Customer-Impact-Scoring: Den Kundenfall für Produktentscheidungen quantifizieren
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ein Backlog-Item sitzt seit drei Quartalen auf Position 14. Achtzehn Accounts haben es markiert. Das PM-Team hat es zur Kenntnis genommen. Niemand hat es bewegt.
Währenddessen steckt ein Feature, das zwei Enterprise-Accounts im letzten Monat in einem QBR angefordert haben, bereits im Sprint. Eine Führungskraft war bei diesem QBR anwesend. Die HiPPO (Meinung der am höchsten bezahlten Person) hat wieder gewonnen.
So sterben Produkt-Backlogs: nicht aus Mangel an Kundenfeedback, sondern aus Mangel an einem wiederholbaren System zu seiner Gewichtung. Ohne ein Scoring-Modell ist jede Priorisierungsentscheidung eine Verhandlung. Das Ergebnis hängt davon ab, wer erschienen ist, wer am lautesten gesprochen hat und wer den größten organisatorischen Einfluss hat.
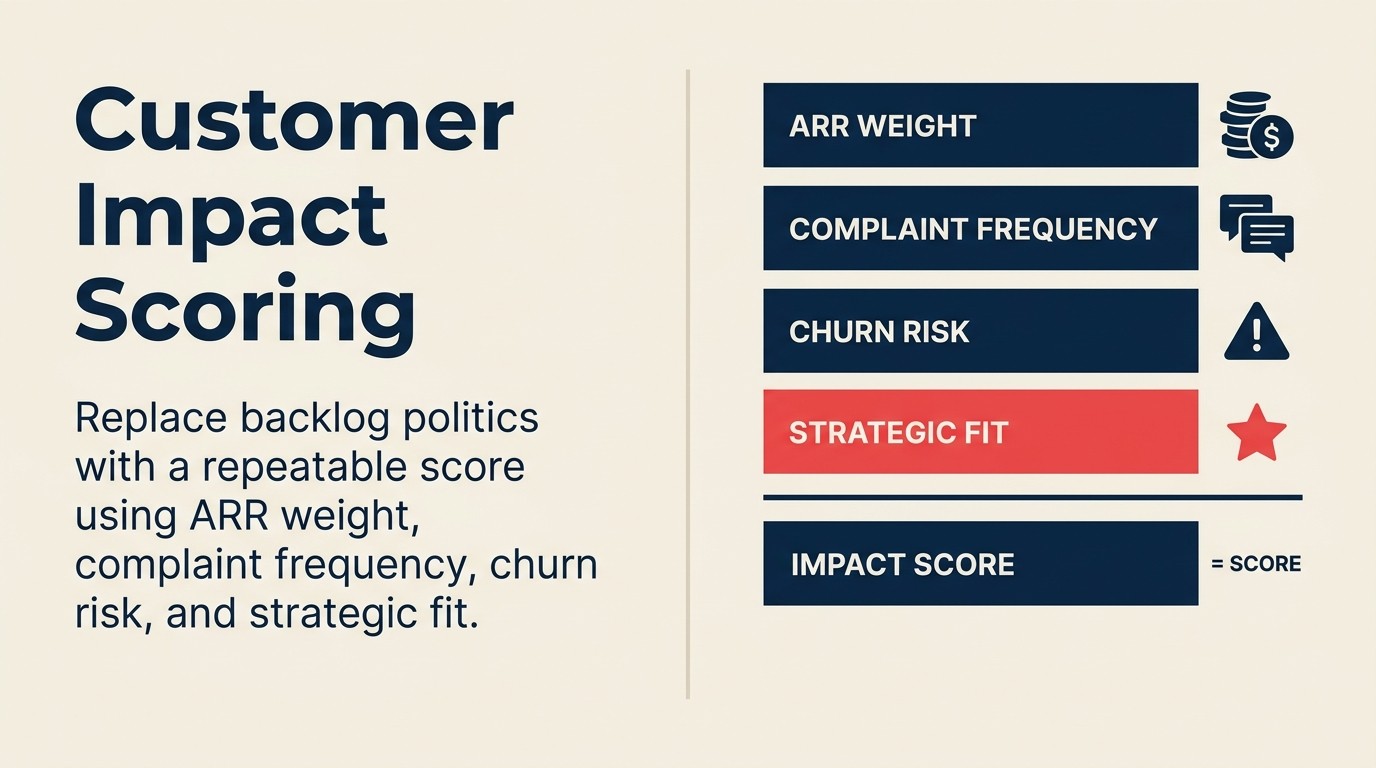
Customer-Impact-Scoring ist das System, das diese Verhandlung durch eine Zahl ersetzt, nicht um das Urteilsvermögen des PM zu entfernen, sondern um dem Urteilsvermögen etwas zu geben, wogegen es sich abstützen kann. HBRs Forschung zum HiPPO-Effekt stellte fest, dass Entscheidungsautorität für strategische Themen regelmäßig zur Meinung der am höchsten bezahlten Person übergeht, und dass Organisationen speziell strukturierten, datengesteuerten Input benötigen, um dieser Tendenz entgegenzuwirken. Das CS-Product-Alignment-Glossar definiert die Schlüsselbegriffe (ARR-Gewichtung, Abwanderungsrisiko-Koeffizient, Strategischer-Account-Flag), sodass CS und Product dasselbe berechnen, wenn sie dasselbe Backlog-Item bewerten.
