Integración de la plataforma de CS con el backlog de producto: hacer que las herramientas de CS y Producto trabajen juntas
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Aquí está el problema del copiar y pegar en toda su absurdidad: un CSM (Customer Success Manager) registra una solicitud de funcionalidad en Gainsight con una cita textual del cliente, el ARR de la cuenta y otras tres cuentas que han planteado el mismo problema. Ese registro está en la plataforma de CS. A dos pisos de distancia (o a dos canales de Slack de distancia), un PM tiene una columna de backlog en Jira llamada "solicitudes de CS" con siete tickets etiquetados de forma vaga: algunos de hace 14 meses, ninguno con contexto de ARR, dos sin ninguna descripción. El registro rico del CSM y el ticket vacío del PM nunca se han conectado formalmente.
Las herramientas existen. La integración no.
Y esto no es un problema de proveedor. Cambiar Gainsight por ChurnZero, o Jira por Linear, no lo arregla. El fallo está en el diseño del flujo de trabajo y en el acuerdo de taxonomía: las decisiones que tienen que ocurrir antes de configurar cualquier herramienta de integración. El Cuadrante Mágico de Gartner para las plataformas de gestión de customer success evalúa las principales plataformas de CS exactamente en estas capacidades de integración. Es un punto de partida útil y neutral respecto a proveedores antes de comprometerse con un stack. La mayoría de los equipos se saltan estas decisiones, conectan las herramientas con un zap de Zapier, y seis meses después descubren que la integración técnicamente funciona pero es prácticamente inútil. El stack previo (CRM, plataforma de CS e inteligencia de ingresos conectados entre sí) determina cuántos datos estructurados hay disponibles para canalizar en primer lugar; consulte la visión general del stack alineado para conocer el contexto de cómo interactúan esas capas.
Este artículo trata de acertar primero con el diseño del flujo de trabajo, y luego elegir el patrón de integración que encaje con la madurez actual de sus herramientas.
Por qué esta integración es más difícil de lo que parece
Datos clave: integración de CS a Producto
- Solo el 23% de los equipos de producto tienen un proceso formal y documentado para recibir y canalizar la retroalimentación de CS hacia el backlog de producto, según la encuesta State of Product Management de Productboard de 2024.
- La empresa de SaaS de mercado medio mediana tiene 4,7 puntos de transferencia entre un CSM que plantea una solicitud de funcionalidad y esa solicitud apareciendo en un backlog revisado por un PM, según el CS Operations Report de CS Insider de 2024.
- Las tasas de cementerio de solicitudes de funcionalidad (solicitudes que entran en el backlog de producto pero nunca se revisan ni se cierran) corren entre el 55% y el 70% en empresas sin una taxonomía compartida entre CS y producto, según la investigación de ProductPlan.
- Los equipos con una taxonomía de retroalimentación compartida entre CS y producto reportan un tiempo 3,1 veces más rápido desde la solicitud hasta el reconocimiento del PM que los que no la tienen, según los datos de CS Benchmark de Gainsight.
Las plataformas de CS y las herramientas de backlog de producto están construidas sobre modelos de datos fundamentalmente diferentes, y esto importa más que las herramientas específicas que esté usando. Cómo se conectan esos modelos con el resto del registro del cliente (incluidos los datos del CRM y el historial compartido de la cuenta) se cubre en profundidad en la guía de arquitectura del registro compartido del cliente.
Las plataformas de CS registran el mundo por cuenta. Cada dato (puntuación de salud, NPS, solicitud de funcionalidad, escalamiento de soporte) está anclado a una cuenta de cliente con nombre. El índice principal de la plataforma de CS es el registro de la cuenta.
Las herramientas de backlog de producto registran el mundo por funcionalidad o épica. Un ticket de Jira existe de forma independiente de las cuentas. Podría representar 40 cuentas o una. El índice principal de la herramienta de producto es el elemento de trabajo.
Cuando un CSM registra una solicitud de funcionalidad en Gainsight, está adjunta a una cuenta específica. Cuando un PM mira esa solicitud en Jira, el contexto de la cuenta a menudo se elimina o se codifica en un campo personalizado que nadie mantiene. La relación de 1 a muchos (un ticket de funcionalidad que representa muchas cuentas) es el problema central de traducción. No es una limitación técnica. Es un desajuste del modelo de datos, y ninguna cantidad de integración nativa lo resuelve sin un diseño deliberado de taxonomía.
