Bahasa Indonesia
Customer-Impact Scoring: Cara Mengkuantifikasi Kasus Pelanggan untuk Keputusan Produk
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ada item backlog yang sudah berada di posisi 14 selama tiga kuartal. Delapan belas akun telah menandainya. Tim PM telah mengakuinya. Tidak ada yang memindahkannya.
Sementara itu, fitur yang diminta dua akun enterprise dalam QBR bulan lalu kini sudah masuk sprint. Seorang eksekutif hadir dalam QBR itu. HiPPO (pendapat orang dengan bayaran tertinggi) menang lagi.
Beginilah cara backlog produk mati: bukan karena kurangnya feedback pelanggan, tetapi karena kurangnya sistem yang dapat diulang untuk menimbangnya. Tanpa model penilaian, setiap keputusan penentuan prioritas adalah negosiasi. Hasilnya bergantung pada siapa yang hadir, siapa yang bersuara paling keras, dan siapa yang memiliki pengaruh organisasi terbesar.
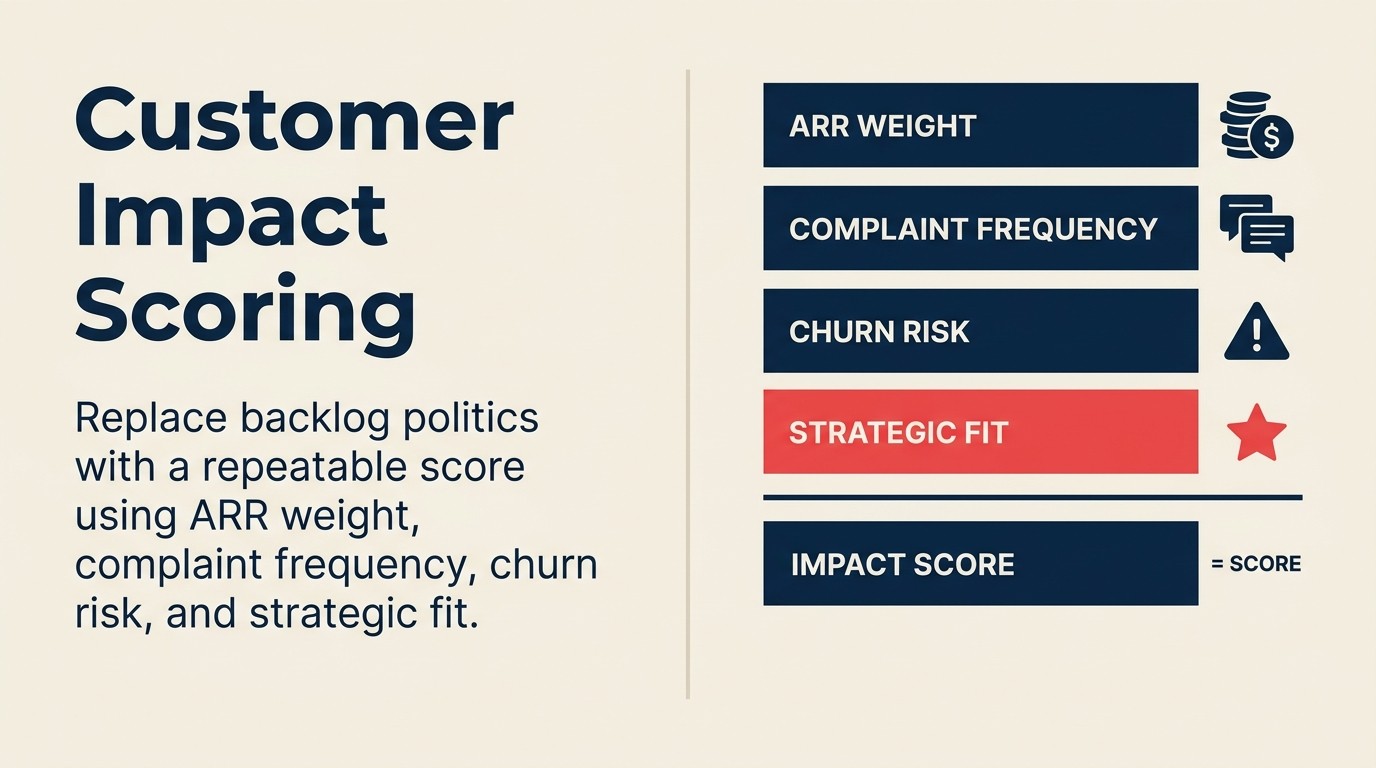
Customer-impact scoring adalah sistem yang menggantikan negosiasi tersebut dengan sebuah angka, bukan untuk menghilangkan pertimbangan PM, tetapi untuk memberi pertimbangan sesuatu yang bisa dijadikan pijakan. Riset HBR tentang efek HiPPO menemukan bahwa otoritas untuk keputusan strategis secara rutin default ke pendapat orang dengan bayaran tertinggi, dan organisasi membutuhkan masukan crowd-sourced atau berbasis data secara khusus untuk melawan kecenderungan itu. Glosarium CS-product alignment mendefinisikan istilah-istilah kunci (bobot ARR, koefisien risiko perpindahan, flag akun strategis) sehingga CS dan product menghitung hal yang sama ketika menilai item backlog yang sama.