Der 4-Faktor-Customer-Impact-Score operationalisiert diese Berechnung in eine zusammengesetzte Zahl von 0-100: ARR betroffen (Gewichtung 40 %), Normalisierte Account-Anzahl (25 %), Abwanderungsrisiko-Account-Gewichtung mit einem 2,0-Abwanderungskoeffizient (20 %) und Strategischer-Account-Flag (15 %). Die Gewichtungen summieren sich auf 100 und können nach Geschäftspriorität angepasst werden. Verlagern Sie das Gewicht in kundenbindungsfokussierten Quartalen zur Abwanderungsrisiko-Komponente, in Enterprise-Expansionsphasen zur ARR-Komponente. Dokumentieren Sie die Begründung bei der Festlegung der Gewichtungen, damit das Modell von Quartal zu Quartal nachprüfbar ist.
Warum rohe Beschwerdezahlen versagen
Bevor das Modell aufgebaut wird, ist es hilfreich zu verstehen, warum die häufigste Alternative (Beschwerden zählen) zu schlechter Priorisierung führt. Wikipedia zur Anforderungspriorisierung dokumentiert mehrere strukturierte Scoring-Ansätze (einschließlich des RICE-Modells: Reach × Impact × Confidence ÷ Effort) und gewichtetes Scoring, die genau deshalb existieren, weil rohe Abstimmungszahlen und Bauchgefühl-Rankings systematisch verzerrte Ergebnisse produzieren.
Volumen-Bias: Das Feature, das 50 kleine Kunden wollen, schlägt das Feature, das 3 Enterprise-Kunden brauchen. Wenn Sie nach Account-Volumen zählen, entwickeln Sie für Quantität der Accounts, nicht für Qualität der Umsätze. Eine Funktionsanfrage von 50 Accounts, die 250.000 € ARR repräsentieren, verliert in jedem rationalen Gewichtungsmodell gegen eine Funktionsanfrage von 3 Accounts, die 900.000 € ARR repräsentieren. Aber rohe Zählungen können das nicht erkennen.
Lautsprecher-Bias: Lautstarke Kunden dominieren Feedback-Kanäle. Kunden, die detaillierte Funktionsanfragen schreiben, zu User-Research-Sitzungen erscheinen und auf jede NPS-Umfrage antworten, sind nicht repräsentativ für Ihre Kundenbasis. Sie sind das engagierteste Quartal. Die stillen Abwandernden, die ein Feature aufhören zu nutzen, nichts sagen und bei der Verlängerung kündigen, erscheinen nie in der Beschwerdeanzahl.
Aktualitäts-Bias: Was diesen Monat aufgetaucht ist, wird gegenüber dem chronischen Langzeitproblem priorisiert, das seit acht Monaten gemeldet wird. Das Langzeitproblem hat mehr Gesamtmeldungen. Aber es wurde normalisiert („So funktioniert das Produkt eben"), während die frische Beschwerde dringend wirkt, weil sie neu ist.
Das Scoring-Modell adressiert alle drei Fehlermuster durch Normalisierung nach ARR, separate Gewichtung gefährdeter Accounts gegenüber gesunden Accounts und Betrachtung der kumulativen Frequenz statt der Aktualität.
Wichtige Fakten: Warum die Produktpriorisierung ein Scoring-Modell braucht
- 74 % der Product Manager geben an, dass Kundenfeedback ihre Roadmap beeinflusst, aber nur 31 % haben ein formales System zur Quantifizierung dieses Einflusses. Die übrigen verlassen sich auf qualitative Eindrücke und interne Befürwortung, gemäß einem Pendo-State-of-Product-Leadership-Bericht.
- Features, die mit strukturiertem Customer-Impact-Scoring (einschließlich ARR-Gewichtung, Frequenz und Abwanderungsrisiko) priorisiert wurden, haben 40 % höhere Akzeptanzraten beim Launch als Features, die durch informelle Prozesse priorisiert wurden, gemäß Productboard-Forschung zu product-geführten Unternehmen.
- HiPPO-gesteuerte Priorisierung (Meinung der am höchsten bezahlten Person) beeinflusst Roadmap-Entscheidungen in 58 % der mittelgroßen SaaS-Unternehmen, auch wenn Kundenfeedback-Daten verfügbar sind. Die Lücke ist das Fehlen eines strukturierten Gewichtungsmodells, gemäß dem Product Management Institute.