El otro desajuste es la cadencia. Las plataformas de CS se actualizan de forma continua: las puntuaciones de salud cambian a diario, los tickets de soporte se abren y se cierran, los CSM registran llamadas en tiempo real. Las herramientas de backlog de producto operan en ciclos de sprint. Una solicitud de funcionalidad que entra en Jira un martes podría no revisarse hasta la próxima sesión de planificación de sprint en dos semanas. La integración necesita tener en cuenta ambas cadencias: la canalización urgente (algo que necesita la atención del PM esta semana) y la canalización por lotes (la cola regular que alimenta la planificación de sprint).
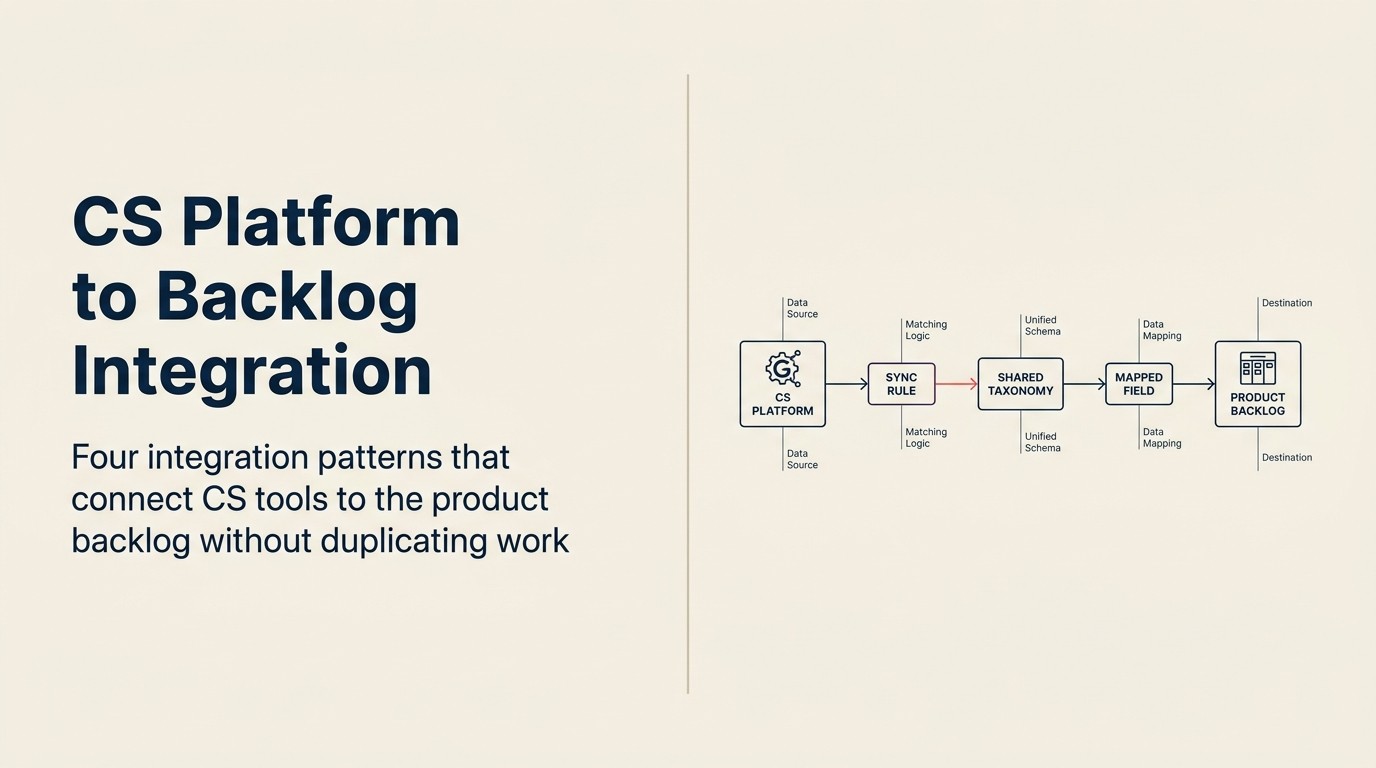
Lo que "integración" realmente significa aquí no es una sincronización. Es una transferencia estructurada con lógica de traducción. Una sincronización implica que dos sistemas se mantengan de acuerdo. Lo que CS a producto realmente necesita es que un registro en la plataforma de CS se convierta en un registro en la herramienta de producto, con los campos correctos rellenados, en el formato correcto, con la lógica de canalización correcta aplicada. Qué patrón de integración lo lleva allí depende de cuánta madurez de RevOps y automatización tenga realmente su equipo hoy.
