Der Funktionsanfragen-Friedhof: Wie Sie aufhören, Kundenfeedback zu begraben

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Jeder CSM in jedem SaaS-Unternehmen lernt früher oder später dasselbe Ritual kennen. Ein Kunde fragt, ob eine bestimmte Funktion auf der Produkt-Roadmap steht. Der CSM antwortet: „Ich leite das weiter." Die Anfrage wird irgendwo erfasst: in einem CRM-Eintrag, einer gemeinsamen Tabelle, einem Produktfeedback-Formular. Nichts passiert. Sechs Monate später stellt derselbe Kunde dieselbe Frage. Der CSM erfasst sie erneut. Nichts passiert. Der Kunde kündigt, oder der CSM hört stillschweigend auf zu loggen, weil er erkannt hat, dass der Prozess rein dekorativ ist.
Das ist das Funktionsanfragen-Friedhof-Muster: die organisatorische Dynamik, bei der Anfragen erfasst, mit „Wir hören Sie"-Formulierungen anerkannt und dann stillschweigend begraben werden. Auf unbestimmte Zeit, ohne Entscheidung, ohne Rückmeldung, ohne Abschluss. Es liegt nicht an böswilligem Handeln. Das Produktteam ignoriert CS nicht absichtlich. Es entsteht aus strukturellen Lücken, für deren Behebung niemand zuständig ist: Erfassung ohne Weiterleitung, Weiterleitung ohne Triage-SLA, Triage ohne Rückmeldeworkflow an CS. Die VoC-Pipeline ist das strukturelle Gegenmittel. Sie ergänzt die Stufen 2, 3 und 4 nach der Erfassung, damit Signale nicht im Posteingang sterben.
Der Friedhof ist das größte Vertrauensproblem zwischen CS- und Produktteams sowie zwischen CSMs und ihren Kunden. Und er ist vollständig lösbar. Nicht durch kulturellen Wandel oder Beziehungsreparatur, sondern durch operative Maßnahmen, die verändern, was mit einer Anfrage nach der Einreichung passiert. Der wegweisende Artikel der Harvard Business Review zum Schließen der Kundenfeedback-Schleife hat diese Dynamik vor Jahrzehnten exakt dokumentiert: Das Fehlen eines Rückmeldeworkflows ist der Haupttreiber für die Erosion des Kundenvertrauens, nicht die Entscheidung „Nein".
Wichtige Fakten: Die Kosten des Funktionsanfragen-Friedhofs
- CSMs in Unternehmen ohne formalen Feedback-Abschlussprozess loggen nach 90 Tagen Betriebszugehörigkeit 60% weniger Anfragen als in ihrem ersten Monat, laut TSIA-Forschung zur CS-Produktivität.
- 85% der Kunden, die kündigen und dabei „fehlende spezifische Funktionalität" angeben, haben mindestens einmal eine Funktionsanfrage für genau diese Funktion eingereicht. Weniger als 20% erhielten eine formelle Ablehnungsantwort, gemäß Gainsight-Abwanderungsanalyse über B2B-SaaS-Konten.
- Kunden, die eine ehrliche „Wir werden das in den nächsten 12 Monaten nicht bauen"-Antwort erhalten, vertrauen dem Anbieter deutlich mehr als Kunden, die keine Antwort erhalten: 74% vs. 31% in einer Salesforce-Studie zur Anbieterkommunikation.