Die drei Scoring-Philosophien
Bevor das zusammengesetzte Modell aufgebaut wird, ist es wichtig zu verstehen, welche Philosophie jede Komponente widerspiegelt. Teams werden darüber diskutieren, welche „gewinnt", und die Antwort ist, dass keine von ihnen allein gewinnt.
ARR-gewichtetes Scoring priorisiert nach Umsatzauswirkung: Die Summe des ARR aller Accounts, die ein Problem gemeldet haben, bestimmt dessen Score-Gewichtung. Das ist richtig für den Schutz des Topline-Umsatzes und für Roadmaps, die Enterprise-First-Strategien verfolgen. Es ist falsch als einziger Input, weil es SMB-Accounts systematisch unterbewertet, auch wenn SMB ein Wachstumssegment repräsentiert, das das Unternehmen aktiv auszubauen versucht. Customer-Health-Scoring mit Sales-Kontext erklärt, wie Expansions-Pipeline und Verlängerungsrisiko in denselben Account-Datensatz eingeflossen werden, sodass die ARR-Zahl, die CS Ops für das Scoring-Modell abruft, die aktuelle Geschäftsrealität widerspiegelt, nicht einen sechs Monate alten CRM-Snapshot.
Beschwerdehäufigkeits-Scoring priorisiert nach dem Volumen einzigartiger meldender Accounts. Das ist richtig für breite Akzeptanz-Maßnahmen und PLG-Modelle, bei denen die Kennzahl ist, wie viele Kunden das Feature nutzen, nicht wie viel Umsatz sie repräsentieren. Es ist falsch als einziger Input, weil es Umsatzauswirkungen ignoriert und einem 5.000-€-Account dasselbe Gewicht gibt wie einem 200.000-€-Account.
Abwanderungsrisiko-gewichtetes Scoring priorisiert nach Abwanderungsrisikokorrelation. Accounts, die gefährdet sind oder sich in einem Abwanderungsgespräch befinden, erhalten bei der Berechnung des Business Case für ein Feature erhöhtes Gewicht. Das ist richtig für kundenbindungspriorisierte Quartale und Umgebungen mit hoher Abwanderung. Es ist falsch als einziger Input, weil es bedeutet, dass die Roadmap von den am stärksten gefährdeten statt von den wertvollsten Accounts gesteuert wird.
Das zusammengesetzte Modell beinhaltet alle drei. Die Gewichtungen zwischen ihnen sind eine Geschäftsentscheidung, und diese Entscheidung explizit zu machen, hat selbst Wert. Der nächste Abschnitt zeigt genau, wie es berechnet wird.
Den zusammengesetzten Customer-Impact-Score aufbauen
Schritt 1: Die Inputs für jedes Backlog-Item sammeln
Für jedes zu bewertende Item muss CS vier Datenpunkte liefern:
Faktor 1: Betroffener ARR. Die Summe des ARR aller Accounts, die dieses Problem gemeldet oder dieses Feature angefordert haben. Rufen Sie dies aus der CS-Plattform ab, nicht aus dem Gedächtnis. Wenn Sie kein getaggtes Feedback haben, das mit Accounts verknüpft ist, funktioniert dieser Schritt nicht, weshalb die Support-Tickets-zum-Produkt-Backlog-Pipeline und die gemeinsame Feedback-Taxonomie Voraussetzungen sind.
Faktor 2: Account-Anzahl. Die Anzahl der einzigartigen Accounts, die das Problem gemeldet haben, normalisiert auf eine 0-10-Skala basierend auf Ihrer Gesamtzahl an Accounts. Wenn Sie 200 Accounts haben und 20 das Problem markiert haben, ist das eine Penetrationsrate von 10 %. Normalisieren Sie dies, damit Account-Zahlen über Items vergleichbar sind, unabhängig davon, ob die absolute Zahl 5 oder 50 ist.
Faktor 3: Abwanderungsrisiko-Gewichtung. Die Anzahl gefährdeter Accounts (Health Score unter dem Schwellenwert, offenes Abwanderungsgespräch oder Verlängerung innerhalb von 90 Tagen), die das Problem gemeldet haben, multipliziert mit einem Risikokoeffizient. Der Standardkoeffizient ist 2,0. Ein gefährdeter Account zählt im Scoring-Modell doppelt, weil die Geschäftskosten des Verlusts dieses Accounts höher und unmittelbarer sind.
Faktor 4: Strategischer-Account-Flag. Ein binärer Wert: Erscheint ein benannter/strategischer Account in der Liste der betroffenen Accounts? Benannte Accounts sind Accounts, die auf der benannten Account-Liste des Unternehmens erscheinen, typischerweise Accounts mit dem höchsten ARR oder Schlüssel-Logos. Dieser Flag fügt dem Score einen festen Bonus hinzu, weil strategische Accounts über ihren ARR hinaus Beziehungs- und Referenzwert tragen.