4-Factor Customer Impact Score mengoperasionalkan kalkulasi tersebut menjadi angka komposit berkisar 0-100: ARR yang Terdampak (bobot 40%), Jumlah Akun yang Dinormalisasi (25%), Bobot Akun Berisiko dengan koefisien perpindahan 2,0 (20%), dan Flag Akun Strategis (15%). Bobot-bobot tersebut berjumlah 100 dan dapat disesuaikan berdasarkan prioritas bisnis. Geser bobot ke arah risiko perpindahan di kuartal yang berfokus pada retensi, ke arah ARR dalam strategi ekspansi enterprise. Dokumentasikan alasan saat Anda menetapkan bobot agar model dapat diaudit dari kuartal ke kuartal.
Mengapa Hitungan Keluhan Mentah Gagal
Sebelum membangun model, pahami mengapa alternatif yang paling umum (menghitung keluhan) menghasilkan prioritas yang buruk. Riset penentuan prioritas persyaratan di Wikipedia mendokumentasikan beberapa pendekatan penilaian terstruktur (termasuk model RICE: Reach x Impact x Confidence dibagi Effort) dan penilaian berbobot yang ada justru karena hitungan suara mentah dan peringkat berdasarkan intuisi menghasilkan hasil yang secara sistematis bias.
Bias volume: Fitur yang diinginkan 50 pelanggan kecil mengalahkan fitur yang dibutuhkan 3 pelanggan enterprise. Jika Anda menghitung berdasarkan volume akun, Anda membangun untuk kuantitas akun, bukan kualitas pendapatan. Permintaan fitur dari 50 akun yang mewakili $250K ARR kalah dari permintaan fitur dari 3 akun yang mewakili $900K ARR dalam model pembobotan mana pun yang rasional. Tetapi hitungan mentah tidak bisa melihat itu.
Bias "roda yang berderit": Pelanggan yang vokal mendominasi channel feedback. Pelanggan yang menulis permintaan fitur rinci, hadir dalam sesi riset pengguna, dan merespons setiap survei NPS tidak mewakili basis pelanggan Anda. Mereka adalah kuartil yang paling engaged. Mereka yang pergi diam-diam, yaitu yang berhenti menggunakan fitur, tidak berkata apa-apa, dan membatalkan saat pembaruan, tidak pernah muncul dalam hitungan keluhan.
Bias kesegaran: Apa pun yang muncul bulan ini diprioritaskan di atas masalah ekor panjang kronis yang telah dilaporkan selama delapan bulan. Masalah ekor panjang memiliki lebih banyak total laporan. Tetapi telah dinormalisasi ("begitulah cara produk bekerja") sementara keluhan baru terasa mendesak karena segar.
Model penilaian mengatasi ketiga mode kegagalan tersebut dengan menormalisasi di seluruh ARR, memberi bobot akun berisiko secara terpisah dari akun sehat, dan melihat frekuensi kumulatif daripada kesegaran.
Key Facts: Mengapa Penentuan Prioritas Produk Membutuhkan Model Penilaian
- 74% product manager melaporkan bahwa feedback pelanggan memengaruhi roadmap mereka, tetapi hanya 31% yang memiliki sistem formal untuk mengkuantifikasi pengaruh tersebut. Sisanya mengandalkan kesan kualitatif dan advokasi internal, menurut laporan State of Product Leadership Pendo.
