Was ist AI Observability? Der Unterschied zwischen der Hoffnung, dass KI funktioniert, und dem Wissen, dass sie es tut
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ein Fortune-500-Unternehmen setzte eine KI-gestützte Pricing Engine ein. Sie funktionierte einwandfrei beim Testen. Drei Wochen nach dem Launch begann sie, bei nächtlichen Batch-Läufen für eine bestimmte Produktkategorie subtil falsche Preise zurückzugeben. Kein Alert wurde ausgelöst. Kein Fehler erschien in den Logs. Das Team entdeckte das Problem sechs Wochen später, als ein Vertriebsmitarbeiter ungewöhnliche Rabatte bemerkte.
Das Problem war nicht das Modell. Es war, dass niemand sehen konnte, was das Modell tat.
AI Observability ist die Praxis, KI-Systeme in der Produktion so aufzubauen, dass man ihren internen Zustand aus ihren externen Ausgaben verstehen kann. Es ist dieselbe Disziplin, die Site Reliability Engineering der Software-Infrastruktur gebracht hat.
Wie sich AI Observability von Model Monitoring unterscheidet
Diese beiden Begriffe werden austauschbar verwendet, bezeichnen aber nicht dasselbe.
Model Monitoring verfolgt Metriken auf Modellebene: Genauigkeit, Prediction Drift, Verschiebungen der Datenverteilung und Output-Qualität im Laufe der Zeit. Es beantwortet die Frage: "Funktioniert dieses Modell noch wie erwartet?"
AI Observability ist umfassender. Sie deckt den gesamten KI-System-Stack ab: das Modell selbst, die Datenpipelines, die es speisen, die Infrastruktur, auf der es läuft, die ein- und ausgehenden API-Aufrufe, die Latenz auf jeder Ebene und die nachgelagerten Geschäftsergebnisse. Sie beantwortet die Frage: "Was tut mein KI-System tatsächlich, und kann ich jedes Problem auf seine Ursache zurückführen?"