Schritt 2: Die Scoring-Formel anwenden
Customer-Impact-Score =
(ARR betroffen / Gesamt-ARR des Unternehmens × 40)
+ (Normalisierte Account-Anzahl × 25)
+ (Gefährdete Accounts × 2,0 × 20 / Maximaler möglicher Gefährdungs-Score)
+ (Strategischer-Account-Flag × 15)
Die Gewichtungen (40/25/20/15) summieren sich auf 100 und können basierend auf der aktuellen strategischen Priorität Ihres Unternehmens angepasst werden. In einem kundenbindungsfokussierten Quartal erhöhen Sie das Abwanderungsrisiko-Gewicht. In einem Enterprise-Expansionsquartal erhöhen Sie das ARR-Gewicht. Dokumentieren Sie die Gewichtungsbegründung bei der Festlegung.
Schritt 3: Durchgerechnetes numerisches Beispiel (4 konkurrierende Backlog-Items)
Unternehmenskontext: Mittelgroßes SaaS-Unternehmen. Gesamt-ARR: 8 Mio. €. Gesamt-Accounts: 180. Benannte Accounts (Top 20 nach ARR): 20 Accounts.
Item A: Massenexport (Zeilenlimiterhöhung)
- Meldende Accounts: 28 einzigartige Accounts
- Betroffener ARR: 840.000 €
- Gefährdete Accounts in der Liste: 4
- Strategischer-Account-Flag: Nein (keine benannten Accounts betroffen)
Bewertung:
- ARR-Komponente: (840.000 € / 8 Mio. €) × 40 = 4,2
- Account-Anzahl-Komponente: 28/180 = 15,6 %, Normalisierung: 15,6/20 × 10 = 7,8 × 25/10 = 19,5
- Abwanderungsrisiko-Komponente: (4 × 2,0) = 8 gewichtete Gefährdungs-Accounts. Max. mögliche Gefährdungs-Accounts = 30 (15 % der Accounts). 8/30 × 20 = 5,3
- Strategischer Flag: 0
Item A Gesamt: 4,2 + 19,5 + 5,3 + 0 = 29,0
Item B: Kalenderintegration (nativer Sync)
- Meldende Accounts: 11 einzigartige Accounts
- Betroffener ARR: 1.320.000 €
- Gefährdete Accounts in der Liste: 1
- Strategischer-Account-Flag: Ja (2 benannte Accounts betroffen)
Bewertung:
- ARR-Komponente: (1,32 Mio. € / 8 Mio. €) × 40 = 6,6
- Account-Anzahl-Komponente: 11/180 = 6,1 %, Normalisierung: 6,1/20 × 10 = 3,1 × 25/10 = 7,6
- Abwanderungsrisiko-Komponente: (1 × 2,0) = 2. 2/30 × 20 = 1,3
- Strategischer Flag: 15
Item B Gesamt: 6,6 + 7,6 + 1,3 + 15 = 30,5
Item C: Mobile App Offline-Modus
- Meldende Accounts: 6 einzigartige Accounts
- Betroffener ARR: 190.000 €
- Gefährdete Accounts in der Liste: 3
- Strategischer-Account-Flag: Nein
Bewertung:
- ARR-Komponente: (190.000 € / 8 Mio. €) × 40 = 0,95
- Account-Anzahl-Komponente: 6/180 = 3,3 %, Normalisierung: 3,3/20 × 10 = 1,7 × 25/10 = 4,1
- Abwanderungsrisiko-Komponente: (3 × 2,0) = 6. 6/30 × 20 = 4,0
- Strategischer Flag: 0
Item C Gesamt: 0,95 + 4,1 + 4,0 + 0 = 9,05
Item D: Benutzerdefinierte Feldtypen (Mehrfachauswahl)
- Meldende Accounts: 41 einzigartige Accounts
- Betroffener ARR: 510.000 €
- Gefährdete Accounts in der Liste: 2
- Strategischer-Account-Flag: Ja (1 benannter Account betroffen)
Bewertung:
- ARR-Komponente: (510.000 € / 8 Mio. €) × 40 = 2,55
- Account-Anzahl-Komponente: 41/180 = 22,8 %, auf max. 20 % gedeckelt → 10 × 25/10 = 25
- Abwanderungsrisiko-Komponente: (2 × 2,0) = 4. 4/30 × 20 = 2,7
- Strategischer Flag: 15
Item D Gesamt: 2,55 + 25 + 2,7 + 15 = 45,25
Zusammengefasste Scores und PM-Empfehlung:
| Backlog-Item | ARR-Komponente | Account-Anzahl | Abwanderungsrisiko | Strategischer Flag | Gesamtscore | PM-Empfehlung |
|---|---|---|---|---|---|---|
| D: Benutzerdefinierte Feldtypen | 2,55 | 25,0 | 2,7 | 15 | 45,25 | Priorität 1: hohes Volumen und strategischer Account-Flag heben dies über Items mit höherem ARR |