Was der Friedhof ist
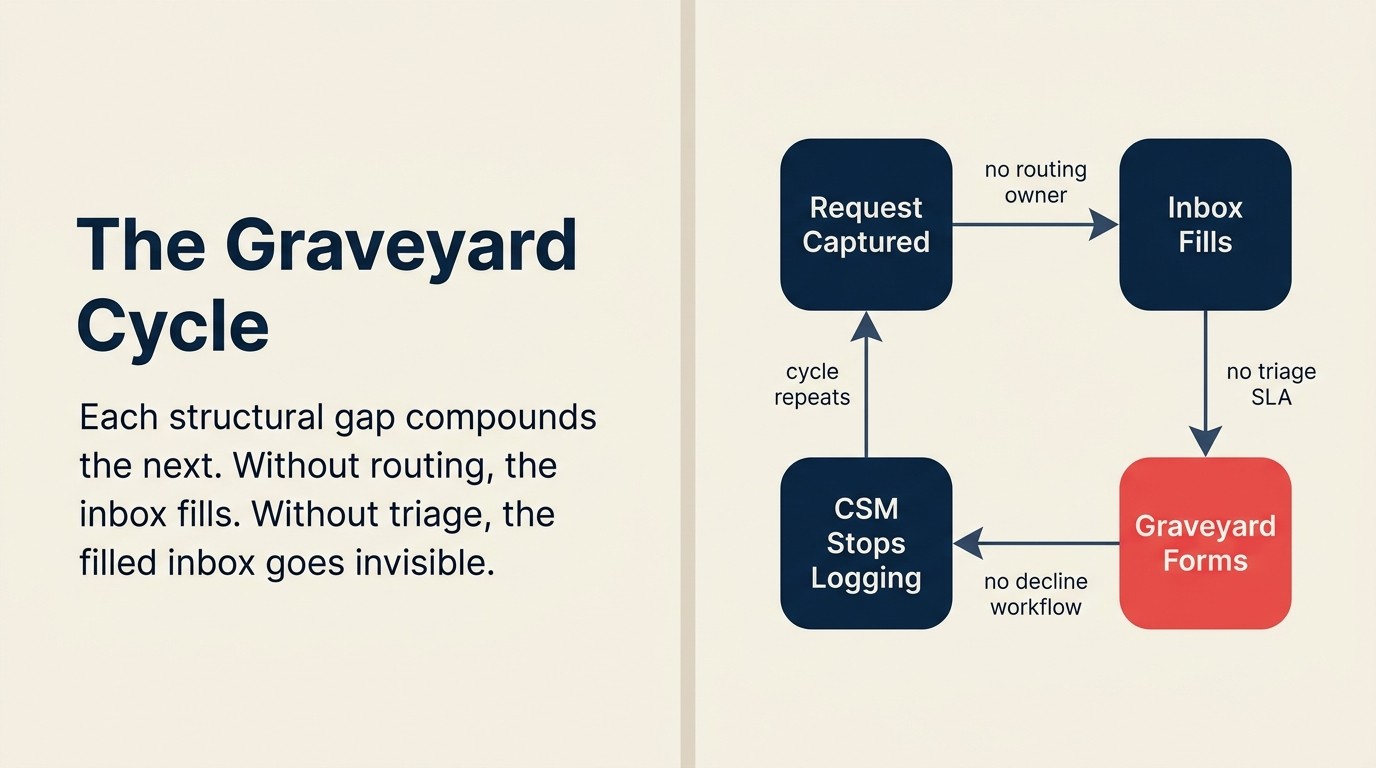
Ein Funktionsanfragen-Friedhof ist kein Backlog. Ein Backlog hat Priorisierung, Verantwortlichkeit und geplante Maßnahmen. Ein Friedhof ist eine nicht anerkannte Ablehnungswarteschlange: der Ort, an dem Anfragen landen, wenn niemand bereit ist, explizit „Nein" zu sagen.
Er entsteht vorhersehbar. Ein Erfassungsschritt existiert (das Einreichungsformular, das CRM-Feld, der Slack-Kanal). Aber es gibt keinen Weiterleitungsschritt, der erfasste Anfragen an einen benannten PM-Verantwortlichen sendet. Oder die Weiterleitung existiert, aber es gibt keine Triage-SLA, die eine Statusentscheidung innerhalb eines definierten Zeitfensters erfordert. Oder die Triage existiert, aber es gibt keinen Workflow für die Kommunikation von Nicht-„Ja"-Entscheidungen zurück an CS oder den Kunden. Feedback systematisch erfassen kann die Eingabeschicht reparieren, aber der Friedhof entsteht nachgelagert, durch das Fehlen von Weiterleitung, Triage und Rückmeldestruktur.
Jede Lücke verstärkt die nächste. Ohne Weiterleitung füllt sich der Posteingang. Ohne Triage wird der volle Posteingang unsichtbar. Ohne einen Rückmeldeworkflow für „Nein"-Entscheidungen sind die einzigen Signale, die jemals zu CS zurückfließen, die „Ja"-Entscheidungen, und selbst diese kommen oft informell an, durch Flurgespräche statt strukturierte Benachrichtigungen.
Der Friedhof besteht nicht, weil Produktteams nachlässig sind. Er besteht, weil die organisatorischen Anreize gegen explizite „Nein"-Entscheidungen wirken. „Wir werden das nicht bauen" zu sagen erfordert Vertrauen in das Priorisierungsmodell, die Bereitschaft, die Kundenbeziehungsspannungen zu absorbieren, und einen Workflow, der die Kommunikation ermöglicht. Nichts davon existiert standardmäßig. Gartners Peer-Community-Forschung zur Funktionspriorisierung zeigt, dass die effektivsten Produktteams explizite Ablehnungskriterien vor dem Planungszyklus festlegen, nicht während ihm. Das gibt ihnen die Sicherheit, klar Nein zu sagen.