Stellen Sie sich Monitoring als das Messen des Blutdrucks eines Patienten vor. Observability ist das vollständige Krankenblatt mit Verlauf, Kontext, Diagnosenotizen und einer Aufzeichnung jeder Behandlungsentscheidung.
Für Führungskräfte: Model Monitoring sagt Ihnen, dass eine Metrik schlecht ist. Observability sagt Ihnen warum.
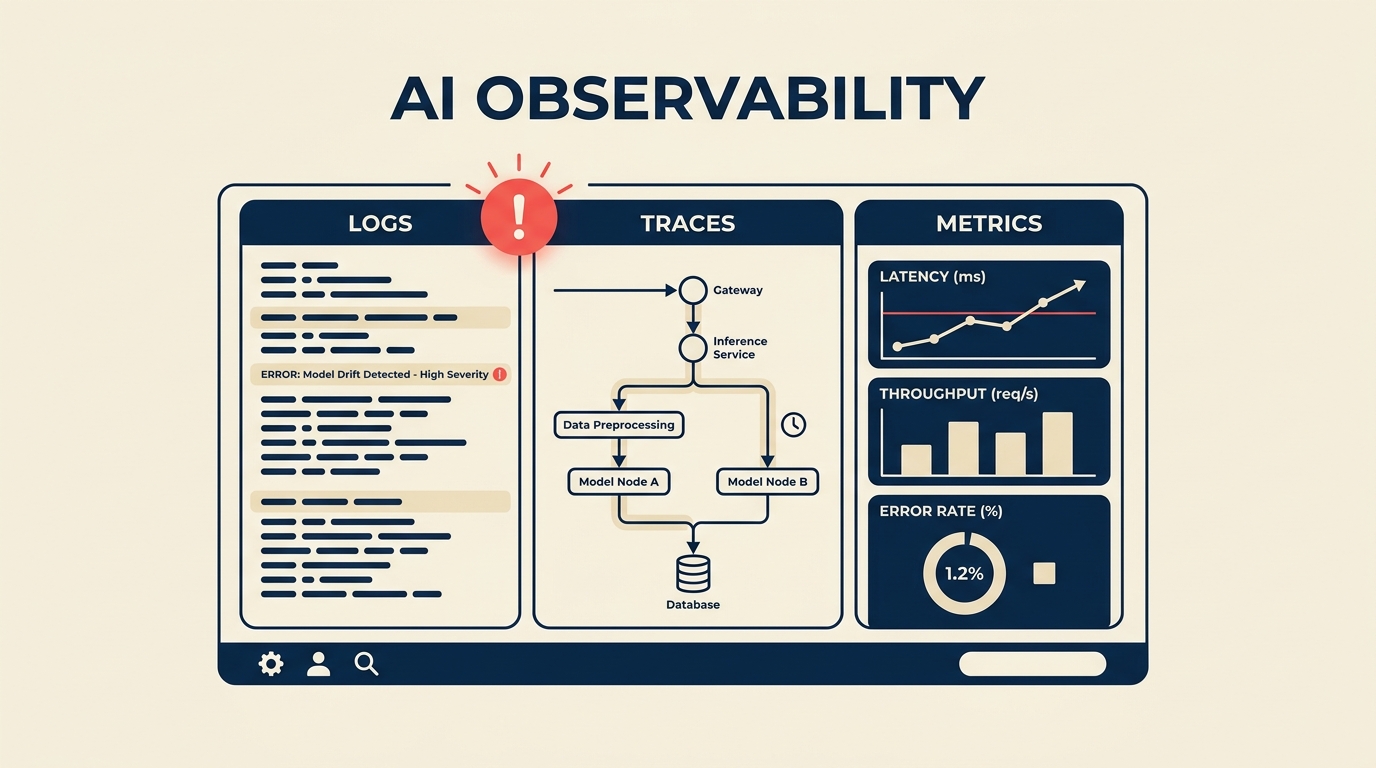
Die drei Säulen
Observability in der Software-Entwicklung beruht auf drei Signalen. KI-Systeme nutzen alle drei, mit KI-spezifischen Ergänzungen zu jedem:
Logs erfassen diskrete Ereignisse: ein empfangener Prompt, eine generierte Antwort, ein ausgeführter Tool-Aufruf, eine ausgeführte Retrievalabfrage. In KI-Systemen müssen Logs nicht nur Fehler, sondern auch erfolgreiche Interaktionen mit ausreichend Kontext erfassen, um das Geschehene zu rekonstruieren. Ein Log-Eintrag, der besagt "Modell antwortete in 240ms", ist weit weniger nützlich als einer, der den Prompt, die Modellversion, die Anzahl der Tokens und die abgerufenen Kontext-Chunks enthält.
Metriken sind numerische Messungen über die Zeit: Request Rate, Error Rate, Latenz-Perzentile, Token-Verbrauch, Kosten pro Request und modellspezifische Maße wie die Verteilung der Output-Länge oder die Ablehnungsrate. Gute KI-Metriken verbinden technisches Verhalten mit Geschäftsergebnissen, sodass die Kosten pro Request den Kosten pro erfolgreicher Kundeninteraktion entsprechen.
Traces zeigen den vollständigen Weg eines einzelnen Requests durch ein System. Bei agentischen Workflows und RAG-Pipelines kann eine einzelne Benutzerinteraktion fünf Retrieval-Aufrufe, drei LLM-Aufrufe, zwei Tool-Ausführungen und einen Datenbankschreibvorgang umfassen. Ein Trace verfolgt die gesamte Kette mit Timing-Daten an jedem Schritt, sodass Sie identifizieren können, woher die Latenz kommt oder wo ein Fehler entstanden ist.