| B: Kalenderintegration | 6,6 | 7,6 | 1,3 | 15 | 30,5 | Priorität 2: hoher ARR pro Account und strategischer Flag; relativ geringe Account-Penetration |
| A: Massenexport | 4,2 | 19,5 | 5,3 | 0 | 29,0 | Priorität 3: starke Account-Anzahl und Abwanderungsrisiko-Gewichtung; beobachten, wenn die Gefährdungszahl wächst |
| C: Mobile Offline-Modus | 0,95 | 4,1 | 4,0 | 0 | 9,05 | Priorität 4: kleine Basis; Abwanderungsrisiko-Gewichtung verhindert vollständige Deprioritisierung |
Die Scoring-Erkenntnis: Item D gewinnt nicht, weil es die höchste ARR-Auswirkung hat (Item B hat das) oder das höchste Abwanderungsrisiko-Gewicht (Item A hat das). Es gewinnt, weil es über alle vier Dimensionen hinweg punktet: hohe Account-Penetration, ein benannter Account und genug Abwanderungsrisiko-Gewicht, um zu bestätigen, dass es ein Kundenbindungsrisiko ist, keine reine Funktionsanfrage.
Das ist der Wert des zusammengesetzten Modells: Es erzeugt eine vertretbare Rangordnung, die kein Einzelfaktor-Modell erzeugen könnte.
Wie CS den Score speist
Das Scoring-Modell ist nur so gut wie die Daten, die CS liefert. Für jedes Backlog-Item müssen CSMs folgendes protokollieren:
- Problembeschreibung in der gemeinsamen Taxonomie (kein Freitext)
- Account-Liste: jeder Account, der dieses Problem markiert hat, mit verknüpftem Account-Datensatz
- ARR pro Account (aus dem CRM gezogen, nicht geschätzt)
- Verlängerungsdatum für die drei Accounts mit der nächsten Verlängerung
- Health Score zum Zeitpunkt der Protokollierung
- Jede wörtliche Kundensprache, die für das Product-Team erhaltenswert ist
Wer den Score anreichert: CS Ops, nicht einzelne CSMs. Einzelne CSMs taggen Feedback in der CS-Plattform. CS Ops aggregiert, reichert mit ARR-Daten aus dem CRM an und führt die Scoring-Formel aus. Diese Trennung hält die Daten konsistent und verhindert, dass einzelne CSMs versehentlich Scores für ihre eigenen Accounts aufblähen.
Kadenz: Zweiwöchentliches Batch-Scoring. Echtzeit-Scoring führt zu Rauschen. Ein einzelner neuer Bericht sollte die Prioritäten in einem wöchentlichen Sprint-Zyklus nicht verschieben. Zweiwöchentliches Scoring gibt genug Zeit, damit sich die Daten ansammeln können, bevor sie Roadmap-Diskussionen beeinflussen.
Wie Product den Score nutzt
Wo der Score lebt: Im Produkt-Backlog als benutzerdefiniertes Feld, nicht in einer separaten CS-Tabelle. Wenn der Score in einer Tabelle lebt, wird er gelegentlich referenziert. Wenn es ein Feld im Backlog-Tool ist, ist es jedes Mal sichtbar, wenn ein PM ein Backlog-Item öffnet.
Wie er gegen andere Inputs gewichtet wird: Der Customer-Impact-Score ist ein Input unter mehreren in der Roadmap-Priorisierung. Technische Schulden, strategische Produktwetten, regulatorische Anforderungen und Engineering-Komplexität gehören alle in dasselbe Gespräch. Eine vernünftige Ausgangsgewichtung für den Customer-Impact-Score ist 30-40 % des Gesamtpriorisierungsscores.
Der Score ist ein Multiplikator, kein Mandat: Ein Customer-Impact-Score von 45 bedeutet nicht, dass das Feature im nächsten Sprint ausgeliefert wird. Es bedeutet, dass das Feature einen starken Kundenfall hat, der die Priorisierungsdiskussion beeinflussen sollte. Ein PM, der ein hoch bewertetes Item wegen technischer Randbedingungen oder strategischer Überlegungen übergeht, ignoriert nicht das System. Er nutzt sein Urteilsvermögen, informiert durch das System. Das ist der vorgesehene Gebrauch.