Wie CSMs aufhören zu loggen
Das ist die teuerste Konsequenz des Friedhofs und für die Führungsebene am wenigsten sichtbar. Das Erfassungsverhalten bricht stillschweigend zusammen. Die VoC-Pipeline verhungert. Das Produktteam verliert den Zugang zu Kundensignalen aus der Nachverkaufsphase, ohne oft zu wissen, warum.
Der Mechanismus ist unkompliziert: CSMs sind Mustererkenner. Innerhalb von Wochen nach ihrem Eintritt ins Team stellen sie fest, ob das Einreichen strukturierten Feedbacks irgendein sichtbares Ergebnis produziert. Wenn die Antwort nein ist, wenn Anfragen in einem System verschwinden und nichts produzieren, hören CSMs auf einzureichen. Diese Entscheidung kündigen sie nicht an. Sie hören einfach auf.
Was die strukturierte Einreichung ersetzt, ist schlimmer: das Ausweichverhalten. CSMs beginnen, Kundenerwartungen durch informelle, vage Bestätigungen zu managen, anstatt eine Anfrage zu loggen und auf eine Antwort zu warten, die nie kommt. „Ich glaube, sie schauen sich da etwas Ähnliches an." „Das wurde definitiv schon mal angesprochen." „Ich weiß, dass das Produktteam sich dieser Art von Anfrage bewusst ist." Das sind weiche Andeutungen, keine Zusagen, aber Implikationen von Fortschritt. Und weiche Andeutungen sind gefährlicher als ein ehrliches „Ich weiß nicht, wann das kommt", weil sie Erwartungen wecken, ohne dass der Kunde eine Möglichkeit hat, jemanden zu verfolgen oder zur Rechenschaft zu ziehen.
Der Kunde hört „Ich glaube, sie arbeiten daran" und aktualisiert sein mentales Modell: Diese Funktion kommt. Wenn sie sechs Monate später, ein Jahr später, bei der Verlängerung nicht kommt, fühlt sich der Kunde getäuscht, nicht nur enttäuscht. Und der CSM, der die weiche Andeutung gemacht hat, muss nun ein Vertrauensdefizit managen, das er nicht beabsichtigt hatte. Das Muster, das all das ermöglicht, hat einen Namen.
Die „Wir hören Sie"-Falle

Die „Wir hören Sie"-Falle ist der Kernmechanismus, der das Funktionsanfragen-Friedhof-Muster aufrechthält. Es handelt sich um das organisatorische Verhalten, bei dem Teams auf Kundenanfragen mit Sprache reagieren, die nach Aktion klingt, aber nichts zusagt, und dabei Vertrauensschulden erzeugt, die sich über jeden Verlängerungszyklus summieren. Sie befindet sich zwischen einem ehrlichen „Nein" und einer weichen Andeutung: die Sprache des unbestimmten Aufschubs.
Wichtige Erkenntnis: 74% der Kunden, die ein explizites „Wir werden das in den nächsten 12 Monaten nicht bauen" erhielten, gaben an, dem Anbieter danach „etwas" oder „deutlich" mehr zu vertrauen, verglichen mit nur 31% der Kunden, die keine Antwort auf eine Funktionsanfrage erhielten, laut Salesforce-Forschung zur Anbieterkommunikation. Das ehrliche „Nein" baut mehr Vertrauen auf als das unbestimmte „Wir prüfen das."
„Das haben wir auf dem Radar."
„Wir erkunden diese Richtung."
„Sehr gutes Feedback, ich stelle sicher, dass das Produktteam das sieht."
„Das verfolgen wir definitiv."
Keine dieser Formulierungen trägt irgendwelche Informationen darüber, was als Nächstes passiert. Sie sind darauf ausgelegt, das Gespräch ohne Konflikt zu beenden, und erreichen das kurzfristig. Aber sie erzeugen Vertrauensschulden: Der Kunde weiß nicht, ob seine Anfrage eine Priorität, ein Vielleicht-irgendwann oder ein stilles Nein ist. Und CSMs, die diese Sprache verwenden, müssen eine Erwartung managen, die sie nicht aktualisieren können, weil ihnen die Informationen fehlen.