- Fitur yang diprioritaskan menggunakan customer-impact scoring terstruktur (menggabungkan bobot ARR, frekuensi, dan risiko perpindahan) memiliki tingkat adopsi 40% lebih tinggi saat peluncuran dibandingkan fitur yang diprioritaskan melalui proses informal, menurut riset Productboard tentang perusahaan yang dipimpin produk.
- Penentuan prioritas yang didorong HiPPO (pendapat orang dengan bayaran tertinggi) memengaruhi keputusan roadmap di 58% perusahaan SaaS mid-market, bahkan ketika data feedback pelanggan tersedia. Kesenjangan tersebut adalah ketiadaan model pembobotan terstruktur, menurut Product Management Institute.
Tiga Filosofi Penilaian
Sebelum membangun komposit, pahami filosofi mana yang dicerminkan setiap komponen. Tim akan memperdebatkan mana yang "menang," dan jawabannya adalah tidak satu pun dari mereka menang secara terpisah.
Penilaian berbasis ARR memprioritaskan berdasarkan dampak pendapatan: jumlah ARR dari semua akun yang menandai suatu masalah menentukan bobot skornya. Ini tepat untuk melindungi pendapatan teratas dan untuk roadmap yang melayani strategi enterprise-first. Ini salah sebagai satu-satunya masukan karena secara sistematis meremehkan akun SMB bahkan ketika SMB mewakili segmen pertumbuhan yang aktif coba dikembangkan perusahaan. Penilaian kesehatan pelanggan dengan konteks penjualan membahas cara melipat pipeline ekspansi dan risiko pembaruan ke dalam catatan akun yang sama, sehingga angka ARR yang ditarik CS Ops untuk model penilaian mencerminkan realitas bisnis saat ini, bukan snapshot CRM enam bulan yang lalu.
Penilaian frekuensi keluhan memprioritaskan berdasarkan volume akun unik yang melaporkan. Ini tepat untuk strategi adopsi luas dan model PLG di mana metriknya adalah berapa banyak pelanggan yang menggunakan fitur, bukan berapa banyak pendapatan yang mereka wakili. Ini salah sebagai satu-satunya masukan karena mengabaikan dampak pendapatan dan memberikan bobot yang sama pada akun $5K dan akun $200K.
Penilaian berbasis bobot risiko memprioritaskan berdasarkan korelasi risiko perpindahan. Akun yang berisiko atau sedang dalam percakapan perpindahan mendapatkan bobot yang ditingkatkan ketika menghitung kasus bisnis untuk suatu fitur. Ini tepat untuk kuartal yang berfokus pada retensi dan lingkungan dengan perpindahan tinggi. Ini salah sebagai satu-satunya masukan karena berarti roadmap didorong oleh akun yang paling bermasalah daripada yang paling berharga.
Model komposit menggabungkan ketiganya. Bobot di antara mereka adalah keputusan bisnis, dan membuat keputusan itu eksplisit sendiri sudah berharga. Bagian berikutnya menunjukkan cara menghitungnya dengan tepat.
Membangun Customer-Impact Score Komposit
Langkah 1: Kumpulkan input untuk setiap item backlog
Untuk setiap item yang dinilai, CS perlu menyediakan empat titik data:
Faktor 1: ARR yang terdampak. Jumlah ARR dari semua akun yang telah melaporkan masalah ini atau meminta fitur ini. Tarik dari platform CS, bukan dari ingatan. Jika Anda tidak memiliki feedback yang diberi tag yang terkait dengan akun, langkah ini tidak berfungsi, itulah mengapa pipeline tiket dukungan ke backlog produk dan taksonomi feedback bersama adalah prasyaratnya.
Faktor 2: Jumlah akun. Jumlah akun unik yang telah melaporkan masalah tersebut, dinormalisasi ke skala 0-10 berdasarkan jumlah total akun Anda. Jika Anda memiliki 200 akun dan 20 telah menandai masalah, itu adalah tingkat penetrasi 10%. Normalisasi ini agar jumlah akun dapat dibandingkan di seluruh item terlepas dari apakah angka absolutnya 5 atau 50.
Faktor 3: Bobot risiko perpindahan. Jumlah akun berisiko (health score di bawah ambang batas, percakapan perpindahan terbuka, atau pembaruan dalam 90 hari) yang telah melaporkan masalah tersebut, dikalikan dengan koefisien risiko. Koefisien standar adalah 2,0. Akun berisiko dihitung dua kali lipat dalam model penilaian karena biaya bisnis kehilangan akun tersebut lebih tinggi dan lebih segera.