Randfall und Entscheidungshilfen bei Gleichstand
Account mit niedrigem ARR und unverhältnismäßig lauter Stimme: Ein 10.000-€-Account, dessen CSM sehr aktiv und ein guter Schreiber ist, wird natürlich mehr protokolliertes Feedback produzieren als ein 200.000-€-Account mit einer passiveren CSM-Beziehung. Die ARR-Komponente behandelt das automatisch. Das Feedback des niedrig-ARR-Accounts trägt proportional weniger zur ARR-Komponente bei, unabhängig davon, wie oft das Problem protokolliert wird.
Einzelner Enterprise-Account treibt einen Score, der sonst verlieren würde: Das funktioniert wie beabsichtigt, ist kein Fehler. Wenn ein 600.000-€-Account der einzige ist, der ein Problem meldet, und dieser eine Account 7,5 % des Gesamt-ARR repräsentiert, erzeugt die ARR-Komponente allein bereits einen bedeutsamen Score. Fügen Sie einen strategischen Flag hinzu, wenn er ein benannter Account ist, und der zusammengesetzte Score spiegelt seine tatsächliche Geschäftsbedeutung wider.
Gefährdete Accounts wollen alle dasselbe strategiefremde Feature: Bewerten Sie das Item mit dem Modell. Dann überprüft der PM die Empfehlung und trifft ein Urteil: „Dieses Item erzielt 28 primär aufgrund des Abwanderungsrisiko-Gewichts, aber das Feature ist inkonsistent mit unserer aktuellen Produktstrategie. Wir können es nicht entwickeln. Was kann CS tun, um diese Accounts ohne Produktänderung zu halten?" Das ist das richtige Gespräch. Und es ist ein besseres Gespräch als jenes, das mit „Diese Kunden werden abwandern, wenn wir das nicht bauen" beginnt.
Fallstricke: Wie Teams das Modell korrumpieren
McKinseys Forschung zu Top-Product-Managern stellte fest, dass die besten PMs Kundendaten als einen Input unter mehreren behandeln. Sie verwenden Scoring-Modelle, um die Priorisierung zu informieren, nicht um die Urteile zu ersetzen, die strategischen Kontext, technische Machbarkeit und Wettbewerbsbewusstsein erfordern.
CS wählt selektiv aus, welche Accounts einbezogen werden. Wenn CSMs selektiv Feedback von Accounts protokollieren, von denen sie wissen, dass sie einen Score aufblähen, erzeugt das Modell ein verzerrtes Ergebnis. Lösen Sie das strukturell: Alle protokollierten Feedback-Items gehen automatisch in die Aggregation ein. CSMs wählen nicht aus, welche Accounts im Scoring einbezogen werden. Wenn der CSM eines Accounts das Feedback mit der Standard-Taxonomie protokolliert hat, ist es dabei.
Scores werden nicht aktualisiert, wenn sich der Account-Status ändert. Ein Account, der verlängert hat und von gelb auf grün gegangen ist, hat immer noch sein Abwanderungsrisiko-Gewicht von vor sechs Monaten, wenn niemand es aktualisiert. CS Ops sollte eine vierteljährliche Account-Status-Aktualisierung durchführen: Health Scores, Verlängerungszeitpläne und benannten Account-Status für alle Accounts in der Scoring-Datenbank aktualisieren. Die vierteljährliche Kundenfeedback-Überprüfung ist der natürliche Kontrollpunkt für diese Aktualisierung, bei der Product und CS gemeinsam validieren, ob die Scores des letzten Quartals die richtigen Ergebnisse vorhergesagt haben, bevor die Gewichtungen neu kalibriert werden.
Den Score als Ranking-Engine statt als Input behandeln. Das Modell ordnet Backlog-Items nach Kundenauswirkung. Es ordnet nicht nach dem, was als nächstes gebaut werden soll. Engineering-Komplexität, strategische Passung und technische Schulden gehören alle in das Gespräch. Teams, die anfangen, den Customer-Impact-Score als die gesamte Priorisierungsantwort zu behandeln, werden technisch inkohärente Entscheidungen treffen und hoch bewertete Features ausliefern, die in der Zeit, die die Roadmap für sie vorsieht, nicht gebaut werden können.
Wie das mit Mustererkennung und Feedback-Systemen zusammenhängt
Customer-Impact-Scoring ist die Quantifizierungsschicht, die über der Mustererkennung über CSMs hinweg liegt. Mustererkennung identifiziert, dass ein Thema existiert. Fünf CSMs haben die Massenexport-Beschwerde gehört. Customer-Impact-Scoring beantwortet die Geschäftsfrage: Wie viel bedeutet das?
ARR-gewichtete Feedback-Quantifizierung deckt die Finanzmodellierungsschicht detaillierter ab, insbesondere wie die ARR-Auswirkung über verschiedene Account-Größen hinweg normalisiert wird. Das Feature-Request-Friedhof-Problem ist die nachgelagerte Konsequenz eines Backlogs ohne Scoring: Anfragen häufen sich an, nichts wird ausgeliefert, Kunden hören auf einzureichen.