Los cuatro patrones de integración (neutrales respecto a proveedores)
Marco con nombre: el modelo de integración de 4 patrones El modelo de integración de 4 patrones clasifica la integración del backlog de CS a producto por nivel de automatización y complejidad de implementación: Patrón 1 (manual con estructura), Patrón 2 (conector nativo), Patrón 3 (middleware propiedad de CS Ops) y Patrón 4 (sincronización de estado bidireccional). Cada patrón es neutral respecto a proveedores y está diseñado para coincidir con la madurez actual de RevOps y el volumen de cuentas de un equipo, en lugar de requerir una combinación específica de herramientas. El valor principal del modelo es evitar que los equipos intenten el Patrón 4 antes de tener la infraestructura de datos y la capacidad de ingeniería para mantenerlo.
Estos cuatro patrones están ordenados por complejidad de implementación y nivel de automatización. La elección correcta depende de la madurez actual de sus herramientas, la capacidad de RevOps y el volumen de cuentas.
Patrón 1: manual con estructura. Una plantilla compartida (un documento de Google, una tabla de Notion o una hoja de cálculo dedicada) que CS Ops rellena semanalmente desde la plataforma de CS y envía al líder de PM. El líder de PM la revisa en un bloque de tiempo designado y canaliza los elementos al backlog manualmente. Sin automatización. Sin integración nativa. Solo un formato definido y un ritmo semanal.
Para quién funciona: equipos con menos de 50 cuentas activas, una función de CS Ops en etapa temprana sin soporte dedicado de RevOps, o equipos donde el líder de PM y el líder de CS se sientan cerca y una sincronización semanal de 20 minutos cubre más terreno que cualquier feed automatizado. El costo es el tiempo del PM para revisar y canalizar. El beneficio es cero sobrecarga de mantenimiento de la integración.
Patrón 2: conector nativo. Gainsight tiene una integración nativa con Jira para crear tickets a partir de CTA (Calls to Action) y del módulo de Feedback. ChurnZero se conecta a Jira, Asana o Productboard a través de Zapier o Make. El conector pasa un conjunto definido de campos del registro de la plataforma de CS al registro de la herramienta de producto.
Qué datos fluyen en realidad: nombre de la cuenta, ARR de la cuenta (si está mapeado), el texto textual de la solicitud de funcionalidad, el CSM que la registró y una marca de tiempo. Qué se pierde normalmente: el número de cuentas (cuántas otras cuentas plantearon el mismo problema), la solución provisional que el cliente está usando, el contexto de urgencia y cualquier vínculo con un tema o categoría de producto. Estos campos requieren una configuración manual de mapeo que la mayoría de los equipos se salta durante la configuración inicial.
Qué auditar antes de poner en marcha un conector nativo: ¿los campos personalizados del ticket de Jira o del registro de Productboard están realmente mapeados y son obligatorios? Si son opcionales, estarán vacíos el 80% del tiempo en un plazo de 60 días.
Patrón 3: middleware propiedad de CS Ops. RevOps o CS Ops ejecuta la lógica de canalización como una función dedicada, no una automatización, sino un paso humano definido con criterios estructurados. CS Ops revisa la cola de retroalimentación entrante semanalmente, aplica los criterios de canalización (basados en umbrales: ¿qué elementos cumplen el listón de ARR y de número de cuentas para ir al backlog de producto?), formatea el registro de transferencia usando el formato mínimo viable (abajo) y lo envía al equipo de PM a través de la herramienta de producto acordada.
Para quién funciona: equipos con 50 a 200 cuentas, una función activa de RevOps o CS Ops, y un equipo de PM que se ha quejado de la retroalimentación de CS ruidosa o sin formatear. Este patrón requiere madurez de RevOps pero produce los aportes más limpios y mejor formateados al backlog de producto de cualquier patrón salvo la sincronización bidireccional.
Patrón 4: sincronización de estado bidireccional. La plataforma de CS y la herramienta de producto se mantienen sincronizadas de forma bidireccional. Cuando un PM actualiza el estado de un ticket (en revisión / en la hoja de ruta / rechazado / lanzado), el registro de la cuenta en la plataforma de CS refleja ese estado. Cuando un CSM registra una nueva solicitud de funcionalidad, crea automáticamente un ticket en la herramienta de producto.
Para quién funciona: equipos con un RevOps maduro, un recurso de ingeniería de datos que pueda mantener la sincronización, y más de 200 cuentas donde la revisión manual en cualquier paso crea cuellos de botella. Este es el estándar de oro. También es la implementación más rara en el mercado medio porque mantener la sincronización bidireccional requiere atención continua de ingeniería cuando cualquiera de las herramientas cambia su API o su modelo de datos.
