Mustererkennung über CSMs hinweg: Anekdoten in Produktsignale verwandeln
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
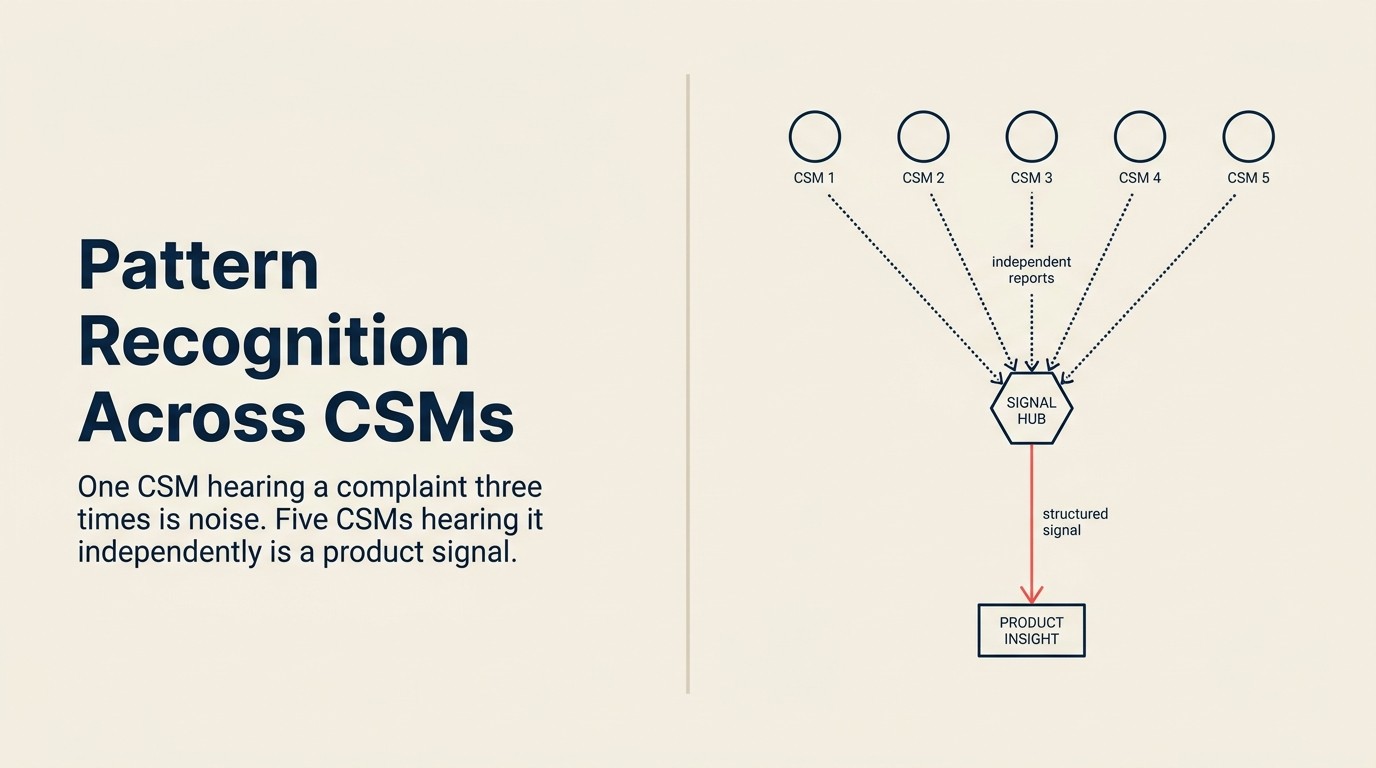
Ein CSM meldet: „Kunden fragen immer wieder nach Massenexport." Der PM notiert das unter „Nice to have" und geht weiter. Drei Monate später erwähnen zwei weitere CSMs Massenexport in separaten QBR-Reviews. Es landet in ihren Notizen, kontobezogen, nirgendwo sichtbar gemacht. Sechs Monate nach dem ersten Bericht haben sechs verschiedene CSMs dasselbe jeweils im Vorbeigehen gesagt, in verschiedenen Gesprächen, mit verschiedenen Worten, ohne dass jemand die Verbindungen herstellt.
Die Funktion steht immer noch nicht auf der Produkt-Roadmap. Das PM-Team weiß immer noch nicht, dass sechs CSMs sie gemeldet haben. Und die CSMs haben größtenteils aufgehört, sie zu erwähnen, weil beim ersten Mal nichts passiert ist.