Faktor 4: Flag akun strategis. Biner: apakah ada akun bernama/strategis yang muncul dalam daftar akun yang terdampak? Akun bernama adalah akun yang muncul di daftar akun bernama perusahaan, biasanya akun berARR teratas atau logo kunci. Flag ini menambahkan bonus tetap ke skor karena akun strategis membawa nilai hubungan dan referensi di luar ARR mereka.
Langkah 2: Terapkan rumus penilaian
Customer-Impact Score =
(ARR yang Terdampak / Total ARR Perusahaan × 40)
+ (Jumlah Akun yang Dinormalisasi × 25)
+ (Akun Berisiko × 2,0 × 20 / Skor At-Risk Maksimum yang Mungkin)
+ (Flag Akun Strategis × 15)
Bobot (40/25/20/15) berjumlah 100 dan dapat disesuaikan berdasarkan prioritas strategis perusahaan Anda saat ini. Dalam kuartal yang berfokus pada retensi, tingkatkan bobot at-risk. Dalam kuartal ekspansi enterprise, tingkatkan bobot ARR. Dokumentasikan alasan bobot saat Anda menetapkannya.
Langkah 3: Contoh numerik yang dikerjakan (4 item backlog yang bersaing)
Konteks perusahaan: Perusahaan SaaS mid-market. Total ARR: $8 juta. Total akun: 180. Akun bernama (20 teratas berdasarkan ARR): 20 akun.
Item A: Bulk export (peningkatan batas baris)
- Akun yang melaporkan: 28 akun unik
- ARR yang terdampak: $840.000
- Akun berisiko dalam daftar: 4
- Flag akun strategis: Tidak (tidak ada akun bernama yang terdampak)
Penilaian:
- Komponen ARR: ($840 ribu / $8 juta) × 40 = 4,2
- Komponen jumlah akun: 28/180 = 15,6%, normalisasi: 15,6/20 × 10 = 7,8 × 25/10 = 19,5
- Komponen at-risk: (4 × 2,0) = 8 akun berbobot at-risk. At-risk maks yang mungkin di tim adalah 30 (15% akun dalam periode mana pun). 8/30 × 20 = 5,3
- Flag strategis: 0
Total Item A: 4,2 + 19,5 + 5,3 + 0 = 29,0
Item B: Integrasi kalender (sinkronisasi native)
- Akun yang melaporkan: 11 akun unik
- ARR yang terdampak: $1.320.000
- Akun berisiko dalam daftar: 1
- Flag akun strategis: Ya (2 akun bernama terdampak)
Penilaian:
- Komponen ARR: ($1,32 juta / $8 juta) × 40 = 6,6
- Komponen jumlah akun: 11/180 = 6,1%, normalisasi: 6,1/20 × 10 = 3,1 × 25/10 = 7,6
- Komponen at-risk: (1 × 2,0) = 2. 2/30 × 20 = 1,3
- Flag strategis: 15
Total Item B: 6,6 + 7,6 + 1,3 + 15 = 30,5
Item C: Mode offline aplikasi mobile
- Akun yang melaporkan: 6 akun unik
- ARR yang terdampak: $190.000
- Akun berisiko dalam daftar: 3
- Flag akun strategis: Tidak
Penilaian:
- Komponen ARR: ($190 ribu / $8 juta) × 40 = 0,95
- Komponen jumlah akun: 6/180 = 3,3%, normalisasi: 3,3/20 × 10 = 1,7 × 25/10 = 4,1
- Komponen at-risk: (3 × 2,0) = 6. 6/30 × 20 = 4,0
- Flag strategis: 0
Total Item C: 0,95 + 4,1 + 4,0 + 0 = 9,05
Item D: Tipe field kustom (multi-select)
- Akun yang melaporkan: 41 akun unik
- ARR yang terdampak: $510.000
- Akun berisiko dalam daftar: 2
- Flag akun strategis: Ya (1 akun bernama terdampak)
Penilaian:
- Komponen ARR: ($510 ribu / $8 juta) × 40 = 2,55
- Komponen jumlah akun: 41/180 = 22,8%, dibatasi pada maks 20% → 10 × 25/10 = 25
- Komponen at-risk: (2 × 2,0) = 4. 4/30 × 20 = 2,7
- Flag strategis: 15
Total Item D: 2,55 + 25 + 2,7 + 15 = 45,25
Ringkasan skor komposit dan rekomendasi PM:
| Item Backlog | Komponen ARR | Jumlah Akun | At-Risk | Flag Strategis | Total Skor | Rekomendasi PM |
|---|---|---|---|---|---|---|
| D: Tipe field kustom | 2,55 | 25,0 | 2,7 | 15 | 45,25 | Prioritas 1: volume tinggi + flag akun strategis mendorong ini di atas item berARR lebih tinggi |