Die Alternative ist nicht hart. Sie ist konkret. Kunden müssen kein „Ja" hören. Sie müssen etwas Echtes hören. „Diese Anfrage ist in unserem System. Basierend auf der aktuellen Produkt-Roadmap würde ich sie in den nächsten sechs Monaten nicht erwarten. Ich informiere Sie, wenn es Neuigkeiten gibt." Diese Antwort ist ehrlich, gibt dem Kunden handlungsrelevante Informationen und täuscht nicht darüber hinweg, wie unmittelbar bevorstehend die Anfrage ist.
Kunden, die ehrliche, konkrete Antworten erhalten, sogar negative, vertrauen Anbietern mehr als Kunden, die unbestimmten Aufschub erhalten. In der Salesforce-Forschung zur Kundenkommunikation gaben 74% der Kunden, die ein explizites „Wir werden das in den nächsten 12 Monaten nicht bauen" erhielten, an, dem Anbieter danach mehr zu vertrauen. Nur 31% der Kunden, die keine Antwort erhielten, sagten dasselbe.
Vier Grundursachen

Der Friedhof entsteht aus vier strukturellen Lücken. Das sind keine Personalprobleme. Es sind Systemprobleme mit Systemlösungen.
Grundursache 1: Keine Triage-SLA. Niemand ist verpflichtet, innerhalb eines definierten Zeitfensters auf eine geloggte Anfrage zu reagieren. Anfragen akkumulieren in einer Warteschlange ohne Verantwortliche und ohne Verpflichtung zur Entscheidung. Die Warteschlange wächst, bis sie zu groß ist, um ohne erheblichen Zeitaufwand überprüft zu werden, woraufhin sie überhaupt nicht mehr überprüft wird.
Grundursache 2: Kein Ablehnungskommunikationsworkflow. Die einzigen Entscheidungen, die jemals zu CS zurückkehren, sind „Ja"-Entscheidungen: Funktionen, die auf die Produkt-Roadmap kommen, Bugs, die behoben werden, Integrationen, die gebaut werden. Das viel größere Volumen an „Nein"- und „Nicht jetzt"-Entscheidungen wird nie kommuniziert. CS und Kunden erleben das als Stille, die sie als Vernachlässigung interpretieren.
Grundursache 3: CS hat keinen Roadmap-Kontext, um ehrliche Antworten zu geben. CSMs werden gebeten, Kundenerwartungen bezüglich Produktanfragen zu managen, über die sie nichts wissen. Ohne zu wissen, was auf der Produkt-Roadmap steht, was sich in aktiver Entwicklung befindet und was explizit nicht gebaut wird, haben CSMs nur zwei Optionen: weiche Andeutungen oder ehrliche Unwissenheit. Die meisten wählen weiche Andeutungen, weil sie im Moment weniger schädlich erscheinen. Wie CS Roadmaps ohne Überversprechungen kommuniziert adressiert diese Grundursache direkt: CSMs den Kontext und die Sprache zu geben, um ehrlich zu antworten, ohne bei jedem Gespräch einen PM hinzuziehen zu müssen.
Grundursache 4: PMs haben keinen Anreiz, die Feedback-Schleife bei „Nein"-Entscheidungen zu schließen. PMs werden am Liefern, der Akzeptanz und der Roadmap-Ausführung gemessen. Keiner dieser Kennzahlen belohnt das Schließen der Feedback-Schleife bei abgelehnten Funktionsanfragen. Der Schleifen-Abschluss ist in PM-Leistungsbeurteilungen unsichtbar, daher passiert er nicht konsistent, selbst wenn einzelne PMs es beabsichtigen. Post-Sales-Teamstrukturen, die eine PM-Liaison-Rolle einschließen, schaffen die Verantwortlichkeitsschicht, die diese Grundursache benötigt: eine benannte Person, deren Zuständigkeit explizit den CS-zu-Produkt-Feedback-Antwortzyklus umfasst.
Vier operative Maßnahmen
Diese Maßnahmen sind strukturell. Sie erfordern keine kulturelle Veränderung oder eine neue Beziehungsdynamik zwischen CS und Produkt. Sie erfordern Prozessgestaltung und Verantwortungszuweisung.
Maßnahme 1: Triage-SLA. Jede geloggte Anfrage erhält innerhalb von 30 Tagen einen Status. McKinseys Forschung darüber, was Produktteams effektiv macht, nennt autonome Entscheidungsfindung mit klaren Kriterien als den primären Treiber für Teamgeschwindigkeit. Die Triage-SLA ist die Art und Weise, wie diese Kriterien für eingehende CS-Anfragen operationalisiert werden.