Das ist kein Kommunikationsversagen. Es ist ein Infrastrukturversagen. Einzelne CSM-Notizen sind kontobezogen abgeschottet. Es gibt keine Taxonomie, um „Massenexport", „Alles herunterladen" und „Massenexport von Daten" als dieselbe zugrunde liegende Anfrage zu verbinden. Und es gibt keine Feedback-Schleife, die CSMs zeigt, dass ihre Beobachtungen irgendwo ankommen.
Die Organisation hat das Signal. Sie kann es nur nicht lesen.
Der CSM-Anekdote-zu-Signal-Schwellenwert beschreibt den Punkt, an dem unabhängige Berichte von verschiedenen CSMs von Zufall zu statistisch bedeutsamen Belegen einer Produktlücke werden. Unterhalb des Schwellenwerts ist jeder Bericht eine Beobachtung auf Kontoebene. Darüber hinaus rechtfertigt das Muster eine formelle Eskalation mit ARR-Gewichtung. Der Schwellenwert ist keine feste Zahl. Er ist eine Funktion von CSM-Teamgröße, ARR-Konzentration und Abwanderungsrisiko, aber er liefert eine explizite Regel, wann zu handeln ist, statt einer vagen Anweisung, „Muster aufzudecken".
Warum Mustererkennung in größerem Maßstab scheitert
Drei strukturelle Probleme verhindern, dass die teamübergreifende Mustererkennung von CSMs natürlich stattfindet. Die Stimme-des-Kunden-Disziplin (formal definiert als das Erfassen der tatsächlichen Beschreibungen gewünschter Funktionen durch Kunden) existiert seit Jahrzehnten im Qualitätsmanagement, aber die meisten B2B-SaaS-Teams haben immer noch keinen systematischen Prozess zur Aggregation über Account Manager hinweg.
CSMs dokumentieren für ihre Konten, nicht für die Organisation. Notizen sind konstruktionsbedingt kontobezogen. Ein CSM fügt dem Kontodatensatz von Acme Corp eine Notiz hinzu. Diese Notiz ist durchsuchbar, wenn Sie sich Acme Corps Datensatz anschauen. Aber sie ist unsichtbar, wenn Sie nach jedem Konto suchen, das in diesem Quartal Massenexport erwähnt hat. Die Datenarchitektur, die einzelne Konten sichtbar macht, macht kontenübergreifende Muster unsichtbar.
Keine gemeinsame Taxonomie bedeutet drei Labels für dasselbe Thema. Ein CSM schreibt „Massenexport". Ein anderer schreibt „Alle Datensätze herunterladen". Ein dritter schreibt „Massendatenexport". Das sind drei separate Einträge in jeder Suche. Aus den Häufigkeitsdaten ergibt sich kein Muster, weil die Häufigkeit auf drei verschiedene Zeichenketten verteilt ist. Ohne kontrolliertes Vokabular sieht derselbe Kundenbedarf wie drei verschiedene Kundenbedürfnisse aus.
Kein Anreiz beizutragen, wenn die Schleife nie geschlossen wird. CSMs sind pragmatisch. Wenn das Loggen von Kundenfeedback in ein gemeinsames System kein sichtbares Ergebnis produziert (keine Bestätigung, kein Backlog-Eintrag, keine ausgelieferte Funktion), hören sie auf zu loggen. Nicht aus Trotz, sondern aus rationaler Ressourcenzuteilung. Loggen kostet Zeit. Wenn nichts passiert, ist diese Zeit verschwendet. Die Beitragsrate sinkt, bis nur noch die gewissenhaftesten CSMs Signale melden, und die Stichprobe ist nicht mehr repräsentativ.
Wichtige Fakten: Warum die kontenübergreifende Mustererkennung scheitert
- Das durchschnittliche Enterprise-B2B-SaaS-Unternehmen hat 8-20 CSMs, die Konten unabhängig voneinander mit kontobezogenen Notizen und ohne gemeinsame Feedback-Taxonomie verwalten, was eine kontenübergreifende Mustererkennung ohne bewusstes Prozessdesign strukturell unmöglich macht, gemäß Gainsights CS Operations Benchmark.
- 71% der Produktmanager berichten, dass das Kundenfeedback, das sie erhalten, nicht systematisch aggregiert wird, bevor es sie erreicht. Sie hören individuelle Anekdoten, keine Muster, gemäß einer ProductBoard-Umfrage unter 600 PMs.
- CS-Teams mit einer gemeinsamen Feedback-Taxonomie produzieren 3,5-mal mehr umsetzbare Produktsignale pro Quartal als Teams ohne eine solche, selbst wenn das gesamte Feedback-Volumen identisch ist, gemäß Gainsight-Forschung.
Das Fundament: Eine gemeinsame Feedback-Taxonomie
Vor jeglichem Tooling brauchen Teams ein kontrolliertes Vokabular. Das ist der Schritt, den die meisten Teams überspringen, weil er sich langsamer anfühlt als einfach mit dem Feedback-Sammeln anzufangen. Aber eine unstrukturierte Feedback-Sammlung ist nur Rauschen mit Zeitstempeln.