| B: Integrasi kalender | 6,6 | 7,6 | 1,3 | 15 | 30,5 | Prioritas 2: ARR tinggi per akun dan flag strategis; penetrasi akun relatif rendah |
| A: Bulk export | 4,2 | 19,5 | 5,3 | 0 | 29,0 | Prioritas 3: jumlah akun kuat dan bobot at-risk; pantau jika jumlah at-risk bertumbuh |
| C: Mode offline mobile | 0,95 | 4,1 | 4,0 | 0 | 9,05 | Prioritas 4: basis kecil; bobot at-risk mencegahnya dideprioritaskan sepenuhnya |
Permukaan penilaian: Item D menang bukan karena memiliki dampak ARR tertinggi (Item B yang memilikinya) atau bobot at-risk tertinggi (Item A yang memilikinya). Ia menang karena skornya mencakup semua empat dimensi: penetrasi akun tinggi, akun bernama, dan bobot at-risk yang cukup untuk mengonfirmasikan bahwa ini adalah risiko retensi, bukan sekadar permintaan fitur.
Inilah nilai komposit: ia menghasilkan peringkat yang dapat dipertahankan yang tidak bisa dihasilkan model faktor tunggal mana pun.
Cara CS Memberi Masukan ke Skor
Model penilaian hanya sebaik data yang disediakan CS. Untuk setiap item backlog, CSM perlu mencatat:
- Deskripsi masalah dalam taksonomi bersama (bukan teks bebas)
- Daftar akun: setiap akun yang menandai masalah ini, dengan catatan akun mereka yang ditautkan
- ARR per akun (ditarik dari CRM, bukan diperkirakan)
- Tanggal pembaruan untuk tiga akun yang paling dekat dengan pembaruan
- Health score pada saat pencatatan
- Bahasa pelanggan verbatim apa pun yang layak disimpan untuk tim produk
Siapa yang memperkaya skor: CS Ops, bukan CSM individual. CSM individual memberi tag feedback di platform CS. CS Ops mengagregasi, memperkaya dengan data ARR dari CRM, dan menjalankan rumus penilaian. Pemisahan ini menjaga konsistensi data dan mencegah CSM individual secara tidak sengaja menggembungkan skor untuk akun mereka sendiri.
Kadensa: Penilaian batch dua mingguan. Penilaian real-time menimbulkan noise. Satu laporan baru seharusnya tidak menggeser prioritas dalam siklus sprint mingguan. Penilaian dua mingguan memberikan cukup waktu bagi data untuk terakumulasi sebelum memengaruhi diskusi roadmap.
Cara Product Menggunakan Skor
Di mana skor berada: Di backlog produk sebagai field kustom, bukan di spreadsheet CS terpisah. Jika skor berada di spreadsheet, ia akan dirujuk sesekali. Jika itu adalah field di alat backlog, ia terlihat setiap kali PM membuka item backlog.
Cara menimbangnya terhadap input lain: Customer-impact score adalah satu masukan di antara beberapa masukan dalam penentuan prioritas roadmap. Utang teknis, taruhan produk strategis, persyaratan regulasi, dan kompleksitas engineering semuanya termasuk dalam percakapan yang sama. Bobot awal yang wajar untuk customer-impact score adalah 30-40% dari skor penentuan prioritas keseluruhan.
Skor adalah pengganda, bukan mandat: Customer-impact score sebesar 45 tidak berarti fitur tersebut dirilis sprint berikutnya. Ini berarti fitur tersebut memiliki kasus pelanggan yang kuat yang harus memengaruhi percakapan penentuan prioritas. PM yang mengesampingkan item dengan skor tinggi karena keterbatasan teknis atau pertimbangan strategis tidak mengabaikan sistem. Mereka menggunakan pertimbangannya, yang diinformasikan oleh sistem. Itulah penggunaan yang dimaksudkan.