Kundenfeedback ohne Ertrinken priorisieren deckt die Einlass-Filterschicht ab, die sicherstellt, dass nur bewertetes, strukturiertes Feedback überhaupt das Product-Team erreicht. Und die vierteljährliche Kundenfeedback-Überprüfung ist der Ort, an dem das Scoring-Modell gegen tatsächliche Ergebnisse validiert wird: Haben die von uns priorisierten Items die Kundenbindungs- und Akzeptanzergebnisse produziert, die die Scores vorhergesagt haben?
Rework-Analyse: In unserer Analyse mittelständischer SaaS-Priorisierungsmuster ist das häufigste Fehlermuster nicht die Wahl der falschen Scoring-Formel. Es ist die Verwendung des Scores als Ranking-Engine statt als Input. Der 4-Faktor-Customer-Impact-Score ist ein Multiplikator für PM-Urteilsvermögen, kein Ersatz dafür. Teams, die am meisten vom Modell profitieren, führen zweiwöchentliche Scoring-Zyklen durch (nicht in Echtzeit), halten den Score als benutzerdefiniertes Feld direkt im Backlog-Tool (nicht in einer separaten Tabelle) und führen eine vierteljährliche Gewichtungsneukalibrierung durch, bei der sie die Top-bewerteten Items des letzten Quartals mit tatsächlichen Ergebnissen vergleichen. Die Kalibrierungssitzung zeigt typischerweise, ob der Abwanderungsrisiko-Koeffizient (2,0) für das aktuelle Abwanderungsumfeld korrekt skaliert ist. In Quartalen mit hoher Abwanderung kann ein Koeffizient von 2,5-3,0 die tatsächlichen Geschäftskosten des Verlusts gefährdeter Accounts besser widerspiegeln.
Mehr erfahren
- ARR-gewichtetes Feedback: Die Kundenstimme quantifizieren
- Mustererkennung über CSMs hinweg: Das systemische Problem
- Das Feature-Request-Friedhof-Problem
- Kundenfeedback priorisieren (ohne darin zu ertrinken)
- Vierteljährliche Kundenfeedback-Überprüfung (gemeinsam)
Häufig gestellte Fragen
Was ist der 4-Faktor-Customer-Impact-Score?
Der 4-Faktor-Customer-Impact-Score ist ein zusammengesetztes 0-100-Scoring-Modell, das den Kunden-Business-Case für jedes Produkt-Backlog-Item quantifiziert. Die vier Faktoren sind: ARR betroffen (Gewichtung 40 %), Normalisierte Account-Anzahl (Gewichtung 25 %), Abwanderungsrisiko-Account-Gewichtung mit einem 2,0-Abwanderungskoeffizient (Gewichtung 20 %) und Strategischer-Account-Flag, ein binärer Bonus für benannte/Enterprise-Accounts (Gewichtung 15 %). Die Formel lautet: (ARR betroffen / Gesamt-ARR × 40) + (Normalisierte Account-Anzahl × 25) + (Gefährdete Accounts × 2,0 × 20 / Maximaler möglicher Gefährdungs-Score) + (Strategischer-Account-Flag × 15). Gewichtungen summieren sich auf 100 und können nach strategischer Quartalspriorität angepasst werden.
Warum funktionieren rohe Beschwerdeanzahlen nicht für die Produktpriorisierung?
Rohe Zählungen erzeugen drei systematische Verzerrungen. Volumen-Bias: Das Feature, das 50 kleine Kunden wollen, schlägt das Feature, das 3 Enterprise-Kunden brauchen, auch wenn das Enterprise-Feature dreimal den ARR repräsentiert. Lautsprecher-Bias: Kunden, die detaillierte Funktionsanfragen schreiben und auf jede Umfrage antworten, sind das engagierteste Quartal. Sie sind nicht repräsentativ, und die stillen Abwandernden erscheinen nie in den Beschwerdeanzahlen. Aktualitäts-Bias: Was diesen Monat aufgetaucht ist, wird gegenüber dem chronischen Langzeitproblem mit mehr Gesamtberichten über acht Monate priorisiert. Das 4-Faktor-Modell adressiert alle drei durch Normalisierung nach ARR, Anwendung eines Abwanderungskoeffizienten und Betrachtung kumulativer Frequenz statt Aktualität.
Wie funktioniert die Abwanderungsrisiko-Account-Gewichtung im Scoring-Modell?