La mayoría de los equipos de mercado medio están en el Patrón 1 o el Patrón 2, quieren estar en el Patrón 3, y tienen a alguien en el equipo abogando por el Patrón 4 antes de que el equipo esté listo para él. Antes de que cualquier patrón funcione de forma fiable, ambos equipos necesitan acordar qué datos cruzan realmente la junta.
Análisis de Rework: Con base en los benchmarks de la industria, el fallo de integración más común no es la selección de herramientas. Es el desajuste de taxonomía entre CS y producto. Los equipos que establecen una taxonomía compartida de cinco categorías antes de configurar cualquier herramienta de integración reducen las tasas de cementerio de solicitudes de funcionalidad (solicitudes que entran en el backlog pero nunca se revisan ni se cierran) aproximadamente a la mitad en comparación con los equipos que dependen de las etiquetas por defecto de cada sistema. El registro de transferencia mínimo viable (seis campos: enunciado de la solicitud de funcionalidad, número de cuentas, ARR en juego, cita textual, solución provisional actual, CSM que la envía) es el único cambio estructural que más mejora la calidad de la señal en los cuatro patrones de integración.
Qué datos deberían cruzar realmente la junta
Antes de configurar cualquier patrón de integración, acuerde el registro de transferencia mínimo viable. Este es el conjunto de campos que toda solicitud de funcionalidad debe tener antes de salir de la plataforma de CS y entrar en el backlog de producto. El pipeline de VoC que alimenta a producto define la estructura previa que genera estos registros. El formato de transferencia funciona mejor cuando el proceso de entrada ya es disciplinado.
El registro de transferencia mínimo viable de 6 campos:
| Campo | Descripción | Por qué importa |
|---|---|---|
| Enunciado de la solicitud de funcionalidad | Una frase clara que describa lo que el cliente necesita (en términos de trabajo, no de solución) | Le da al PM contexto para evaluar sin llamar al CSM |
| Número de cuentas | Número de cuentas distintas que han planteado este problema | Señala patrón frente a caso aislado |
| ARR en juego | ARR total de esas cuentas | Convierte el número de cuentas en peso de negocio |
| Cita textual | Al menos una cita directa de un cliente (palabras exactas, no paráfrasis) | Conecta al PM con el lenguaje real del cliente |
| Solución provisional actual | Lo que las cuentas hacen hoy para compensar | Señala urgencia y riesgo de adopción |
| CSM que la envía | CSM con nombre, localizable si el PM tiene preguntas | Cierra el ciclo para el seguimiento |
Qué NO pertenece al backlog: puntuaciones de salud, fechas de renovación, calificaciones de sentimiento del CSM, puntuaciones de NPS, recuentos de tickets de soporte. Estos son datos internos de CS. Tienen significado en la plataforma de CS donde tienen contexto de cuenta. En Jira, despojados de ese contexto, crean ruido y exposición de privacidad sin mejorar la calidad de decisión del PM.
Notas sobre las plataformas de CS por herramienta
Gainsight tiene las capacidades de integración nativa más maduras entre las principales plataformas de CS. La ruta de CTA a Jira funciona bien cuando las plantillas de CTA están configuradas para requerir los seis campos anteriores antes de que la CTA pueda enviarse. El módulo de Feedback agrega una capa de entrada dedicada, pero requiere disciplina para evitar que se convierta en un cementerio de solicitudes de funcionalidad dentro de Gainsight antes de que algo llegue a Jira. Lo que RevOps suele construir encima: una automatización semanal que exporta la cola de Feedback por encima de un umbral de ARR definido a un CSV formateado que CS Ops revisa antes de canalizar a producto.
ChurnZero se conecta a Jira, Trello y otras herramientas principalmente a través de Zapier o Make, no de una integración nativa. Los PlayBooks pueden activar flujos de trabajo de registro de solicitudes de funcionalidad. Pero la ruta de Zapier requiere un mapeo de campos cuidadoso: la configuración por defecto pasa muy pocos datos estructurados. Los equipos de ChurnZero que ejecutan el Patrón 3 (middleware de CS Ops) obtienen mejor calidad de transferencia que los que dependen de la automatización de Zapier, porque CS Ops aplica el formato mínimo viable antes del envío.
Catalyst y Vitally son plataformas de CS más ligeras que tienen menos opciones de integración nativa. Ambas operan normalmente mediante exportación de CSV o canalización de Slack a Jira en esta etapa de su madurez de producto. Esto no es una limitación para equipos con menos de 100 cuentas. Un mensaje semanal de Slack con un registro de transferencia formateado, canalizado a un canal de Slack de PM dedicado, funciona. Es el Patrón 1 con una capa de entrega por Slack. Para volúmenes de cuentas mayores, los equipos que usan Catalyst o Vitally normalmente ejecutan el Patrón 3.