Kasus Tepi dan Pemutus Seri
Akun berARR rendah dengan suara yang tidak proporsional kuat: Akun $10K yang CSM-nya sangat aktif dan penulis yang baik secara alami akan menghasilkan lebih banyak feedback yang dicatat daripada akun $200K dengan hubungan CSM yang lebih pasif. Komponen ARR menangani hal ini secara otomatis. Feedback akun berARR rendah berkontribusi secara proporsional lebih sedikit ke komponen ARR terlepas dari berapa kali masalah dicatat.
Satu akun enterprise yang mendorong skor yang jika tidak akan kalah: Ini berfungsi sesuai desain, bukan bug. Jika akun $600K adalah satu-satunya yang melaporkan masalah dan satu akun itu mewakili 7,5% dari total ARR, komponen ARR saja menghasilkan skor yang bermakna. Tambahkan flag strategis jika mereka adalah akun bernama dan skor komposit mencerminkan pentingnya bisnis mereka yang sebenarnya.
Akun berisiko semua menginginkan fitur yang sama yang tidak sesuai strategi: Nilailah item menggunakan model. Kemudian PM meninjau rekomendasi dan membuat keputusan berdasarkan pertimbangannya: "Item ini mendapat skor 28 terutama karena bobot at-risk, tetapi fiturnya tidak konsisten dengan strategi produk kami saat ini. Kami tidak bisa membangunnya. Apa yang dapat dilakukan CS untuk mempertahankan akun-akun ini tanpa perubahan produk?" Itulah percakapan yang tepat. Dan itu percakapan yang lebih baik dari yang dimulai dengan "pelanggan-pelanggan ini akan pergi kecuali kami membangun ini."
Jebakan: Cara Tim Merusak Model
Riset McKinsey tentang product manager terbaik menemukan bahwa PM terbaik memperlakukan data pelanggan sebagai satu masukan di antara beberapa masukan. Mereka menggunakan model penilaian untuk menginformasikan penentuan prioritas, bukan untuk menggantikan keputusan pertimbangan yang memerlukan konteks strategis, kelayakan teknis, dan kesadaran kompetitif.
CS secara selektif memilih akun mana yang disertakan. Jika CSM secara selektif mencatat feedback dari akun yang mereka tahu akan menggembungkan skor, model menghasilkan output yang bias. Selesaikan ini secara struktural: semua item feedback yang dicatat masuk ke agregat secara otomatis. CSM tidak memilih akun mana yang disertakan dalam penilaian. Jika CSM suatu akun mencatat feedback menggunakan taksonomi standar, itu sudah masuk.
Skor tidak diperbarui ketika status akun berubah. Akun yang memperbarui dan beralih dari kuning ke hijau masih memiliki bobot risiko perpindahan dari enam bulan lalu jika tidak ada yang memperbaruinya. CS Ops harus menjalankan penyegaran status akun kuartalan: memperbarui health score, jadwal pembaruan, dan status akun bernama untuk semua akun dalam database penilaian. Tinjauan feedback pelanggan kuartalan adalah titik pemeriksaan alami untuk penyegaran ini, di mana product dan CS bersama-sama memvalidasi apakah skor kuartal lalu memprediksi hasil yang benar sebelum mengkalibrasi ulang bobot.
Memperlakukan skor sebagai mesin peringkat daripada masukan. Model memberi peringkat item backlog berdasarkan dampak pelanggan. Ini tidak memberi peringkat berdasarkan apa yang harus dibangun berikutnya. Kompleksitas engineering, kesesuaian strategis, dan utang teknis semuanya termasuk dalam percakapan. Tim yang mulai memperlakukan customer-impact score sebagai keseluruhan jawaban penentuan prioritas akan membuat keputusan yang tidak koheren secara teknis, merilis fitur berbobot tinggi yang tidak bisa dibangun dalam waktu yang diharapkan roadmap.
Cara Ini Terhubung ke Sistem Pengenalan Pola dan Feedback
Customer-impact scoring adalah lapisan kuantifikasi yang berada di atas pengenalan pola di seluruh CSM. Pengenalan pola mengidentifikasi bahwa sebuah tema ada. Lima CSM telah mendengar keluhan bulk export. Customer-impact scoring menjawab pertanyaan bisnis: seberapa penting hal itu?
Kuantifikasi ARR-weighted feedback membahas lapisan pemodelan keuangan secara lebih rinci, khususnya cara menormalisasi dampak ARR di berbagai ukuran akun. Masalah kuburan permintaan fitur adalah konsekuensi hilir dari backlog tanpa penilaian: permintaan terakumulasi, tidak ada yang dirilis, pelanggan berhenti mengajukan.