KI-Systeme fügen ein viertes Signal hinzu, das traditionelle Software nicht hat:
Evaluierungen sind systematische Qualitätsbewertungen von KI-Outputs. Da KI-Outputs probabilistisch und oft subjektiv sind, können Sie nicht einfach auf Fehlercodes prüfen. Evaluierungen leiten Stichproben von Produktions-Outputs durch Qualitäts-Scorer, menschliche Bewerter oder Referenz-LLMs, um Dimensionen wie Faktizität, Ton, Relevanz oder Aufgabenerledigung zu messen. So erkennt man, wenn "das Modell technisch funktioniert, aber schlechtere Outputs als letzten Monat produziert."
Wie gute AI Observability in der Praxis aussieht
Ein gut beobachtetes KI-System ermöglicht einem Ingenieur, diese Fragen innerhalb von Minuten statt Tagen zu beantworten:
"Wir haben gestern um 15 Uhr einen Anstieg an Benutzerbeschwerden gesehen. Was hat sich geändert?" Mit Observability können Sie den Beschwerdeanstieg mit einem Deployment, einer Änderung der Retrieval-Qualität, einer Verschiebung in den Nutzeranfrage-Mustern oder einem vorgelagerten Datenqualitätsproblem korrelieren.
"Warum ist diese spezifische Kundeninteraktion schiefgelaufen?" Mit Traces können Sie die genaue Abfolge der Aufrufe nachspielen, sehen, welchen Kontext das Modell erhalten hat, und feststellen, ob der Fehler im Retrieval, im Reasoning des Modells oder in einem nachgelagerten Tool-Aufruf lag.
"Wird unsere KI teurer, ohne besser zu werden?" Mit gleichzeitig verfolgten Kosten- und Qualitätsmetriken können Sie erkennen, wenn der Token-Verbrauch steigt, aber die Output-Qualitätswerte stagnieren, was häufig auf Prompt Bloat oder Retrieval-Ineffizienz hindeutet.
"Funktioniert unser komprimiertes Modell genauso wie das vollständige Modell?" Observability ermöglicht Ihnen, A/B-Vergleiche zwischen Modellversionen in der Produktion mit statistischer Genauigkeit durchzuführen, anstatt sich auf Offline-Benchmarks zu verlassen.
Der Business Case für Investitionen
AI Observability-Infrastruktur kostet echtes Geld. Teams scheuen die Investition, wenn das Entwickeln von Features dringlicher erscheint. Der Business Case ergibt sich aus drei Realitäten:
Erstens sind KI-Fehler oft lautlos. Im Gegensatz zu einem abgestürzten Server, der 500-Fehler auslöst, arbeitet ein fehlkalibriertes Modell weiter, während es subtil falsche Outputs produziert. Ohne Observability erfährt man von KI-Qualitätsproblemen durch Kundenbeschwerden oder nachgelagerte Geschäftsmetriken, Wochen nachdem die Degradierung begann.
Zweitens ist Debugging ohne Observability unzumutbar langsam. Wenn ein unbeobachtetes KI-System sich falsch verhält, kann die Untersuchung Wochen dauern. Die genauen Bedingungen zu reproduzieren, zu verfolgen, welche Komponente versagt hat, und die Ursache ohne Instrumentierung zu identifizieren, erfordert oft, den Kontext von Grund auf neu aufzubauen.
Drittens sind KI-Kosten variabel und können unerwartet steigen. Eine Prompt-Engineering-Änderung, die die durchschnittliche Token-Anzahl um 30% erhöht, erscheint möglicherweise nicht in Unit-Tests, verdoppelt aber Ihre monatliche Inferenzrechnung. Cost Observability erkennt solche Änderungen innerhalb von Stunden, nicht Abrechnungszyklen.
MLOps-Plattformen bündeln zunehmend Observability-Tools, sodass Teams nicht alles von Grund auf aufbauen müssen. Speziell entwickelte Tools wie LangSmith, Arize AI und Weights and Biases bieten Observability, die speziell für LLM- und ML-Workloads entwickelt wurde.