Las cuatro plataformas de CS comparten una característica arquitectónica: rastrean la retroalimentación a nivel de cuenta, no a nivel de funcionalidad. La traducción de registros a nivel de cuenta a tickets de backlog a nivel de funcionalidad siempre es un paso manual o construido a medida. Ninguna plataforma de CS hoy produce de forma nativa una salida centrada en funcionalidades.
Notas sobre las herramientas de backlog de producto por herramienta
Productboard tiene la capacidad de entrada de CS a producto nativa más fuerte del grupo. El portal de Insights acepta retroalimentación en texto libre con etiquetado de cuentas, y el vínculo de retroalimentación a funcionalidad permite a los PM conectar múltiples aportes de clientes a un único registro de funcionalidad. Para los equipos de CS que pueden dirigir a los CSM a registrar las solicitudes directamente en el portal de Insights de Productboard (en lugar de en la plataforma de CS), esta es la ruta de integración más limpia. Para los equipos donde CS Ops hace la canalización, la API de Productboard admite envíos formateados.
Jira es flexible pero requiere una configuración intencional. Los campos por defecto del ticket de Jira no incluyen ARR, número de cuentas ni cita textual. Estos requieren campos personalizados. Y los campos personalizados solo producen valor si son obligatorios y se mantienen. Una integración de Jira construida sin imponer los requisitos de campos personalizados en el envío se degradará a campos vacíos en un plazo de 90 días a medida que los CSM o las herramientas de automatización dejen de rellenarlos. Jira funciona bien para equipos que invierten en la configuración de campos personalizados por adelantado y hacen que CS Ops imponga el formato mínimo viable.
Linear es minimalista por diseño. Está construido para equipos de ingeniería de rápido movimiento y no tiene una capa de entrada o de agregación de retroalimentación. Usar Linear como destino de producto para la retroalimentación de CS requiere una capa de canalización de CS Ops previa que formatee y agrupe las solicitudes por lotes antes de que entren en Linear. El Patrón 3 (middleware de CS Ops) es casi siempre la elección correcta para los equipos que usan Linear.
Aha! es fuerte en visualización de hoja de ruta y planificación estratégica. La retroalimentación de CS suele entrar en Aha! a través del portal de Ideas (donde los clientes pueden enviar directamente) o vía API desde CS Ops. El portal de Ideas es útil para la recopilación estructurada de retroalimentación pero requiere que los clientes tengan acceso y motivación para enviar. Eso funciona para consejos asesores de clientes enterprise maduros pero menos bien para la retroalimentación cotidiana del mercado medio.
El problema de la taxonomía (y cómo arreglarlo)
El mayor fallo de integración, en todos los patrones y todas las combinaciones de herramientas, es un desajuste de taxonomía entre CS y producto. La investigación Critical Capabilities de Gartner para las plataformas de CS identifica la taxonomía compartida y la canalización de retroalimentación como las dos capacidades que más diferencian a los equipos de CS de alto rendimiento del resto. CS etiqueta una solicitud de funcionalidad como "reportes". Producto tiene una etiqueta de Jira llamada "analítica". Estos son lo mismo. Nunca se vinculan. El patrón a través de 15 cuentas desaparece en la inconsistencia de las etiquetas. Esto está estrechamente relacionado con el problema del reconocimiento de patrones entre CSM, donde el mismo etiquetado desconectado que oculta patrones dentro de un equipo de CS también los oculta en la junta entre CS y producto.
Construir un esquema de etiquetado compartido es un prerrequisito para cualquier patrón de integración por encima del Patrón 1. Es propiedad de CS Ops y de un PM designado, no de las etiquetas por defecto del proveedor de la herramienta.
Cinco categorías cubren el 80% de la retroalimentación de CS en la mayoría de los productos de SaaS de mercado medio:
- Carencia de funcionalidad: el producto no tiene una capacidad que los clientes necesitan
- Fricción de flujo de trabajo: la capacidad existe pero es demasiado difícil de usar en el flujo de trabajo real del cliente
- Integración faltante: los clientes necesitan que el producto se conecte con otra herramienta de su stack
- Rendimiento o fiabilidad: problemas de velocidad, tiempo de actividad o consistencia que afectan los resultados del cliente
- Documentación o formación: los clientes no logran averiguar cómo usar lo que existe
Estas cinco categorías aplican a todas las plataformas de CS y a todas las herramientas de producto. Cuando CS Ops etiqueta cada solicitud entrante con una de estas cinco categorías antes de canalizar, y cuando producto usa las mismas cinco categorías en las etiquetas de su backlog, los datos de patrón sobreviven a la transferencia.