Wie man eine Themen-Taxonomie entwirft:
Die Taxonomie hat drei Ebenen:
- Funktionsbereich: die Produktdomäne (z.B. CRM, Reporting, Integrationen, Workflow-Automatisierung)
- Kundenbedarf: was der Kunde zu erreichen versucht (z.B. Massendatenoperationen, Export und Import, Feldanpassung)
- Schweregrad: wie die Lücke den Workflow des Kunden beeinflusst (blockierend, beeinträchtigt, geringfügige Reibung)
Ein gut getaggter Feedback-Punkt sieht aus wie: Reporting > Massendatenoperationen > Blockierend
Dieses Tag ist abfragbar. Sie können in einem Klick fragen: „Wie viele Konten haben ein blockierendes Problem mit Massendatenoperationen?"
Wer die Taxonomie-Governance übernimmt:
CS Ops, nicht einzelne CSMs. Wenn individuelle CSMs eigene Taxonomie-Punkte hinzufügen können, wächst die Taxonomie ohne Einschränkung und verliert ihre Fähigkeit zu aggregieren. Neue Taxonomie-Punkte sollten eine CS Ops-Überprüfung erfordern, bevor sie aktiv werden. Eine 48-Stunden-SLA ist ausreichend.
Was mit Einzelanfragen zu tun ist, die nicht passen:
Taggen Sie sie als Nicht klassifiziert > [Funktionsbereich] > [Schweregrad] und überprüfen Sie den nicht klassifizierten Bucket monatlich. Wenn dasselbe nicht klassifizierte Tag drei oder mehr Mal in einem Monat erscheint, ist es ein Kandidat für einen neuen Taxonomie-Punkt.
Mit dem Vokabular an Ort und Stelle ist die nächste Frage, wie man Signale konsistent im gesamten Team sammelt.
Methode 1: Strukturierter CSM-Sync (wöchentlich oder zweiwöchentlich)
Das ist das Meeting-Format, das Muster aufdeckt. Aber die meisten CS-Team-Syncs sind Kontoüberprüfungen, keine Mustererkennungssessions. Das Format muss sich ändern, bevor sich das Ergebnis ändern kann.
Vorab-Lektüre: Vor dem Meeting reicht jeder CSM 1-3 Kundenbeobachtungen mit einer gemeinsamen Vorlage ein. Nicht als Freitext, sondern als strukturierte Felder: Produktbereich, Kundenbedarf, Schweregrad, Anzahl der Konten, die das erwähnt haben, eventuelle wörtliche Kundenformulierungen, die es wert sind zu bewahren.
Die Vorlage kostet 5 Minuten pro Beobachtung. Wenn es länger dauert, ist die Vorlage zu komplex.
Meeting-Fokus: Das Ziel ist die Identifikation von Überschneidungen, nicht die Überprüfung von Konten. „Welche Themen erschienen in den Vorab-Lektüren mehrerer CSMs?" ist die einzige produktive Frage. Alles, was nur in einem CSM-Beitrag erschien, ist ein Kontoproblem, kein Produktsignal. Behandeln Sie es offline.
Output: Eine priorisierte Liste wiederkehrender Themen, keine Meeting-Zusammenfassung. Der Output sollte beantworten: „Was hat mehr als ein CSM in dieser Woche gehört?" mit einer Zahl und dem betroffenen ARR.
Zeitinvestition: 30 Minuten, nicht 90. Wenn das Meeting länger dauert, funktioniert das Format nicht. Entweder werden die Vorab-Lektüren nicht abgeschlossen (was bedeutet, dass das Meeting die Arbeit erledigt, die die Vorab-Lektüren erledigen sollten) oder die Agenda ist zurück zu Kontoüberprüfungen abgedriftet.
Beispiel: Wie der 1-CSM-, 3-CSM-, 5-CSM-Schwellenwert aussieht
1 CSM meldet Massenexport-Reibung: Beobachtung loggen. Zum nicht klassifizierten oder bekannten Feedback-Bucket hinzufügen. Keine Maßnahme vom Produktteam erforderlich. CSM setzt das Monitoring fort.
3 CSMs melden unabhängig Massenexport-Reibung im gleichen Quartal: Im strukturierten Sync vorstellen. Als Kandidatenmuster dokumentieren. CS Ops führt eine Kontoabfrage durch: Wie viele Konten insgesamt haben dieses Problem referenziert? Welcher ARR ist betroffen? Das quantifizierte Ergebnis als FYI an den PM senden, nicht als Prioritätsanfrage.