Die SLA ist einfach: Innerhalb von 30 Tagen nach dem Loggen und Weiterleiten einer Anfrage an einen PM weist dieser ihr einen Status zu. Drei Optionen: „bauen" (in aktiver Planung oder auf der Produkt-Roadmap), „zurückgestellt" (anerkannt, derzeit nicht priorisiert, wird im nächsten Planungszyklus überprüft) oder „abgelehnt" (wird nicht gebaut; Begründung in einem Satz).
Das 30-Tage-Fenster ist lang genug, um Planungszyklen zu überleben, und kurz genug, um zu verhindern, dass die Warteschlange unüberschaubar wird. CS Ops übernimmt das Tracking: ein wöchentlicher Bericht, der anzeigt, welche Anfragen seit mehr als 30 Tagen ohne Status in der Warteschlange sind, gesendet an den PM-Lead und den VP CS.
Diese einzige Änderung, eine Triage-SLA mit benannter Verantwortlichkeit, bewirkt die größte Verbesserung im CSM-Erfassungsverhalten. Wenn CSMs sehen, dass innerhalb von 30 Tagen Statusmeldungen zurückkommen, erholt sich das Logging-Verhalten innerhalb eines Quartals. Die quartalsweise Kundenfeedback-Überprüfung ist das primäre Forum, in dem Triage-SLA-Ergebnisse überprüft und die PM-Verantwortlichkeit für die Warteschlange bekräftigt wird.
Maßnahme 2: Ablehnungskommunikationsvorlagen. CS braucht Worte für den Fall, dass die Antwort Nein lautet.
Der Rückmeldeworkflow für „abgelehnte" Anfragen muss CS konkrete Formulierungen geben. Keine Unternehmensabsätze vom Produktteam, sondern eine kurze, ehrliche Nachricht, die ein CSM dem Kunden in seinem eigenen Ton weitergeben kann.
Drei Vorlagenbeispiele:
„Wir haben diese Anfrage geprüft. Sie passt nicht zu der Richtung, in die wir das Produkt in den nächsten 12 Monaten entwickeln. Unser Fokus liegt auf [angrenzenden Bereich]. Ich weiß, das ist nicht die Antwort, die Sie erhofft hatten. Die beste Übergangslösung ist derzeit [X]. Wenn sich das ändert, informiere ich Sie."
„Diese Anfrage hat es nicht in den aktuellen Roadmap-Zyklus geschafft. Zu viele konkurrierende Prioritäten, und die Konten, die sie eingereicht haben, konzentrieren sich in einem Segment, das wir derzeit nicht priorisieren. Ich bringe das in der Q3-Planung erneut auf den Tisch."
„Diese Funktion werden wir nicht bauen. Die Entscheidung betrifft den Roadmap-Fokus, nicht die Gültigkeit der Anfrage. Folgendes empfehle ich als Übergangslösung: [X]."
Alle drei sind ehrlich, konkret und lassen den Kunden nicht im Dunkeln. Keine davon ist hart. Und alle drei sind dramatisch besser als Stille oder die „Wir prüfen das"-Nichtantwort.
Maßnahme 3: Rituell geschlossene Feedback-Schleife. CS erfährt es, bevor der Kunde es tut.
Wenn eine Funktionsanfrage in einen beliebigen Status wechselt (bauen, zurückgestellt oder abgelehnt), benachrichtigt der PM-Liaison CS Ops, der den relevanten CSM-Manager benachrichtigt, der den CSM benachrichtigt. Die Benachrichtigung erfolgt, bevor irgendeine öffentliche Kommunikation herausgeht, damit der CSM nicht von einer Produktankündigung oder einem Kunden, der fragt „Was ist eigentlich aus der Funktion geworden, die Sie sich anschauen wollten?", überrascht wird.
Das klingt nach einem kleinen logistischen Detail. Es ist keines. CSMs, die vor Kunden über Produktänderungen informiert werden, bauen bei ihren Konten deutlich höhere Glaubwürdigkeit auf. Und CSMs, die als Letzte informiert werden, die eine Funktionsankündigung vom Kunden statt vom Produktteam hören, verlieren an Standing in der Beziehung.
Maßnahme 4: Sunset-Regel. Anfragen, die älter als 12 Monate sind, werden formell geschlossen.