Memprioritaskan feedback pelanggan tanpa tenggelam di dalamnya membahas lapisan penyaringan intake yang memastikan hanya feedback yang dinilai dan terstruktur yang mencapai tim produk sejak awal. Dan tinjauan feedback pelanggan kuartalan adalah tempat model penilaian divalidasi terhadap hasil aktual: apakah item yang kami prioritaskan menghasilkan hasil retensi dan adopsi yang diprediksi skor?
Analisis Rework: Dalam analisis kami tentang pola penentuan prioritas SaaS mid-market, mode kegagalan yang paling umum bukan memilih rumus penilaian yang salah. Ini menggunakan skor sebagai mesin peringkat daripada masukan. 4-Factor Customer Impact Score adalah pengganda pada pertimbangan PM, bukan pengganti darinya. Tim yang mendapat nilai paling banyak dari model menjalankan siklus penilaian dua mingguan (bukan real-time), menyimpan skor sebagai field kustom langsung di alat backlog (bukan spreadsheet terpisah), dan melakukan kalibrasi ulang bobot kuartalan di mana mereka membandingkan item dengan skor tertinggi kuartal lalu terhadap hasil aktual. Sesi kalibrasi ulang biasanya mengungkap apakah koefisien at-risk (2,0) diskalakan dengan benar untuk lingkungan perpindahan saat ini. Dalam kuartal dengan perpindahan tinggi, koefisien 2,5-3,0 mungkin lebih baik mencerminkan biaya bisnis nyata dari kehilangan akun berisiko.
Pelajari Lebih Lanjut
- ARR-Weighted Feedback: Mengkuantifikasi Suara Pelanggan
- Pengenalan Pola di Seluruh CSM: Masalah Sistematis
- Masalah Kuburan Permintaan Fitur
- Memprioritaskan Feedback Pelanggan (Tanpa Tenggelam di Dalamnya)
- Tinjauan Feedback Pelanggan Kuartalan (Bersama)
Pertanyaan yang Sering Diajukan
Apa itu 4-Factor Customer Impact Score?
4-Factor Customer Impact Score adalah model penilaian komposit 0-100 yang mengkuantifikasi kasus bisnis pelanggan untuk setiap item backlog produk. Empat faktornya adalah: ARR yang Terdampak (bobot 40%), Jumlah Akun yang Dinormalisasi (bobot 25%), Bobot Akun Berisiko dengan koefisien perpindahan 2,0 (bobot 20%), dan Flag Akun Strategis, bonus biner untuk akun bernama/enterprise (bobot 15%). Rumusnya adalah: (ARR yang Terdampak / Total ARR × 40) + (Jumlah Akun yang Dinormalisasi × 25) + (Akun Berisiko × 2,0 × 20 / Skor At-Risk Maksimum yang Mungkin) + (Flag Akun Strategis × 15). Bobot berjumlah 100 dan dapat disesuaikan berdasarkan prioritas kuartal strategis.
Mengapa hitungan keluhan mentah tidak berfungsi untuk penentuan prioritas produk?
Hitungan mentah menghasilkan tiga bias sistematis. Bias volume: fitur yang diinginkan 50 pelanggan kecil mengalahkan fitur yang dibutuhkan 3 pelanggan enterprise, bahkan ketika fitur enterprise mewakili 3x ARR. Bias roda berderit: pelanggan yang menulis permintaan rinci dan merespons setiap survei adalah kuartil yang paling engaged. Mereka tidak mewakili, dan mereka yang pergi diam-diam tidak pernah muncul dalam hitungan keluhan. Bias kesegaran: apa pun yang muncul bulan ini diprioritaskan di atas masalah ekor panjang kronis dengan lebih banyak total laporan selama delapan bulan. Model 4-Faktor mengatasi ketiganya dengan menormalisasi di seluruh ARR, menerapkan koefisien perpindahan, dan melihat frekuensi kumulatif daripada kesegaran.
Bagaimana bobot akun berisiko bekerja dalam model penilaian?