5 CSMs melden unabhängig Massenexport-Reibung in verschiedenen Kontosegmenten: Das ist ein Signal, keine Anekdote. Eskalieren Sie durch die Pipeline von Support-Tickets zum Produkt-Backlog mit vollständiger ARR-Gewichtung. Das Muster hat den Schwellenwert überschritten, bei dem es eine formelle PM-Evaluierung rechtfertigt.
Der Schwellenwert bei fünf CSMs ist nicht willkürlich. Es ist der Punkt, an dem die Wahrscheinlichkeit, dass unabhängige Berichte dasselbe zugrundeliegende Problem beschreiben, in einem Team von 8-20 statistisch bedeutsam statt zufällig wird.
Teams, die keine wöchentlichen Syncs durchführen können, brauchen eine asynchrone Alternative, die mit dem Wachstum des Teams skaliert.
Methode 2: Aggregiertes Feedback-Tagging in der CS-Plattform
Für Teams, die nicht auf synchrone Syncs angewiesen sein können oder wollen, ist asynchrone Mustererkennung über die CS-Plattform die Alternative, die mit dem Wachstum des CSM-Teams besser skaliert.
Wie man Feedback in Tools wie Gainsight, ChurnZero oder Salesforce taggt:
Jede Kundeninteraktion, die eine Produktbeobachtung ergibt, sollte einen getaggten Feedback-Punkt in der CS-Plattform erzeugen. Nicht eine Notiz im Kontodatensatz, sondern einen diskreten Feedback-Punkt mit Taxonomie-Tags, ARR des betroffenen Kontos und einem Zeitstempel.
Die meisten CS-Plattformen unterstützen das nativ. Gainsight nennt sie „Timeline-Aktivitäten" mit benutzerdefinierten Tags. ChurnZero hat ein Feedback-Modul. Salesforce unterstützt das mit benutzerdefinierten Objekten. Die Implementierung variiert; die Disziplin, konsistent zu taggen, nicht.
Wöchentlicher oder monatlicher Produktsignalbericht:
CS Ops führt am Ende jeder Woche oder jeden Monats eine Abfrage durch: „Was sind die 5 häufigsten wiederkehrenden Themen nach Häufigkeit, und welcher gesamte ARR ist mit jedem verbunden?"
Der Output ist ein einseitiger Bericht, keine Datenmenge. Fünf Themen, nach Häufigkeit geordnet, mit ARR-Kontext für jedes. Dieser Bericht geht in den gemeinsamen Posteingang des PM-Teams, nicht zu einzelnen PMs, sondern an einen Team-Level-Kanal oder eine E-Mail-Liste.
Wer das an das Produktteam sendet und in welchem Format:
CS Ops sendet es. Kein CSM, nicht der VP CS. CS Ops, weil sie die Aggregationsfähigkeit haben und weil die Weiterleitung über die Führungsebene einen Filter hinzufügt, der das Signal verzerren kann. Der Bericht ist Daten, keine Interessenvertretung. Der Artikel zur Sales-CS-Health-Score-Ausrichtung behandelt, wie man Sales-Kontextsignale in dieselben Konten einbettet, damit der Bericht, den CS Ops an das Produktteam sendet, nicht nur Support-Volumen, sondern auch Expansion-Pipeline-Status und Abwanderungsrisiko widerspiegelt.
Methode 3: CS-Digest an das Produktteam (schriftlich, nicht mündlich)
McKinseys Forschung zu Kundenzuhörprogrammen stellte fest, dass Unternehmen mit formalen Feedback-Aggregationssystemen (im Gegensatz zu Teams, die sich auf das Urteil einzelner Manager verlassen) viel wahrscheinlicher auf Muster als auf isolierte Beschwerden reagieren. Der entscheidende Unterschied ist das Vorhandensein einer gemeinsamen Taxonomie, die es Teams ermöglicht, dasselbe Signal über verschiedene Kanäle hinweg zu erkennen.
Mündlich geteilte Muster verfallen. Der PM, der in der Sync-Meeting war, erinnert sich an die Highlights. Der PM, der nicht dabei war, hört eine Zusammenfassung der Zusammenfassung. Wenn es die Sprint-Planung erreicht, ist das ursprüngliche Signal nicht mehr erkennbar.
Schriftliche Artefakte bleiben bestehen. Sie können referenziert, durchsucht und wiederbesucht werden, wenn drei Monate später ein verwandtes Problem auftaucht.
