More in
AI at Work ニュース
OpenAIがChatGPT広告を中小企業に予算制限なく開放した
6月 6, 2026
AIは職場のあらゆる場所に浸透した:しかし「仕事を根本から変えた」と言える人は10人に1人だけ
6月 6, 2026
Vibe Codingの105億ドルの瞬間:AIが新規ソフトウェア開発の大半を担うようになった
6月 6, 2026
AIエージェントは今や従業員よりも多くのシステムアクセス権を持っている:しかしセキュリティ対策はほとんど追いついていない
6月 5, 2026
AIは自社開発すべきか、購入すべきか。巨大企業が何を買収したかを見れば答えが見えてくる
6月 5, 2026
Uberは予算超過を受け、従業員1人あたりのAI利用上限を1,500ドルに設定した
6月 5, 2026
TrumpのAI大統領令は規制緩和を志向:しかし御社のコンプライアンスリスクは変わっていない
6月 4, 2026
AIが220社のユニコーン企業を時価総額10億ドル未満に押し下げた:ChatGPT以前のスタートアップは転換点を迎えている
6月 4, 2026
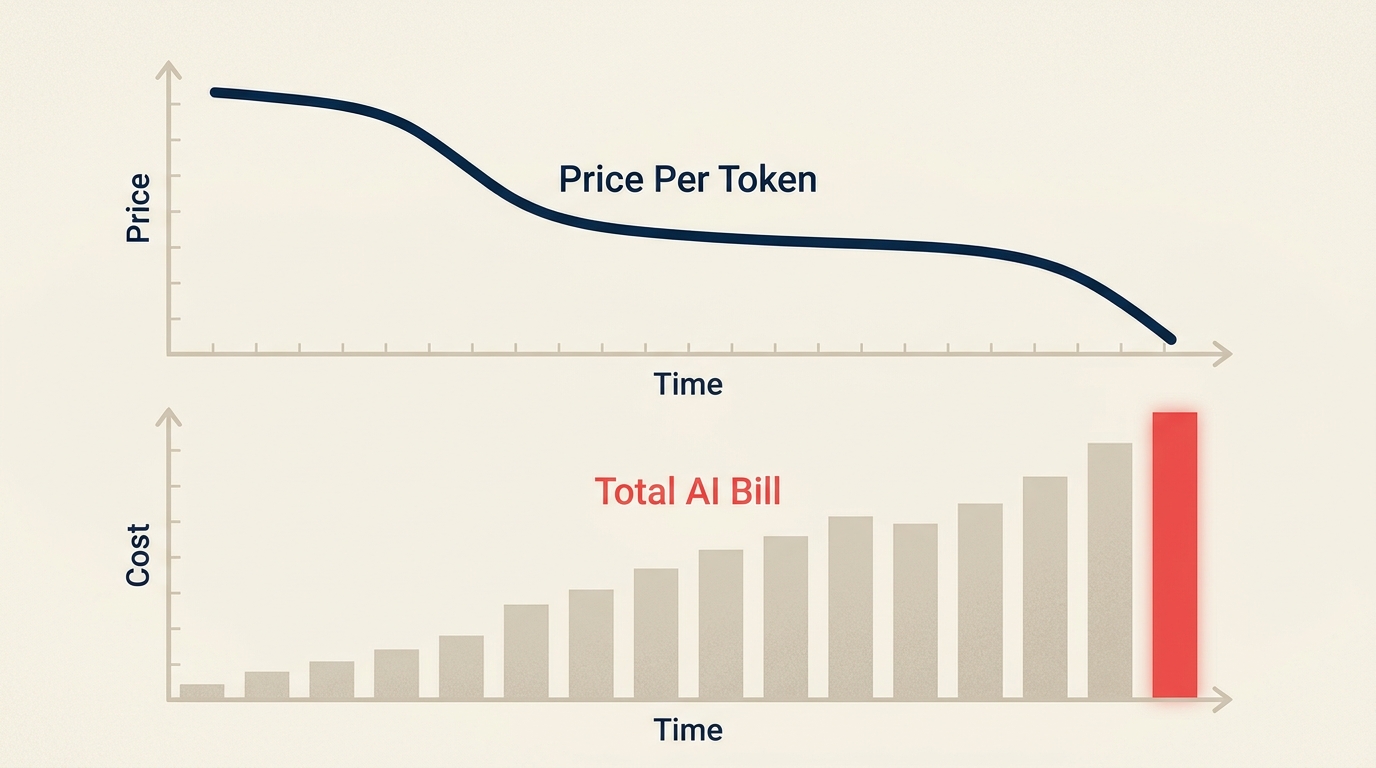
トークン価格は今年67%下落した:それでもAI費用は増え続けている
6月 3, 2026 · Currently reading
AIを活用する中小企業は売上増加と勤務時間短縮を同時に実現している
6月 3, 2026
今年トークン価格は67%下落。それでも企業のAI請求額は増加しています
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
ベンダーはより低い価格を提示しています。経理部門はAIの費用項目が拡大していると警告しています。どちらも正しいのです。
これは矛盾ではありません。2026年における企業AIの典型的なコストの落とし穴であり、ほとんどのCEOはまだこれに対応するフレームワークを持っていません。
2026年5月22日にFortuneが公開した分析によれば、エージェント型AI(人工知能)ワークフローへのシフトにより、AI推論の単価が下がり続ける一方で、企業の総支出は急増しています。問題はトークンあたりの価格ではありません。現代のAIワークロードが消費するトークンの量にあります。
ジェヴォンズのパラドックスがAI予算を支配している

経済学者はこのパターンに名前をつけています。ジェヴォンズのパラドックスとは、ある資源が安くなると、価格の下落以上に消費量が増える傾向があるというものです。コストが下がることで、それまで採算が合わなかった新たなユースケースが開拓されるためです。石炭、電力、帯域幅、そして今やトークンも同様です。
2026年の業界コスト分析に基づくと、AI推論の混合コストは2025年第1四半期から2026年第1四半期にかけて前年比で約67%下落し、100万トークンあたり約18.40ドルから6.07ドルへと下がりました。これは実質的かつ劇的な価格下落です。
しかし、2026年に73%の企業が実際のAIコストが当初の見込みを超えたと報告しました。このギャップは予算策定の誤りではありません。ジェヴォンズのパラドックスの実例です。AIが安くなったことで、企業はより多くの場所により多くのAIを展開し、より複雑なワークロードを実行するようになりました。
重要なポイント
- トークン価格は前年比で約67%下落しました(2025年Q1から2026年Q1にかけて100万トークンあたり約18.40ドルから6.07ドルへ)。(2026年業界コスト分析)
- 2026年に73%の企業がAI支出が当初の見込みを超えたと報告しました。(2026年コスト分析)
- Goldman Sachsの分析では、エージェント型AIによってトークン総需要が最大24倍に増加する可能性があると予測しています。(Tom's Hardware、Goldman Sachsを引用)
エージェント型AIが予算を突き破る理由
チャットボットが質問に答えたり、モデルがドキュメントを要約したりするシンプルなAIユースケースでは、トークンの消費は1回のやりとりで完結します。プロンプトを1回入力し、1回の応答を受け取る。そのコストはスプレッドシートでモデル化できます。