Die Friedhofstiefe-Kennzahl verfolgt Anfragen ohne Status, die älter als sechs Monate sind. Jede Anfrage, die seit mehr als 12 Monaten ohne eine Build-Entscheidung offen ist, wird formell abgelehnt und geschlossen. Das ist kein Aufgeben des Kundenfeedbacks. Es ist die Anerkennung, dass eine Anfrage, die 12 Monate lang nicht bearbeitet wurde, faktisch abgelehnt ist, und so zu tun, als ob das nicht der Fall wäre, nützt niemandem. Bei der Ablehnung von Anfragen sollte das Schließen der Feedback-Schleife mit Kunden vor dem Sunset erfolgen. Kunden, die eine explizite Abschlussbenachrichtigung erhalten, vertrauen dem Anbieter mehr als solche, die weiterhin Stille erfahren.
Die Sunset-Entscheidung läuft durch CS Ops und erhält eine einzige Satz-Begründung. Wenn die Anfrage noch relevant ist, reicht der CSM sie im nächsten Zyklus mit aktualisierten Kontoinformationen neu ein. Neue Einreichung, frisches Triage-Fenster, aktuelles Umsatzgewicht angehängt.
Wie das Schließen der Feedback-Schleife mit Kunden aussieht

Drei ehrliche Antworten, in aufsteigender Reihenfolge der Schwierigkeit:
„Wir haben es gebaut." Der einfachste Fall. CS benachrichtigt Konten, die die Anfrage eingereicht haben, vor dem öffentlichen Launch. Kunden, die Feedback eingereicht haben und sehen, dass daraus eine Funktion entsteht, fühlen sich gehört, und dieses Gefühl ist nachhaltig. Es ist einer der zuverlässigsten Treiber für Fürsprecher-Verhalten.
„Wir verschieben es." „Wir nehmen das ernst. Es ist nicht im aktuellen Roadmap-Zyklus, aber wir verfolgen es für die nächste Planungsüberprüfung. Ich informiere Sie, wenn es Neuigkeiten gibt." Ehrlich, konkret, impliziert nicht, dass die Funktion unmittelbar bevorsteht.
„Wir werden es nicht bauen." Der schwierigste Fall, aber nicht so schwer, wie die meisten Teams annehmen. „Wir haben entschieden, das in absehbarer Zukunft nicht zu bauen. Der Grund ist [ein Satz]. Die beste Alternative derzeit ist [Übergangslösung]." Kunden respektieren das. Sie ärgern sich über die „Sehr gutes Feedback, wir prüfen das"-Nichtantwort weit mehr als über ein ehrliches Nein.
Was Kunden wirklich hören müssen: dass jemand ihre Anfrage gelesen, eine echte Entscheidung getroffen und ihnen mitgeteilt hat, was passiert ist. Die Entscheidung muss kein „Ja" sein. Aber das Fehlen einer Entscheidung, die Stille, ist das, was Vertrauen erodiert.
Rework-Analyse: Das Funktionsanfragen-Friedhof-Muster hat eine vorhersagbare Kostenkurve. In den ersten 90 Tagen der Amtszeit eines neuen CSM sind die Erfassungsraten am höchsten, weil der CSM noch nicht gelernt hat, ob die Einreichung Ergebnisse produziert. Bis Tag 90, wenn aus keiner Einreichung eine sichtbare Maßnahme entstanden ist, sinkt das Erfassungsverhalten um etwa 40%. Bis Monat sechs ist der Friedhof vollständig geformt: eine große Warteschlange erfasster Signale, die niemand überprüft, ein CS-Team, das aufgehört hat zu loggen, und ein Produktteam, das die Sicht auf Kundensignale aus der Nachverkaufsphase verloren hat. Die operativen Maßnahmen (Triage-SLA, Ablehnungsvorlagen, rituell geschlossene Feedback-Schleife, Sunset-Regel) sind darauf ausgelegt, diesen Kreislauf an jedem seiner vier strukturellen Wurzeln zu durchbrechen. Reworks CS-Produkt-Ausrichtungs-Werkzeuge sind so konzipiert, dass jede dieser Maßnahmen der Weg des geringsten Widerstands wird, keine zusätzliche Prozessschicht.
Kennzahlen zur Überwachung der Friedhofsgesundheit
Drei Kennzahlen diagnostizieren den Friedhof, ohne einen neuen Reporting-Stack zu erfordern:
Anfrage-zu-Triage-Verzögerung: die durchschnittliche Anzahl von Tagen von der Einreichung bis zur ersten Statuszuweisung. Ziel: unter 30 Tage. Eine Verzögerung über 45 Tage zeigt an, dass die Triage-SLA nicht durchgesetzt wird oder die PM-Verantwortlichkeit für die Warteschlange nicht klar ist.