Format eines CS-Monats-Produktdigests:
CS-zu-Produkt Monatliches Signal-Digest
[Monat, Jahr]
Top 3 Wiederkehrende Themen
1. [Themenname]: [N einzigartige Konten, gesamt ARR €X, Schweregrad: blockierend/beeinträchtigt/gering]
Zusammenfassung: [2-3 Sätze]
Wörtliche Kundenformulierung: "[Zitat]"
Trend: Steigend / Stabil / Sinkend vs. Vormonat
2. [Themenname]: [gleiches Format]
3. [Themenname]: [gleiches Format]
Neue Signale (Erstes Auftreten in diesem Monat)
- [Thema]: [1 Satz, N Konten]
Gelöst oder geschlossen (Signale, die nicht mehr erscheinen)
- [Thema]: [Grund, z.B. „Funktion ausgeliefert", „Workaround dokumentiert", „Konten gelöst"]
Erbetene Maßnahmen vom Produktteam
- Eingangsbestätigung bis [Datum]
- Vorläufige Prioritätsbewertung für das führende Thema bis [Datum]
Häufigkeit vs. Aktualitäts-Abwägung:
Monatlicher Digest vs. quartalsweiser Deep-Dive. Monatlich gewinnt für schnell agierende Produktteams mit häufigen Sprint-Zyklen. Quartalsweise gewinnt für Teams, bei denen die PM-Bandbreite für Synthese wirklich begrenzt ist und die Produkt-Roadmap auf quartalsweisen Planungszyklen basiert. Versuchen Sie nicht beides. Wählen Sie einen Rhythmus und halten Sie ihn ein.
Was das Produktteam mit dem Digest tun sollte:
Eingang bestätigen. Vorläufige Prioritätsbewertung für das führende Thema innerhalb von fünf Werktagen bereitstellen. Selbst „nicht in diesem Quartal im Scope" ist eine akzeptable Antwort. Die Bestätigung ist das, was sicherstellt, dass der Digest nächsten Monat wieder ankommt.
Das Schwellenwertproblem: Wie viele Berichte bilden ein Signal?
HBRs Forschung zum Aufbau von Kundendaten-Feedback-Schleifen argumentiert, dass das wertvollste Signal nicht das Volumen, sondern das Wiederauftreten ist. Dieselbe Reibung, die unabhängig bei verschiedenen Nutzern und in verschiedenen Kontexten erscheint, ist ein stärkerer Beleg für eine echte Produktlücke als ein einzelner Kunde, der häufig klagt.
Häufigkeit allein ist ein schlechter Schwellenwert. Fünf Kunden, die dasselbe Problem melden, klingt nach einem Signal. Aber wenn diese fünf Kunden 150.000 USD gesamt ARR repräsentieren und keiner gefährdet ist, ist das ein anderer Business Case als drei Kunden, die 1,2 Mio. USD ARR repräsentieren und von denen zwei als Abwanderungsrisiko markiert sind.
Faustformel-Frameworks:
Häufigkeitszählung: Der Schwellenwert, der für die meisten Mid-Market-Teams funktioniert, liegt bei 3+ einzigartigen Konten in einem einzigen Quartal. Darunter ist es eine Anekdote. Darüber ist es ein Kandidat für den strukturierten Eskalationspfad.
ARR-Gewicht: Jedes Thema, bei dem der kumulierte ARR der betroffenen Konten 10% Ihres gesamten ARR übersteigt, rechtfertigt sofortige Eskalation unabhängig von der Kontoanzahl. Ein Enterprise-Kunde, der 500.000 USD in einem 5-Mio.-USD-ARR-Portfolio repräsentiert, ist eine andere Situation als fünfzehn Konten zu je 10.000 USD.
Korrelation mit Abwanderungsrisiko: Wenn 2 oder mehr gefährdete Konten dasselbe Problem nennen, eskalieren Sie sofort unabhängig von Häufigkeit oder ARR. Der Abwanderungskoeffizient verstärkt jedes andere Signal. Eine Funktionslücke, die in einem gesunden Konto P3 wäre, ist P1 in einem Konto mit Verlängerung in 60 Tagen und einem gelben Health Score.
Wann die Beschwerde eines einzelnen High-ARR-Kunden zehn kleine Konten überwiegt:
Regelmäßig. Ein benanntes Enterprise-Konto, das 8% des ARR repräsentiert und aktiv mit Abwanderung über eine spezifische Produktlücke droht, wird und sollte zehn kleine Konten mit geringer Reibung überwiegen. Das ist kein Fehler im Bewertungssystem. Es ist eine ehrliche Anerkennung der Geschäftsrealität. Customer-Impact-Scoring für Produktentscheidungen behandelt das zusammengesetzte Bewertungsmodell, das diesen Kompromiss explizit statt implizit macht.
Die Schleife schließen, um Beiträge aufrechtzuerhalten
Das ist das Personenproblem. Der Prozess funktioniert. Aber er funktioniert nur weiter, wenn CSMs weiterhin beitragen, und CSMs tragen nur weiterhin bei, wenn sie Belege dafür sehen, dass es wichtig ist.