Akun berisiko (didefinisikan sebagai akun dengan health score di bawah ambang batas, percakapan perpindahan terbuka, atau pembaruan dalam 90 hari) menerima koefisien perpindahan 2,0 ketika mereka muncul dalam daftar akun yang terdampak. Akun berisiko dihitung dua kali lipat dalam model penilaian karena biaya bisnis kehilangan akun tersebut lebih tinggi dan lebih segera daripada biaya akun sehat yang mengalami gesekan yang sama. Dalam contoh yang dikerjakan: Item A (bulk export) mendapat skor 5,3 pada komponen at-risk karena 4 akun berisiko terdampak, menerapkan 2,0x masing-masing terhadap skor at-risk maks yang mungkin sebesar 30. Bobot at-risk tersebut mengangkat Item A ke Prioritas 3 meskipun ARR per akun lebih rendah dari Item B.
Apa itu flag akun strategis dan kapan itu diterapkan?
Flag akun strategis adalah bonus skor biner sebesar 15 poin yang diterapkan ketika setidaknya satu akun bernama/enterprise muncul dalam daftar akun yang terdampak. Akun bernama didefinisikan sebagai akun berARR teratas perusahaan berdasarkan jumlah yang telah disepakati sebelumnya (biasanya 20 akun teratas berdasarkan ARR). Flag ini diterapkan karena akun strategis membawa nilai hubungan dan referensi di luar angka ARR mereka. Dalam contoh yang dikerjakan, Item B dan D keduanya menerima flag 15 poin. Inilah yang mengangkat Item D (tipe field kustom) ke Prioritas 1 meskipun dampak ARR per akun lebih rendah dari Item B, dikombinasikan dengan skor penetrasi akun yang tinggi.
Seberapa sering customer-impact score harus diperbarui?
Dua mingguan. Penilaian real-time menimbulkan noise. Satu laporan akun baru seharusnya tidak menggeser prioritas dalam siklus sprint mingguan. Penilaian dua mingguan memberikan cukup waktu bagi data untuk terakumulasi sebelum memengaruhi diskusi roadmap. Selain itu, CS Ops harus menjalankan penyegaran status akun kuartalan: memperbarui health score, jadwal pembaruan, dan status akun bernama untuk semua akun dalam database penilaian. Akun yang memperbarui dan beralih dari kuning ke hijau masih memiliki bobot risiko perpindahan dari enam bulan lalu jika tidak ada yang memperbaruinya, yang menghasilkan skor yang melebih-lebihkan risiko retensi untuk akun yang kini sudah stabil.
Bagaimana tim produk harus menimbang customer-impact score terhadap input penentuan prioritas lainnya?
Bobot awal yang wajar untuk customer-impact score adalah 30-40% dari skor penentuan prioritas keseluruhan. Sisa bobot mencakup utang teknis, taruhan produk strategis, persyaratan regulasi, dan kompleksitas engineering. Customer-impact score sebesar 45 tidak berarti fitur tersebut dirilis sprint berikutnya. Ini berarti fitur tersebut memiliki kasus pelanggan yang kuat yang harus menjadi faktor menonjol dalam percakapan penentuan prioritas. Menurut riset McKinsey tentang product manager terbaik, PM terbaik memperlakukan data pelanggan sebagai satu masukan di antara beberapa masukan, menggunakan model penilaian untuk menginformasikan penentuan prioritas daripada menggantikan keputusan pertimbangan yang memerlukan konteks strategis dan kesadaran kelayakan teknis.

Senior Operations & Growth Strategist
On this page
- Mengapa Hitungan Keluhan Mentah Gagal
- Tiga Filosofi Penilaian
- Membangun Customer-Impact Score Komposit
- Langkah 1: Kumpulkan input untuk setiap item backlog
- Langkah 2: Terapkan rumus penilaian
- Langkah 3: Contoh numerik yang dikerjakan (4 item backlog yang bersaing)
- Cara CS Memberi Masukan ke Skor
- Cara Product Menggunakan Skor
- Kasus Tepi dan Pemutus Seri
- Jebakan: Cara Tim Merusak Model
- Cara Ini Terhubung ke Sistem Pengenalan Pola dan Feedback
- Pelajari Lebih Lanjut
- Pertanyaan yang Sering Diajukan
- Apa itu 4-Factor Customer Impact Score?
- Mengapa hitungan keluhan mentah tidak berfungsi untuk penentuan prioritas produk?
- Bagaimana bobot akun berisiko bekerja dalam model penilaian?
- Apa itu flag akun strategis dan kapan itu diterapkan?
- Seberapa sering customer-impact score harus diperbarui?
- Bagaimana tim produk harus menimbang customer-impact score terhadap input penentuan prioritas lainnya?