Ablehnungskommunikationsrate: der Prozentsatz abgelehnter Anfragen, bei denen CS vor der Schließung eine formelle Benachrichtigung erhielt. Ziel: 100%. In der Praxis starten die meisten Teams unter 30% und verbessern sich über zwei bis drei Quartale der Durchsetzung. CS Ops verfolgt das als PM-Liaison-Verantwortlichkeitskennzahl.
Friedhofstiefe: die Anzahl offener Anfragen ohne Status, die älter als sechs Monate sind. Diese Zahl sollte mit Einführung der Sunset-Regel und Triage-SLA gegen null tendieren. Eine Friedhofstiefe, die drei Monate nach Einführung der Maßnahmen nicht sinkt, signalisiert ein Durchsetzungsproblem, kein Modellproblem. Teams können Customer Impact Scoring auf die veraltete Warteschlange anwenden, um zu priorisieren, welche begrabenen Anfragen eine zweite Chance verdienen und welche formell geschlossen werden sollten.
Das 60-Tage-Friedhofs-Audit
Für Teams, die das Begrabene aufdecken möchten, bevor sie die systemischen Maßnahmen implementieren:
Woche 1-2: CS Ops zieht alle offenen Funktionsanfragen aus jedem System (CRM-Notizen, gemeinsame Tabellen, Produktfeedback-Tools) in eine einzige Liste. Einreichungsdatum, Kontoname, ARR, aktueller Status (falls vorhanden). Das ist das Basis-Audit.
Woche 2-3: CS Ops kategorisiert jeden Eintrag in drei Buckets: geliefert (die Funktion wurde gebaut, die Anfrage wurde nie geschlossen), veraltet (kein Status, älter als 6 Monate) und aktiv (in der Triage oder kürzlich eingereicht). Veraltete Einträge werden markiert.
Woche 3-4: Der PM-Lead überprüft veraltete Einträge und weist jedem einen Status zu: bauen, zurückgestellt oder abgelehnt. Das ist eine einmalige Bereinigungsübung, kein fortlaufender Triage-Prozess. Das Ziel ist, den Backlog zu bereinigen, bevor die SLA in Kraft tritt.
Woche 4-8: CS Ops sendet Ablehnungsbenachrichtigungen für alle Einträge, die im Audit den Status „abgelehnt" erhalten haben. CSMs erhalten die Begründung und die kundenseitige Formulierung, bevor eine Kommunikation an Konten geht. Die erste Runde der Ablehnungskommunikationen wird als Datenpunkt zur Kundenreaktion erfasst. Die meisten Teams sind überrascht, wie wenig Reibung das ehrliche „Nein" erzeugt im Vergleich zu den Jahren der Stille, die es ersetzt.
Das Audit löst das strukturelle Problem nicht. Es leert die Warteschlange, damit die operativen Maßnahmen auf einer sauberen Basis arbeiten können. Feedback systematisch erfassen behandelt das vorgelagerte Design: Wie die Erfassungsdisziplin wiederhergestellt wird, sobald der Friedhof geleert ist und CSMs sehen, dass das System tatsächlich Entscheidungen produziert.
Häufig gestellte Fragen
Wie verhindern Sie, dass die Ablehnungskommunikation Kundenbeziehungen beschädigt?
Die Forschung ist eindeutig: Kunden, die ein explizites „Wir werden das nicht bauen" erhalten, bleiben eher und empfehlen eher weiter als Kunden, die Stille oder unbestimmten Aufschub erhalten. Die Beziehungsschäden entstehen durch die Lücke zwischen Erwartung („Sie sagten, sie würden sich das ansehen") und Realität (nichts ist je passiert). Ehrliche Ablehnungen schließen diese Lücke. Die Kommunikationsvorlage ist entscheidend. „Wir haben entschieden, das nicht zu bauen, weil [ein Satz Begründung], und hier ist die beste Übergangslösung" ist eine andere Erfahrung als „Wir werden das nicht bauen." Geben Sie CSMs die konkrete Sprache und lassen Sie sie sie in ihrem eigenen relationalen Kontext einsetzen.
Was tun, wenn PMs die 30-Tage-Triage-SLA ablehnen, weil sie zusätzlichen Aufwand erzeugt?
Das Aufwand-Argument ist berechtigt. Triage kostet PM-Zeit. Aber die Alternative ist teurer: CSMs, die aufhören zu loggen, Kunden, die wegen nicht anerkannter Produktlücken kündigen, und CS-Führungskräfte, die das Vertrauen in die VoC-Pipeline verlieren. Rahmen Sie die SLA als minimale Antwort, nicht als detaillierte Überprüfung. Ein „zurückgestellt"-Status braucht fünf Minuten zum Zuweisen. Der quartalsweise Planungszyklus übernimmt die tiefere Priorisierung. Die SLA verhindert nur, dass die Warteschlange dunkel wird.