Bestätigen, wenn ein Muster zum Backlog-Punkt wird:
Wenn ein wiederkehrendes Thema aus dem CS-Digest den Produkt-Backlog erreicht, sendet CS Ops eine Benachrichtigung an alle CSMs, die dieses Thema gemeldet haben: „Das Massenexport-Problem, das Sie gemeldet haben, wurde als P2-Backlog-Punkt eingetragen. Erwartete Überprüfung in der Q3-Planung."
Diese Benachrichtigung dauert 2 Minuten zum Senden. Sie signalisiert jedem CSM, der beigetragen hat, dass seine Beobachtung ein Ziel hatte.
Rückmeldung geben, wenn eine mustergetriebene Funktion ausgeliefert wird:
Wenn eine Funktion, die als CS-Mustersignal entstand, in den allgemeinen Betrieb (GA) geliefert wird, sendet der VP CS eine Notiz an das CS-Team: „Die Massenexport-Funktion, die diese Woche ausgeliefert wird, wurde durch sechs CSM-Berichte über Q1 identifiziert. Hier ist, was wir ausgeliefert haben, und hier ist die kundenseitige Release-Notiz."
Das schließt die Schleife auf Team-Ebene. Es gibt CSMs auch die Sprache, die sie mit den Kunden verwenden können, die das Problem ursprünglich gemeldet haben.
Der kumulative Effekt:
CSMs, die sehen, dass ihre Beobachtungen den Backlog erreichen, loggen im folgenden Quartal 2-3-mal mehr Beobachtungen als CSMs, die keine Rückmeldung zu ihren Beiträgen erhalten, gemäß Gainsights CS-Operations-Forschung. Der Schleifen-Abschluss ist keine optionale Bereicherung. Er ist der Mechanismus, der die Pipeline am Leben erhält.
Kennzahlen zur Messung der Mustererkennungsgesundheit
| Kennzahl | Ziel | Was ein Verfehlen signalisiert |
|---|---|---|
| % des Feedbacks mit Standard-Taxonomie getaggt | 85%+ | Schulungslücke oder Taxonomie zu komplex |
| Unterschiedliche Muster pro Quartal aufgedeckt | 4-8 | Entweder Überfilterung (zu wenige) oder Unteraggregation (zu viele) |
| % der aufgedeckten Muster, die den Produkt-Backlog erreichen | 30-50% | Entweder Übereskalation oder PM triagiert nicht |
| Zeit vom ersten Bericht zur Mustererkennung (Durchschnitt) | <45 Tage | Sync-Rhythmus zu selten oder Aggregationsengpass |
| CSM-Beitragsrate (% der CSMs, die pro Zyklus strukturiertes Feedback einreichen) | 80%+ | Schleife wird nicht geschlossen; CSMs haben sich abgekoppelt |
Überprüfen Sie diese quartalsweise gemeinsam mit VP CS und Head of Product. Wenn die Beitragsrate unter 60% sinkt, ist die Schleife gebrochen. Diagnostizieren Sie, ob es die Taxonomie, das Sync-Format oder das Fehlen von Bestätigung ist.
Wie Mustererkennung mit dem breiteren System verbindet
Mustererkennung ist die mittlere Schicht des CS-Produkt-Feedback-Stacks. Die Support-Ticket-Pipeline liefert strukturierte Einzelsignale aus dem Support-Kanal. Mustererkennung aggregiert diese Signale (und die Signale aus CSM-Gesprächen) über Konten hinweg und deckt Themen auf, die kein einzelnes Ticket erkennen lässt.
Sobald Themen identifiziert sind, gibt die ARR-gewichtete Feedback-Quantifizierung den finanziellen Kontext, den Produktteams zur Priorisierung benötigen. Und das Customer-Impact-Scoring für Produktentscheidungen ist das formale Bewertungsmodell, das die Muster gegen ARR, Abwanderungsrisiko und strategischen Kontowert gewichtet, bevor dem Produktteam eine priorisierte Ansicht präsentiert wird.
Die VoC-Pipeline von CS zu Produkt ist das übergreifende Framework, das all diese Schichten verbindet. Feedback systematisch erfassen: CSM-Notizen zum Backlog behandelt die individuellen Beitrags-Mechanismen ausführlicher.