Gobernanza de la taxonomía: CS Ops y un PM designado revisan la taxonomía trimestralmente. Preguntas a evaluar: ¿hay solicitudes apareciendo en "carencia de funcionalidad" que en realidad son "fricción de flujo de trabajo"? ¿Se está usando "documentación o formación" como un cajón de sastre para cosas que en realidad son "fricción de flujo de trabajo"? La taxonomía debería mantenerse estable. Resista agregar nuevas categorías sin eliminar o fusionar las antiguas.
Lógica de canalización: qué activa una transferencia
No todo registro de la plataforma de CS debería llegar al backlog de producto. Los criterios de canalización determinan qué cruza la junta.
Criterios de canalización basados en umbrales (ilustrativos; ajuste a su perfil de ARR):
- Número de cuentas: tres o más cuentas plantearon el mismo problema
- ARR en juego: más de 150.000 USD en ARR combinado
- Severidad: cualquier problema de una sola cuenta donde se señale riesgo de abandono o el cliente lo planteó en una QBR
Los elementos que cumplen cualquiera de estos criterios van al backlog. Los elementos por debajo de los tres se quedan en la plataforma de CS para su supervisión, no para canalización.
Vía urgente frente a vía por lotes. La vía urgente maneja los elementos donde un cliente ha escalado, se ha señalado riesgo de abandono o un ejecutivo de nivel C planteó el problema. Estos se canalizan directamente al PM (mensaje de Slack + ticket formateado) en un plazo de 24 horas. La vía por lotes maneja la cola regular: elementos que cumplen los criterios de umbral pero no han sido escalados. Estos se acumulan semanalmente y se revisan en la cadencia de 1:1 entre CS y PM o se envían como un lote semanal al backlog.
Quién revisa la cola: un enlace de PM designado es el modelo más limpio en el mercado medio. Un PM es dueño de la cola de entrada de retroalimentación de CS y canaliza dentro del equipo de PM. La propiedad rotativa del PM funciona a menor escala pero crea brechas de responsabilidad cuando el PM rotativo está inmerso en un sprint. El filtrado por CS Ops (CS Ops revisa antes de que algo llegue a la cola del PM) funciona mejor en el Patrón 3.
Cierre del ciclo: hacer llegar el estado de vuelta a CS
La vía de retorno (las decisiones del PM fluyendo de vuelta a CS para que los CSM puedan actualizar a los clientes) es más difícil que la vía de entrada, y falla con más frecuencia. La investigación de McKinsey sobre las organizaciones B2B centradas en el cliente muestra que el cambio de mayor impacto que hacen las empresas es construir canales de comunicación bidireccionales: no solo del cliente a producto, sino de producto de vuelta al campo. Cerrar el ciclo de retroalimentación con los clientes requiere una mecánica deliberada del lado de CS. Los patrones de integración aquí cubren la transferencia interna, pero el ciclo de cara al cliente es una disciplina aparte.
La brecha entre lo que "construido" significa para un PM y lo que significa para un CSM que se prepara para una QBR es real. Un PM marca un ticket como "lanzado" cuando la funcionalidad se despliega a producción. El CSM necesita saber: ¿está disponible para todas las cuentas? ¿Está detrás de un feature flag? ¿Requiere migración? ¿Hay documentación? "Lanzado" sin respuestas a estas preguntas no ayuda a un CSM a cerrar el ciclo con el cliente que planteó la solicitud hace ocho meses.
Actualización de estado mínima viable: cuatro estados que CS necesita conocer, comunicados por el PM en el formato acordado:
- En revisión: el PM está evaluando; todavía sin plazo
- En la hoja de ruta: comprometido para un trimestre futuro; indique cuál si es posible
- Rechazado: no está planificado; incluya la razón (fuera de alcance, demasiado pequeño, duplicado de una funcionalidad existente, etc.)
- Lanzado: desplegado; incluya el alcance del despliegue y cualquier acción requerida de la cuenta
El mecanismo de esta vía de retorno depende del patrón de integración. En el Patrón 4 (sincronización bidireccional), la plataforma de CS se actualiza automáticamente cuando el PM actualiza el ticket. En los Patrones 1 a 3, el PM o bien actualiza directamente la plantilla compartida / la plataforma de CS, o CS Ops extrae una actualización de estado semanal de la herramienta de producto y la refleja de vuelta en los registros de cuenta de la plataforma de CS. La revisión trimestral de la retroalimentación del cliente es donde el estado de la cola completa de solicitudes de funcionalidad se revisa a un nivel más alto, pero las actualizaciones de cuentas individuales no pueden esperar a la sesión trimestral.
