin hacer compromisos?
El lenguaje recomendado cuando un ticket es gestionado: "Queremos informarle de que el problema que reportó en [mes] ha sido registrado como elemento del backlog de producto. No podemos comprometernos con un calendario específico, pero su reporte contribuyó a que el equipo lo priorizara. Le contactaremos cuando haya una actualización del estado." Cuando un ticket no va a gestionarse: "Hemos revisado el problema que reportó. Basándonos en las prioridades actuales y en el número de cuentas afectadas, no ha podido incorporarse al backlog activo. Lo mantenemos en archivo y lo reevaluaremos en el próximo ciclo de planificación. Gracias por los detalles." Ambos mensajes cierran el ciclo sin hacer promesas.
¿Qué métricas indican que el pipeline de soporte al backlog es saludable?
Cinco métricas: tasa de etiquetado en la entrada (objetivo 90%+), revisión de tickets marcados como problema de producto dentro del SLA de 48 horas (objetivo 85%+), tasa de conversión de ticket a backlog (objetivo 25-40%), tasa de notificación al cliente cuando los tickets son gestionados (objetivo 100%) y tiempo medio desde el primer ticket hasta el triage del PM (objetivo menos de 10 días hábiles). Si la tasa de etiquetado cae por debajo del 80%, el resto del pipeline produce datos poco fiables independientemente de lo bien que funcionen las otras etapas. Haga seguimiento mensual; una caída en la tasa de etiquetado es siempre el primer síntoma de una avería en el pipeline.

Senior Operations & Growth Strategist
On this page
- Por Qué los Tickets de Soporte Son la Señal de Producto Más Infrautilizada
- Etapa 1: Etiquetado en la Entrada
- Etapa 2: Puerta de Triage: ¿Problema de Soporte o Problema de Producto?
- Etapa 3: Escalamiento a CS: El Paso Puente
- Etapa 4: Transferencia al Backlog de Producto
- Etapa 5: Cierre del Ciclo hacia Soporte y el Cliente
- Métricas para Monitorear la Salud del Pipeline
- Modos de Fallo Comunes
- Cómo Conecta Esto con el Reconocimiento de Patrones
- Más Información
- Preguntas Frecuentes
- ¿Qué es el Pipeline de Soporte al Backlog en 5 Etapas?
- ¿Por qué solo el 23% de los tickets de soporte con retroalimentación de producto llegan al equipo de producto?
- ¿Qué es un ticket puente y qué debe incluir?
- ¿Cómo es un elemento de backlog bien formado frente a uno mal formado?
- ¿Qué es la puerta de triage y quién la gestiona?
- ¿Cómo se cierra el ciclo de retroalimentación sin hacer compromisos?
- ¿Qué métricas indican que el pipeline de soporte al backlog es saludable?