Rework-Analyse: Basierend auf CS-Operations-Benchmarks über Mid-Market-SaaS-Teams mit 8-20 CSMs ist der CSM-Anekdote-zu-Signal-Schwellenwert von 3+ einzigartigen Konten in einem einzigen Quartal der Wendepunkt, an dem die Wahrscheinlichkeit eines Falschmusters unter 15% sinkt. Darunter sind die Chancen zu hoch, dass der Anwendungsfall eines Kontos mehrere Berichte antreibt, um eine PM-Eskalation zu rechtfertigen. Über 5 (insbesondere wenn die Berichte verschiedene Kontosegmente und Health Scores umspannen) hat das Muster ein statistisches Konfidenzniveau, das eine formelle Backlog-Behandlung rechtfertigt. Unsere Framework-Empfehlung: Kombinieren Sie den Häufigkeitsschwellenwert mit einem ARR-Gate (kumulierter ARR der betroffenen Konten über 10% des gesamten ARR) und einem Abwanderungsrisiko-Check (2+ gefährdete Konten, die dasselbe Problem nennen). Zwei dieser drei Bedingungen lösen die Eskalation aus; alle drei sind ein sofortiges P1 unabhängig von der absoluten Kontoanzahl.
Mehr erfahren
- Support-Tickets zu Produkt-Backlog-Punkten
- Die VoC-Pipeline: Wie CS das Produktteam speist
- Feedback systematisch erfassen: CSM-Notizen zum Backlog
- Customer-Impact-Scoring für Produktentscheidungen
- ARR-gewichtetes Feedback: Die Stimme des Kunden quantifizieren
Häufig gestellte Fragen
Was ist der CSM-Anekdote-zu-Signal-Schwellenwert?
Der CSM-Anekdote-zu-Signal-Schwellenwert ist der Punkt, an dem unabhängige Feedback-Berichte von verschiedenen CSMs von zufälligen Kontobeobachtungen zu statistisch bedeutsamen Belegen einer Produktlücke werden. Für die meisten Mid-Market-SaaS-Teams mit 8-20 CSMs liegt der praktische Schwellenwert bei 3+ einzigartigen Konten, die dasselbe Problem innerhalb eines einzigen Quartals melden. Darunter sind die Daten auf Kontoebene. Darüber rechtfertigen sie formelle Aggregation, ARR-Gewichtung und Eskalation an das Produktteam durch die strukturierte Pipeline.
Warum erhalten 71% der Produktmanager individuelle Anekdoten statt aggregierter Muster?
Weil die meisten CS-Organisationen keine gemeinsame Feedback-Taxonomie und keinen formalen Aggregationsprozess haben. Laut einer ProductBoard-Umfrage unter 600 PMs berichten 71%, dass Kundenfeedback als individuelle Konten statt als synthetisierte Signale ankommt. Die Grundursache ist architektonisch: CSM-Notizen sind konstruktionsbedingt kontobezogen (sichtbar bei der Ansicht von Acme Corps Datensatz, unsichtbar bei der Suche nach allen Konten, die Massenexport erwähnen). Ohne kontrolliertes Vokabular und einen regelmäßigen Aggregationsschritt sieht dasselbe Kundenproblem wie drei verschiedene Probleme aus, weil drei CSMs drei verschiedene Labels dafür verwendet haben.
Was ist eine gemeinsame Feedback-Taxonomie und wie baut man eine auf?
Eine gemeinsame Feedback-Taxonomie ist ein kontrolliertes Vokabular, das Kundenbeobachtungen auf drei Ebenen standardisierten Labels zuordnet: Funktionsbereich (z.B. CRM, Reporting, Integrationen), Kundenbedarf (z.B. Massendatenoperationen, Feldanpassung) und Schweregrad (blockierend, beeinträchtigt, geringfügige Reibung). Eine gut getaggte Beobachtung lautet „Reporting > Massendatenoperationen > Blockierend" und ist in einem Klick über alle Konten abfragbar. CS Ops übernimmt die Taxonomie-Governance, nicht individuelle CSMs. Neue Taxonomie-Punkte erfordern eine CS Ops-Überprüfung (48-Stunden-SLA) bevor sie aktiv werden. Nicht klassifizierte Punkte werden als „Nicht klassifiziert > [Bereich] > [Schweregrad]" getaggt und monatlich überprüft; drei Erscheinungen desselben nicht klassifizierten Tags lösen einen neuen Taxonomie-Punkt aus.
Wie oft sollten CSM-Syncs auf Mustererkennung statt Kontoüberprüfungen fokussieren?
Die meisten CS-Team-Syncs sind Kontoüberprüfungen, was bedeutet, sie sind darauf ausgelegt, individuelle Kontoprobleme statt kontenübergreifende Muster aufzudecken. Die erforderliche Format-Änderung ist: eine strukturierte Vorab-Lektüre (jeder CSM reicht vor dem Meeting 1-3 Beobachtungen mit einer Vorlage ein) und ein Meeting-Fokus nur auf Überschneidungen. Jedes Thema, das nur in einem CSM-Beitrag erschien, wird offline behandelt. Gemäß diesem Framework produziert ein 30-minütiger Mustererkennungs-Sync mit 100% Vorab-Lektüre-Abschluss bessere Signale als ein 90-minütiges Kontoüberprüfungsmeeting. Wenn der Sync länger als 30 Minuten läuft, werden die Vorab-Lektüren nicht abgeschlossen und das Meeting erledigt die Arbeit, die die Vorab-Lektüren erledigen sollten.