La auditoría de integración de 30 días
Antes de implementar o cambiar su patrón de integración, documente cómo viaja realmente hoy una sola solicitud de funcionalidad. Recórrala:
Día 1-3: Elija una solicitud de funcionalidad que un CSM haya planteado en los últimos 30 días. Rastréela desde el registro de la plataforma de CS hasta donde esté ahora en la herramienta de producto (o descubra que nunca llegó). Cuente los puntos de transferencia. ¿Quién la tocó? ¿Qué formato tomó en cada paso? ¿Qué se perdió por el camino?
Día 4-7: Entreviste al CSM que la planteó y al PM que (debería haberla) recibido. Pregunte al CSM: ¿sabe qué pasó con esta solicitud? Pregunte al PM: ¿tiene esto en su backlog? Si es así, ¿puede encontrarlo? Si no, ¿a dónde fue?
Día 8-14: Mapee el estado actual en un solo diagrama. Puntos de transferencia, puntos de pérdida de datos, latencia en cada paso. Presente esto al VP CS, al Head of Product y al líder de RevOps.
Día 15-21: Con base en la auditoría, seleccione el patrón (1 a 4) que encaje con la madurez actual de sus herramientas y la capacidad de RevOps. Redacte los campos del registro de transferencia mínimo viable. Proponga la taxonomía compartida (cinco categorías).
Día 22-30: Implemente el Patrón 1 o el Patrón 2, el que sea alcanzable en el tiempo restante. Déjelo funcionar durante el próximo trimestre antes de evaluar si pasar a un patrón más complejo.
La auditoría casi siempre revela que el problema es más simple de lo que parecía. Una taxonomía compartida y un formato mínimo viable arreglan más que cualquier integración técnica. El problema del cementerio de solicitudes de funcionalidad es un problema de flujo de trabajo, no de selección de herramientas. Lo que cierra ese cementerio para siempre es hacer llegar el estado de vuelta a CS para que los CSM puedan cerrar el ciclo con los clientes.
Preguntas frecuentes
¿Qué es el modelo de integración de 4 patrones para el backlog de CS a producto?
El modelo de integración de 4 patrones clasifica las conexiones entre el backlog de CS y producto por nivel de automatización y madurez de RevOps: Patrón 1 (manual con estructura, una plantilla compartida con canalización semanal), Patrón 2 (conector nativo, usando herramientas como la integración de Gainsight con Jira o Zapier), Patrón 3 (middleware propiedad de CS Ops, donde una función humana de canalización aplica criterios basados en umbrales antes de que algo llegue a la cola del PM) y Patrón 4 (sincronización de estado bidireccional, que requiere un ingeniero de datos para mantener la paridad en tiempo real entre ambos sistemas). La mayoría de los equipos de mercado medio operan en el Patrón 1 o 2. El Patrón 3 produce los aportes más limpios al backlog sin requerir recursos de ingeniería.
¿Por qué fallan las integraciones de CS a producto incluso cuando las herramientas están conectadas?
El fallo más común es el desajuste de taxonomía, no el fallo de la herramienta. CS etiqueta una solicitud de funcionalidad como "reportes". Producto tiene una etiqueta de Jira llamada "analítica". El patrón a través de 15 cuentas desaparece en esa inconsistencia de etiquetas. La investigación Critical Capabilities de Gartner para las plataformas de CS identifica la taxonomía compartida y la canalización de retroalimentación como las dos capacidades que más diferencian a los equipos de CS de alto rendimiento. Una taxonomía compartida de cinco categorías (carencia de funcionalidad, fricción de flujo de trabajo, integración faltante, rendimiento o fiabilidad, documentación o formación) resuelve esto antes de configurar cualquier herramienta de integración.
¿Qué seis campos debe incluir todo registro de transferencia de CS a producto?
El registro de transferencia mínimo viable para una solicitud de funcionalidad que cruza de la plataforma de CS al backlog de producto incluye: (1) un enunciado de la solicitud de funcionalidad en términos de trabajo en lugar de términos de solución, (2) el número de cuentas distintas que plantearon el problema, (3) el ARR en juego a través de esas cuentas, (4) al menos una cita textual del cliente en sus palabras exactas, (5) la solución provisional actual que la cuenta está usando hoy, y (6) el nombre del CSM que la envía para el seguimiento. Qué no pertenece al registro de transferencia: puntuaciones de salud, fechas de renovación, calificaciones de sentimiento del CSM o puntuaciones de NPS. Estos llevan significado en la plataforma de CS con contexto de cuenta pero crean ruido cuando se despojan de él en Jira o Productboard.