エージェント型ワークロードはそのようには機能しません。エージェントが独自にタスクを完了しようとすると、ユーザーの1アクションあたり10〜20回のモデル呼び出しが発生します。ワークフローの各ステップが個別の推論呼び出しとなります。モデルが正確に答えるために関連ドキュメントを参照するRAG(検索拡張生成)は、コンテキストウィンドウを3〜5倍に膨らませます。常時稼働の監視エージェントは、人間が確認していなくても24時間継続してトークンを生成し続けます。
この複合効果は大きなものです。「1つのタスク」のように見える1つのエージェント型ワークフローが、基本的なシングルコールモデルで同じ処理を行う場合と比べて、50倍ものトークンを消費することがあります。
Tom's HardwareがGoldman Sachsの分析として報告した内容は、この状況を数値化しています。エージェント型AIは、現在の消費量と比べて企業のトークン総需要を最大24倍増加させる可能性があるとのことです。これは遠い未来の予測ではありません。Uberのような企業がすでにこれを経験しています。
UberのCTO(最高技術責任者)は、同社が2026年のAI予算を4ヶ月で使い切ったことを明らかにしました。Anthropicのコーディングアシスタントである Claude Codeの社内利用率は、約5,000人のエンジニアのうち32%から84%へと急増しました。Fortune及びTom's Hardwareの報道によれば、エンジニア1人あたりの月間コストは500ドルから2,000ドルかかっています。その普及率で、あれだけの規模のエンジニアチームに適用すれば、支出はすぐに積み上がります。
さらにFortuneが報じたように、Microsoftは一部のワークロードにおいて、AIの処理コストが同じタスクを行う人件費を超えていることを認めています。
GitHubが課金モデルを変更。他社も追随するでしょう
このコストの現実は、AIベンダーが契約を組み立てる方法をすでに変えています。
2026年6月1日、GitHubはCopilotの課金をフラットレートのサブスクリプションから、トークン消費に直接連動した「GitHub AI Credits」を使用した利用量ベースのモデルへと移行しました。Microsoftも同期間中に、より広範なCopilotスイートを同様のクレジットベース構造へ移行しようとしています。
これは次回のベンダー交渉において重要な意味を持ちます。AIの予算管理を予測可能なSaaSの費用のように感じさせていたフラットシート方式は終わりを迎えつつあります。従量制の公共料金的な領域へと移行しており、請求額は人数ではなく利用量に応じてスケールします。
AIのガバナンスモデルについては、エージェント型AIとガバナンスのギャップでより詳しく取り上げていますが、それらは従量制の消費を前提として設計されていません。ほとんどの企業はまだワークフロー単位のコスト可視化を実現できていません。
対応策
トークンの低価格化は、正しく活用すれば真の優位性をもたらします。しかし、そのためにはAIインフラをクラウドコンピューティングと同様に扱う必要があります。フラットレートのシートライセンスではなく、ワークフローレベルでコスト管理が行われる従量制の公共インフラとして扱うということです。
実践的な出発点となるフレームワークを紹介します。
スケールアップ前に、ワークフロー単位のトークンコストを計測してください。 計測できないものは最適化できません。エージェント型ワークフローを全社展開する前に、タスク完了あたりの実際のコストを計測します。それを人件費の代替と比較します。10倍のコスト優位性を示すワークフローもあれば、その逆もあります。
エージェントの予算と guardrails を設定してください。 デプロイされた各エージェントには、タスクあたりの最大トークン予算を設けるべきです。エージェントがそれを超えた場合、タスクは人間にエスカレーションされるか、より低コストのモデルにフォールバックするべきです。これはクラウドコスト管理では標準的な手法であり、AI管理でも標準化されるべきです。