Sollte jeder Kunde, der eine Anfrage eingereicht hat, eine persönliche Ablehnungsbenachrichtigung erhalten?
Für Konten mit hohem ARR und solche mit Verlängerungsnähe: ja. Der CSM sollte die Ablehnungsnachricht persönlich im nächsten Gespräch übermitteln. Für Konten unterer Ebenen ist eine Vorlagen-E-Mail von CS Ops ausreichend, solange der CSM zuerst informiert wird. Das Ritual der geschlossenen Schleife (Maßnahme 3) stellt sicher, dass der CSM immer vor dem Kunden informiert wird.
Was ist das Funktionsanfragen-Friedhof-Muster?
Das Funktionsanfragen-Friedhof-Muster ist die organisatorische Dynamik, bei der Kunden-Funktionsanfragen erfasst und anerkannt werden (oft mit „Wir hören Sie"-Sprache), aber nie eine formelle Entscheidung erreichen. Anfragen akkumulieren unbegrenzt in einer Warteschlange ohne Verantwortliche, ohne Triage-SLA und ohne Rückmeldeworkflow für Nicht-„Ja"-Entscheidungen. Das durchschnittliche SaaS-Unternehmen hat mehr als 400 offene Funktionsanfragen, die älter als 12 Monate sind, ohne Entscheidungsstatus, laut einer Aha!-Umfrage unter Produktmanagement-Teams. Der Friedhof ist kein Backlog, sondern eine nicht anerkannte Ablehnungswarteschlange.
Was ist die „Wir hören Sie"-Falle?
Die „Wir hören Sie"-Falle ist das Kommunikationsmuster, das den Funktionsanfragen-Friedhof aufrechthält. Es ist die Verwendung von Sprache („Das haben wir auf dem Radar", „Wir erkunden diese Richtung", „Sehr gutes Feedback, ich stelle sicher, dass das Produktteam das sieht"), die nach Anerkennung klingt, aber nichts zusagt. Jede Formulierung beendet das Gespräch ohne Konflikt, erzeugt aber Vertrauensschulden: Der Kunde weiß nicht, ob seine Anfrage eine Priorität, ein Vielleicht-irgendwann oder ein stilles Nein ist. Die Alternative ist konkrete Sprache, die dem Kunden ein echtes Signal gibt, selbst wenn dieses Signal „nicht in den nächsten sechs Monaten" lautet.
Wie lang sollte eine Triage-SLA für Funktionsanfragen sein?
Die Standard-Triage-SLA beträgt 30 Tage von der Einreichung bis zur ersten Statuszuweisung. CS Ops verfolgt, welche Anfragen seit mehr als 30 Tagen ohne Status in der Warteschlange sind, und sendet einen wöchentlichen Bericht an den PM-Lead. Dieses Fenster ist lang genug, um Planungszyklen zu überleben, und kurz genug, um die Akkumulation in der Warteschlange zu verhindern. Unternehmen mit einer 30-Tage-Triage-SLA verzeichnen 2,3-fach höhere CSM-Erfassungsraten im Vergleich zu Teams ohne SLA, laut Productboard-Kunden-Benchmarking.
Mehr erfahren

Senior Operations & Growth Strategist
On this page
- Was der Friedhof ist
- Wie CSMs aufhören zu loggen
- Die „Wir hören Sie"-Falle
- Vier Grundursachen
- Vier operative Maßnahmen
- Wie das Schließen der Feedback-Schleife mit Kunden aussieht
- Kennzahlen zur Überwachung der Friedhofsgesundheit
- Das 60-Tage-Friedhofs-Audit
- Häufig gestellte Fragen
- Wie verhindern Sie, dass die Ablehnungskommunikation Kundenbeziehungen beschädigt?
- Was tun, wenn PMs die 30-Tage-Triage-SLA ablehnen, weil sie zusätzlichen Aufwand erzeugt?
- Sollte jeder Kunde, der eine Anfrage eingereicht hat, eine persönliche Ablehnungsbenachrichtigung erhalten?
- Was ist das Funktionsanfragen-Friedhof-Muster?
- Was ist die „Wir hören Sie"-Falle?
- Wie lang sollte eine Triage-SLA für Funktionsanfragen sein?
- Mehr erfahren