¿Cómo determina la lógica de canalización qué cruza de CS al backlog de producto?
Los criterios de canalización basados en umbrales definen qué activa una transferencia. Umbrales ilustrativos para un equipo de mercado medio: tres o más cuentas plantearon el mismo problema, 150.000 USD o más en ARR combinado en juego, o cualquier problema de una sola cuenta donde se señale riesgo de abandono o el cliente lo planteó en una QBR. Los elementos que cumplen cualquier criterio van al backlog. Los elementos por debajo de los tres se quedan en la plataforma de CS para su supervisión. Una vía urgente aparte maneja los escalamientos en un plazo de 24 horas: escalamientos de nivel C, cuentas señaladas por abandono o cuentas de alto ARR que sacaron a la luz un problema directamente. La vía por lotes maneja la cola regular revisada en el 1:1 quincenal entre CS y PM.
¿Qué datos no deberían incluirse en el registro de transferencia de CS a producto?
Las puntuaciones de salud, las fechas de renovación, las calificaciones de sentimiento del CSM, las puntuaciones de NPS y los recuentos de tickets de soporte pertenecen a la plataforma de CS donde tienen contexto de cuenta. En un ticket de Jira o Productboard, despojados de ese contexto, agregan ruido sin mejorar la calidad de decisión del PM. También crean un riesgo de exposición de privacidad cuando los datos de sentimiento a nivel de cuenta están en una herramienta de producto a la que accede un equipo más amplio de ingeniería y diseño. El registro de transferencia debería contener solo la información que un PM necesita para evaluar la solicitud, canalizarla y localizar al CSM que la envía para aclaraciones.
¿Cómo funciona la sincronización de estado bidireccional, y quién la necesita?
La sincronización bidireccional mantiene la plataforma de CS y la herramienta de backlog de producto de acuerdo en tiempo real: cuando un PM actualiza el estado de un ticket (en revisión, en la hoja de ruta, rechazado, lanzado), el registro de cuenta correspondiente de la plataforma de CS se actualiza automáticamente. Cuando un CSM registra una nueva solicitud de funcionalidad, crea automáticamente un ticket en la herramienta de producto. Este es el Patrón 4: el estándar de oro y el más raro en el mercado medio. Requiere un recurso de ingeniería de datos para construir y mantener la sincronización, además de estabilidad de la API de ambas herramientas. La mayoría de los equipos de mercado medio logran el mismo resultado operativamente a través del Patrón 3 (middleware de CS Ops) combinado con una actualización de estado semanal del PM a CS Ops, lo que lleva más tiempo humano pero cero mantenimiento de ingeniería.
Más información
- El pipeline de VoC: cómo CS alimenta a Producto
- Captura sistemática de retroalimentación: de las notas del CSM al backlog
- La cadencia de 1:1 entre CS y PM
- Revisión trimestral de la retroalimentación del cliente (conjunta)
- El problema del cementerio de solicitudes de funcionalidad
- Stack alineado: CRM, plataforma de CS e inteligencia de ingresos
- Arquitectura del registro compartido del cliente

Senior Operations & Growth Strategist
On this page
- Por qué esta integración es más difícil de lo que parece
- Los cuatro patrones de integración (neutrales respecto a proveedores)
- Qué datos deberían cruzar realmente la junta
- Notas sobre las plataformas de CS por herramienta
- Notas sobre las herramientas de backlog de producto por herramienta
- El problema de la taxonomía (y cómo arreglarlo)
- Lógica de canalización: qué activa una transferencia
- Cierre del ciclo: hacer llegar el estado de vuelta a CS
- La auditoría de integración de 30 días
- Preguntas frecuentes
- ¿Qué es el modelo de integración de 4 patrones para el backlog de CS a producto?
- ¿Por qué fallan las integraciones de CS a producto incluso cuando las herramientas están conectadas?
- ¿Qué seis campos debe incluir todo registro de transferencia de CS a producto?
- ¿Cómo determina la lógica de canalización qué cruza de CS al backlog de producto?
- ¿Qué datos no deberían incluirse en el registro de transferencia de CS a producto?
- ¿Cómo funciona la sincronización de estado bidireccional, y quién la necesita?
- Más información