Der Einstieg ohne alles neu aufzubauen
Organisationen, die bei null anfangen, benötigen am ersten Tag keinen umfassenden Observability-Stack. Ein praktischer Fortschritt:
Beginnen Sie mit strukturiertem Logging für jeden KI-API-Aufruf: Zeitstempel, Modellversion, Input-Token-Anzahl, Output-Token-Anzahl, Latenz und eine eindeutige Trace-ID. Das allein ermöglicht retroaktives Debugging und Cost Tracking.
Fügen Sie Output-Sampling und menschliche Evaluierung für Ihre wertvollsten oder risikoreichsten KI-Workflows hinzu. Selbst die wöchentliche manuelle Überprüfung von 50 Interaktionen zeigt Qualitätstrends auf, bevor sie zur Krise werden.
Fügen Sie Distributed Tracing hinzu, sobald Sie mehrstufige KI-Workflows haben, bei denen Sie den vollständigen Request-Pfad verstehen müssen.
Ergänzen Sie automatisierte Evaluierungsmetriken, nachdem Sie genügend menschlich überprüfte Stichproben haben, um automatisierte Scorer dagegen zu kalibrieren.
Das Ziel ist keine perfekte Observability. Es ist ausreichende Sichtbarkeit, damit Probleme sichtbar werden, bevor Kunden sie bemerken.
Verwandte KI-Konzepte
- Model Monitoring - Verfolgung der Modellleistung im Laufe der Zeit in der Produktion
- MLOps - Die umfassendere Disziplin des zuverlässigen Betriebs von KI-Systemen
- AI Governance - Frameworks für Verantwortlichkeit in KI-Systemen
- Agentische Workflows - Mehrstufige KI-Systeme, bei denen Tracing besonders kritisch ist
- Retrieval-Augmented Generation - RAG-Pipelines, die von Observability über Retrieval- und Generierungsphasen profitieren
- AI Audit Trail - Das compliance-orientierte Gegenstück zu Observability
Externe Ressourcen
- OpenTelemetry - Offener Standard für Distributed Tracing und Metriken, zunehmend für KI-Systeme übernommen
- Arize AI - Speziell entwickelte ML Observability-Plattform
- LangSmith - Observability und Evaluierungstools für LLM-Anwendungen
FAQ
Häufig gestellte Fragen zu AI Observability
Was ist AI Observability?
AI Observability ist die Praxis, KI-Systeme mit ausreichender Instrumentierung (Logs, Metriken, Traces und Evaluierungen) aufzubauen, sodass man ihren internen Zustand und ihr Verhalten aus ihren Outputs verstehen kann. Sie ermöglicht es Teams, Probleme zu erkennen, Fehler zu debuggen und die Qualität in KI-Systemen in der Produktion zu verfolgen.
Wie unterscheidet sich AI Observability von Model Monitoring?
Model Monitoring verfolgt Metriken auf Modellebene wie Genauigkeit und Drift. AI Observability deckt den gesamten System-Stack ab: Datenpipelines, Infrastruktur, API-Aufrufe, Latenz, Kosten und Output-Qualität. Monitoring sagt Ihnen, dass etwas nicht stimmt. Observability sagt Ihnen, warum und wo.
Was sollte jedes KI-System mindestens loggen?
Mindestens: Zeitstempel, Modellversion, Input- und Output-Token-Anzahl, Latenz, eindeutige Trace-ID und eventuelle Fehlerzustände. Für LLM-Anwendungen auch die System-Prompt-Version und den abgerufenen Kontext, wenn Sie RAG verwenden. Diese Baseline ermöglicht Cost Tracking und retroaktives Debugging.
Benötigt man spezialisierte Tools für AI Observability?
Nicht unbedingt. Man kann mit strukturiertem Logging in jedem vorhandenen Log-Management-System beginnen. Spezialisierte Tools wie LangSmith, Arize oder Weights and Biases bieten Mehrwert für Teams, die KI im großen Maßstab betreiben, insbesondere für LLM-Evaluierung und mehrstufiges Agent-Tracing.