Was ist der CS-Monats-Produktsignal-Digest und was sollte er enthalten?
Der CS-Monats-Produktsignal-Digest ist ein schriftlicher Bericht von CS Ops an das Produktteam, der die 3 häufigsten wiederkehrenden Themen nach Häufigkeit enthält, mit ARR-Kontext, Trendrichtung und wörtlichen Kundenformulierungen für jedes. Er enthält auch neue Signale (Themen, die zum ersten Mal erscheinen) und geschlossene Signale (Themen, die nicht mehr erscheinen, mit Gründen). Das Format schließt mit zwei Aktionsanfragen an das Produktteam: Eingangsbestätigung bis zu einem bestimmten Datum und vorläufige Prioritätsbewertung für das führende Thema innerhalb von fünf Werktagen. Monatlicher Rhythmus übertrifft quartalsweise für schnell agierende Produktteams; die Bestätigung vom Produktteam ist das, was sicherstellt, dass der Digest weiterhin ankommt.
Was passiert mit CSM-Beitragsraten, wenn die Feedback-Schleife nicht geschlossen wird?
CSMs, die kein Feedback zu ihren Musterbeiträgen erhalten, reduzieren ihr Logging-Volumen erheblich. Laut Gainsights CS-Operations-Forschung loggen CSMs, die sehen, dass ihre Beobachtungen den Backlog erreichen, im folgenden Quartal 2-3-mal mehr Beobachtungen als CSMs, die keine Bestätigung erhalten. Das ist kein Motivationsproblem. Es ist rationale Ressourcenzuteilung. Wenn das Loggen Zeit kostet und kein sichtbares Ergebnis produziert, wird die Zeit umverteilt. Der Schleifen-Abschluss-Mechanismus (eine Benachrichtigung von CS Ops, wenn ein Muster zum Backlog-Punkt wird, und eine VP-CS-Notiz, wenn eine mustergetriebene Funktion ausgeliefert wird) ist der operative Input, der Beitragsraten aufrecht erhält.
Wann überwiegt die Beschwerde eines einzelnen High-ARR-Kontos zehn kleine Konten?
Regelmäßig. Ein Enterprise-Konto, das 8% des gesamten ARR repräsentiert und aktiv mit Abwanderung über eine spezifische Produktlücke droht, wird und sollte zehn SMB-Konten mit geringer Reibung überwiegen. Der CSM-Anekdote-zu-Signal-Schwellenwert ist häufigkeitsbasiert für die kontenübergreifende Mustererkennung, aber ARR-Konzentration und Abwanderungsrisiko überschreiben das Häufigkeitsgate in bestimmten Umständen: Jedes einzelne Konto über 5% des gesamten ARR, das ein blockierendes Problem meldet, rechtfertigt direkte Eskalation außerhalb des Standard-Mustererkennungszyklus.

Senior Operations & Growth Strategist
On this page
- Warum Mustererkennung in größerem Maßstab scheitert
- Das Fundament: Eine gemeinsame Feedback-Taxonomie
- Methode 1: Strukturierter CSM-Sync (wöchentlich oder zweiwöchentlich)
- Methode 2: Aggregiertes Feedback-Tagging in der CS-Plattform
- Methode 3: CS-Digest an das Produktteam (schriftlich, nicht mündlich)
- Das Schwellenwertproblem: Wie viele Berichte bilden ein Signal?
- Die Schleife schließen, um Beiträge aufrechtzuerhalten
- Kennzahlen zur Messung der Mustererkennungsgesundheit
- Wie Mustererkennung mit dem breiteren System verbindet
- Mehr erfahren
- Häufig gestellte Fragen
- Was ist der CSM-Anekdote-zu-Signal-Schwellenwert?
- Warum erhalten 71% der Produktmanager individuelle Anekdoten statt aggregierter Muster?
- Was ist eine gemeinsame Feedback-Taxonomie und wie baut man eine auf?
- Wie oft sollten CSM-Syncs auf Mustererkennung statt Kontoüberprüfungen fokussieren?
- Was ist der CS-Monats-Produktsignal-Digest und was sollte er enthalten?
- Was passiert mit CSM-Beitragsraten, wenn die Feedback-Schleife nicht geschlossen wird?
- Wann überwiegt die Beschwerde eines einzelnen High-ARR-Kontos zehn kleine Konten?