Gefährdete Accounts (definiert als Accounts mit einem Health Score unter dem Schwellenwert, einem offenen Abwanderungsgespräch oder einer Verlängerung innerhalb von 90 Tagen) erhalten einen 2,0-Abwanderungskoeffizient, wenn sie in der Liste betroffener Accounts erscheinen. Ein gefährdeter Account zählt im Scoring-Modell doppelt, weil die Geschäftskosten des Verlusts dieses Accounts höher und unmittelbarer sind als die Kosten eines gesunden Accounts mit derselben Reibung. Im Rechenbeispiel: Item A (Massenexport) erzielt 5,3 bei der Abwanderungsrisiko-Komponente, weil 4 gefährdete Accounts betroffen sind, jeweils mit 2,0× gegen den maximalen möglichen Gefährdungs-Score von 30. Dieses Abwanderungsrisiko-Gewicht hebt Item A trotz niedrigerem ARR pro Account als Item B auf Priorität 3.
Was ist der Strategische-Account-Flag und wann gilt er?
Der Strategische-Account-Flag ist ein binärer Bonusscore von 15 Punkten, der angewendet wird, wenn mindestens ein benannter/Enterprise-Account in der Liste betroffener Accounts erscheint. Benannte Accounts sind definiert als die Accounts mit dem höchsten ARR des Unternehmens nach einer vorab vereinbarten Anzahl (typischerweise die Top-20-Accounts nach ARR). Der Flag gilt, weil strategische Accounts über ihren ARR-Wert hinaus Beziehungs- und Referenzwert tragen. Im Rechenbeispiel erhalten sowohl Item B als auch Item D den 15-Punkte-Flag. Das ist es, was Item D (benutzerdefinierte Feldtypen) trotz niedrigerer ARR-Auswirkung pro Account als Item B auf Priorität 1 hebt, kombiniert mit seinem hohen Account-Penetrations-Score.
Wie oft sollten Customer-Impact-Scores aktualisiert werden?
Zweiwöchentlich. Echtzeit-Scoring führt zu Rauschen. Ein einzelner neuer Account-Bericht sollte die Prioritäten in einem wöchentlichen Sprint-Zyklus nicht verschieben. Zweiwöchentliches Scoring gibt genug Zeit, damit sich Daten ansammeln können, bevor sie Roadmap-Diskussionen beeinflussen. Zusätzlich sollte CS Ops eine vierteljährliche Account-Status-Aktualisierung durchführen: Health Scores, Verlängerungszeitpläne und benannten Account-Status für alle Accounts in der Scoring-Datenbank aktualisieren. Ein Account, der verlängert hat und von gelb auf grün gegangen ist, hat immer noch sein Abwanderungsrisiko-Gewicht von vor sechs Monaten, wenn niemand es aktualisiert, was einen Score produziert, der das Kundenbindungsrisiko für einen nun stabilen Account überschätzt.
Wie sollten Product-Teams den Customer-Impact-Score gegen andere Priorisierungs-Inputs gewichten?
Eine vernünftige Ausgangsgewichtung für den Customer-Impact-Score ist 30-40 % des Gesamtpriorisierungsscores. Das verbleibende Gewicht deckt technische Schulden, strategische Produktwetten, regulatorische Anforderungen und Engineering-Komplexität ab. Ein Customer-Impact-Score von 45 bedeutet nicht, dass das Feature im nächsten Sprint ausgeliefert wird. Es bedeutet, dass das Feature einen starken Kundenfall hat, der ein prominenter Faktor in der Priorisierungsdiskussion sein sollte. Gemäß McKinseys Forschung zu Top-Product-Managern behandeln Elite-PMs Kundendaten als einen Input unter mehreren und nutzen Scoring-Modelle, um die Priorisierung zu informieren, anstatt die Urteile zu ersetzen, die strategischen Kontext und Bewusstsein für technische Machbarkeit erfordern.

Senior Operations & Growth Strategist
On this page
- Warum rohe Beschwerdezahlen versagen
- Die drei Scoring-Philosophien
- Den zusammengesetzten Customer-Impact-Score aufbauen
- Schritt 1: Die Inputs für jedes Backlog-Item sammeln
- Schritt 2: Die Scoring-Formel anwenden
- Schritt 3: Durchgerechnetes numerisches Beispiel (4 konkurrierende Backlog-Items)
- Wie CS den Score speist
- Wie Product den Score nutzt
- Randfall und Entscheidungshilfen bei Gleichstand
- Fallstricke: Wie Teams das Modell korrumpieren
- Wie das mit Mustererkennung und Feedback-Systemen zusammenhängt
- Mehr erfahren
- Häufig gestellte Fragen
- Was ist der 4-Faktor-Customer-Impact-Score?
- Warum funktionieren rohe Beschwerdeanzahlen nicht für die Produktpriorisierung?
- Wie funktioniert die Abwanderungsrisiko-Account-Gewichtung im Scoring-Modell?
- Was ist der Strategische-Account-Flag und wann gilt er?
- Wie oft sollten Customer-Impact-Scores aktualisiert werden?
- Wie sollten Product-Teams den Customer-Impact-Score gegen andere Priorisierungs-Inputs gewichten?