エージェント型支出が正当化されるワークフローを判断してください。 すべてのタスクに多段階の自律エージェントが必要なわけではありません。シンプルな分類や要約のタスクは、はるかに低コストのシングルコールモデルで対応できます。CTO向けNvidiaのNemotron分析で探求しているように、低リスクの推論にはより安価なオープンウェイトモデルがますます有力な選択肢となっています。ワークフローの複雑さに合ったモデルを選んでください。
利用データを持参して更新交渉に臨んでください。 ベンダーがクレジットベースの課金に移行している場合、現在のフラットレート期間の実際の消費データが交渉の基準値となります。新しい料金体系に合意する前に、自社の実際の利用量を把握しておいてください。
AIをソフトウェアライセンスではなく公共料金として扱ってください。 電力会社は月額固定料金で「無制限の電力」を販売しません。エージェント型AIの普及が完全に成熟すれば、AIベンダーも同様になります。課金モデルが変わる前に、消費量ベースの会計を前提とした社内のガバナンスと財務プロセスを構築してください。
BCG AI Radar 2026の調査結果によれば、90%のCEOが今年エージェント型AIからROIが得られると期待しています。これはほとんどの組織がこの技術に大きく賭けていることを示しています。しかし、フラットレート価格を前提としたROI計算は誤りとなります。コスト構造が変わりました。戦略もそれに追いつく必要があります。
AIベンダーとの関係がどのように変化しているかについての広い視点は、AnthropicのIPO申請に基づくベンダー選定の分析で、AIが基盤インフラ投資となることの戦略的含意を取り上げています。
エージェントコスト監査のための3つの問い
エージェント型ワークフローを大規模に展開する前に、次の3つの問いを検討してください。
- 100回の実際の稼働(デモではなく)にわたって計測した、タスク完了あたりのトークンコストはいくらか?
- そのコストは現在の規模で、また10倍の規模においても、人件費の代替を上回るか?
- エージェントが想定外の動作をしたり、タスクの範囲が拡大したりした場合に、コストを制限するguardrailは何か?
3つすべてに答えられなければ、そのワークフローは大規模な本番環境への展開準備ができていません。
よくある質問
トークン価格が下落しているのに、なぜAI請求額が上がるのですか?
現代のAIワークロードは、ほとんどの予算モデルが前提としていたシンプルなチャットアプリケーションよりもはるかに多くのトークンを消費するためです。エージェント型ワークフローはユーザーの1タスクあたり10〜20回のモデル呼び出しを発生させ、RAGはコンテキストウィンドウを3〜5倍に拡大します。トークンあたりの価格は低くなっていますが、消費量は劇的に増加しています。単価が下がっても総支出は増加する、これがAIインフラに適用されたジェヴォンズのパラドックスです。
次回のAIベンダー更新前に何をすべきですか?
現在のフラットレート期間における実際のワークフロー単位のトークン消費データを収集してください。ベンダーがクレジットベースの課金に移行するにつれて、そのデータが交渉の基準値となります。新しい料金体系に合意する前に、自社の実際の利用量を把握しておいてください。
エージェント型のトークン支出に見合わないAIワークロードはどれですか?
推論チェーンの恩恵を受けないシングルステップのタスクが該当します。ドキュメントの分類、基本的な要約、エンティティ抽出、センチメントスコアリングなどです。これらはより安価なシングルコールモデルやオープンウェイトの代替モデルで対応できます。多段階エージェントへの支出は、自律推論が実際にアウトプットの質を変えるワークフロー、例えば複雑な分析、複数ソースのリサーチ、または連続的な意思決定が必要なタスクに絞ってください。
出典: Fortune, 2026年5月22日 | Tom's Hardware | Duperrin, 2026年6月1日

Co-Founder, Rework.com